







 本文介绍了NLP中Attention机制和Seq2Seq模型。Attention机制本质是为实现编解码对齐,在解码时根据前一时刻状态获取编码状态权重并加权求和。Seq2Seq模型通过编码输入与解码输出将输入序列映射为输出序列,应用于机器翻译、聊天机器人等场景,还提及了相关预处理工作。
本文介绍了NLP中Attention机制和Seq2Seq模型。Attention机制本质是为实现编解码对齐,在解码时根据前一时刻状态获取编码状态权重并加权求和。Seq2Seq模型通过编码输入与解码输出将输入序列映射为输出序列,应用于机器翻译、聊天机器人等场景,还提及了相关预处理工作。
https://zhuanlan.zhihu.com/p/37601161
那么,在NLP中,Attention机制是什么呢?从直觉上来说,与人类的注意力分配过程类似,就是在信息处理过程中,对不同的内容分配不同的注意力权重。
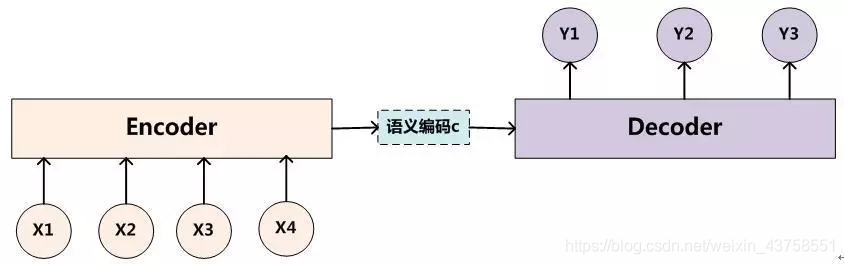
如上图所示,是标准的编解码(seq2seq)机制的结构图,在机器翻译、生成式聊天机器人、文本摘要等任务中均有应用。其处理流程是通过编码器对输入序列进行编码,生成一个中间的语义编码向量C,然后在解码器中,对语义编码向量C进行解码,得到想要的输出。例如,在中英文翻译的任务中,编码器的输入是中文序列,解码器的输出就是翻译出来的英文序列。
可以看出,这个结构很"干净",对于解码器来说,在解码出y1,y2,y3时,语义编码向量均是固定的。我们来分析下这样是否合理。
假设输入的是"小明/喜欢/小红",则翻译结果应该是"XiaoMing likes XiaoHong"。根据上述架构,在解码得到"XiaoMing",“likes”," XiaoHong"时,引入的语义编码向量是相同的,也就是"小明",“喜欢”,“小红"在翻译时对得到"XiaoMing”,“likes”," XiaoHong"的作用是相同的。这显然不合理,在解码得到"XiaoMing"时,"小明"的作用应该最大才对。
鉴于此,机智的NLP研究者们,认为应该在编解码器之间加入一种对齐机制,也就是在解码"XiaoMing"时应该对齐到"小明"。在《Neural Machine Translation By Jointly Learning To Align And Translate》中首次将这种对齐机制引入到机器翻译中。我们来看看,这是怎样的一种对齐机制。
我们先回顾一下刚才的编解码结构,其语义编码向量和解码器状态,通过如下的公式得到:
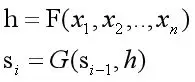
通常在解码时语义编码向量是固定的。若要实现对齐机制,在解码时语义编码向量应该随着输入动态的变化。鉴于此,《Neural Machine Translation By Jointly Learning To Align And Translate》提出来一种对齐机制,也就是Attention机制。
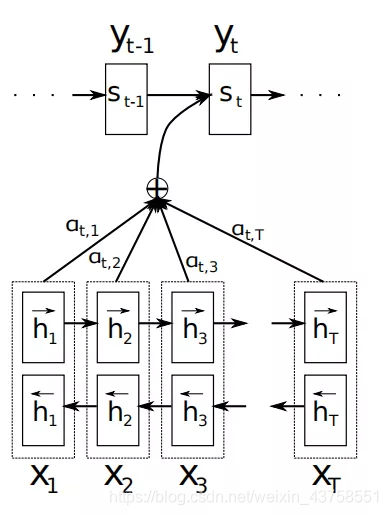
如上图示,论文中采用双向RNN来进行语义的编码,这不是重点,我们先不关注。其对齐机制整体思想是:编码时,记下来每一个时刻的RNN编码输出(h1,h2,h3,…hn);解码时,根据前一时刻的解码状态,即yi-1,计算出来一组权重(a1,a2,…an),这组权重决定了在当前的解码时刻,(h1,h2,h3,…hn)分别对解码的贡献。这样就实现了,编解码的对齐。

得到权重向量ai及语义编码向量Ci后,就可以计算当前时刻的解码状态了:
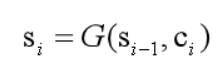
这就是编解码机制中注意力机制的基本内容了,本质上就是为了实现编解码之间的对齐,在解码时根据前一时刻的解码状态,获取不同时刻编码状态的权重值并加权求和,进而获得该时刻语义编码向量。
有没有attention 区别

那么,抽离编解码机制,Attention机制的本质是什么呢?我们下面来看看。
3 Attention机制的本质
我们回想一下,引入Attention机制的本意,是为了在信息处理的时候,恰当的分配好”注意力“资源。那么,要分配好注意力资源,就需要给每个资源以不同的权重,Attention机制就是计算权重的过程。
如下图所示,
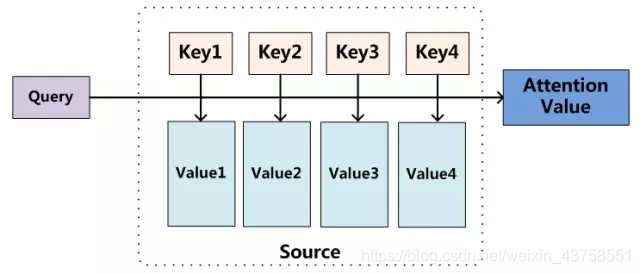
图9
如上图所示,我们由资源Value,需要根据当前系统的其他状态Key和Querry来计算权重用以分配资源Value。
也就是,可以用如下的数学公式来描述Attention机制:
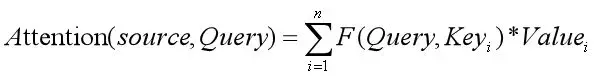
F函数可以有很多,在transformer中用的是点积。
总结
Transformer中最重要的特点就是引入了Attention,其对于Transformer性能的重要性我们下一篇介绍。总的来说,Adttention机制是一种对齐机制,它通过对系统当前的某些状态进行评估,来对系统资源进行权重分配,实现对齐,具体可以看机器翻译的例子。
我们可以这样来看待Attention机制(参考图9):将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。即可以将其本质思想改写为如下公式:
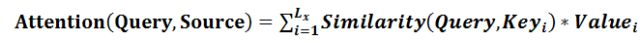
其中,Lx=||Source||代表Source的长度,公式含义即如上所述。上文所举的机器翻译的例子里,因为在计算Attention的过程中,Source中的Key和Value合二为一,指向的是同一个东西,也即输入句子中每个单词对应的语义编码,所以可能不容易看出这种能够体现本质思想的结构。
当然,从概念上理解,把Attention仍然理解为从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略大多不重要的信息,这种思路仍然成立。聚焦的过程体现在权重系数的计算上,权重越大越聚焦于其对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。
从图9可以引出另外一种理解,也可以将Attention机制看作一种软寻址(Soft
Addressing):Source可以看作存储器内存储的内容,元素由地址Key和值Value组成,当前有个Key=Query的查询,目的是取出存储器中对应的Value值,即Attention数值。通过Query和存储器内元素Key的地址进行相似性比较来寻址,之所以说是软寻址,指的不像一般寻址只从存储内容里面找出一条内容,而是可能从每个Key地址都会取出内容,取出内容的重要性根据Query和Key的相似性来决定,之后对Value进行加权求和,这样就可以取出最终的Value值,也即Attention值。所以不少研究人员将Attention机制看作软寻址的一种特例,这也是非常有道理的。
至于Attention机制的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理;这样,可以将Attention的计算过程抽象为如图10展示的三个阶段。
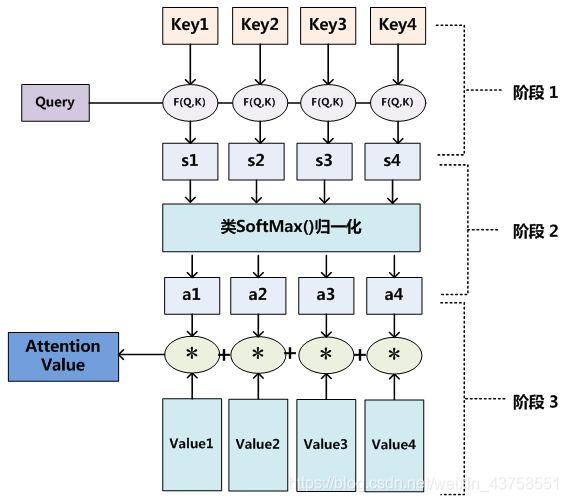
图10
在第一个阶段,可以引入不同的函数和计算机制,根据Query和某个Key_i,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性或者通过再引入额外的神经网络来求值,即如下方式:

第一阶段产生的分值根据具体产生的方法不同其数值取值范围也不一样,第二阶段引入类似SoftMax的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。即一般采用如下公式计算:
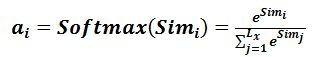
第二阶段的计算结果a_i即为value_i对应的权重系数,然后进行加权求和即可得到Attention数值:

通过如上三个阶段的计算,即可求出针对Query的Attention数值,目前绝大多数具体的注意力机制计算方法都符合上述的三阶段抽象计算过程。
https://samaelchen.github.io/deep_learning_step6/
https://www.zhihu.com/question/68482809/answer/264632289
https://blog.youkuaiyun.com/hpulfc/article/details/80448570
attention
https://mp.weixin.qq.com/s/0k71fKKv2SRLv9M6BjDo4w
图解说明
https://blog.youkuaiyun.com/qq_32241189/article/details/81591456
https://www.jianshu.com/p/b2b95f945a98
Seq2Seq模型是RNN最重要的一个变种:N vs M(输入与输出序列长度不同)。
这种结构又叫Encoder-Decoder模型。
原始的N vs N RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。
为此,Encoder-Decoder结构先将输入数据编码成一个上下文向量c:
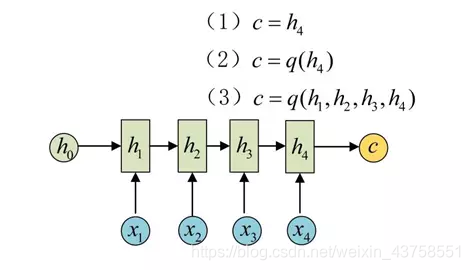 得到c有多种方式,最简单的方法就是把Encoder的最后一个隐状态赋值给c,还可以对最后的隐状态做一个变换得到c,也可以对所有的隐状态做变换。
得到c有多种方式,最简单的方法就是把Encoder的最后一个隐状态赋值给c,还可以对最后的隐状态做一个变换得到c,也可以对所有的隐状态做变换。
拿到c之后,就用另一个RNN网络对其进行解码,这部分RNN网络被称为Decoder。具体做法就是将c当做之前的初始状态h0输入到Decoder中: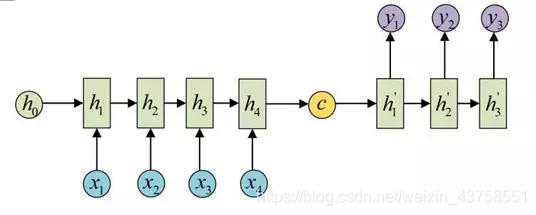 还有一种做法是将c当做每一步的输入:
还有一种做法是将c当做每一步的输入: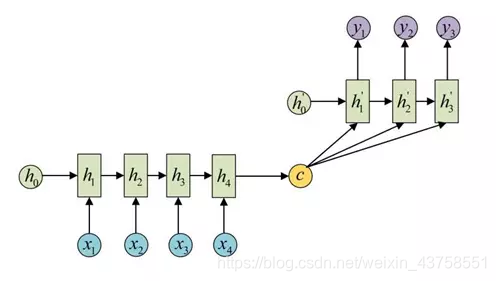 由于这种Encoder-Decoder结构不限制输入和输出的序列长度,因此应用的范围非常广泛,比如:机器翻译。Encoder-Decoder的最经典应用,事实上这一结构就是在机器翻译领域最先提出的文本摘要。输入是一段文本序列,输出是这段文本序列的摘要序列。阅读理解。将输入的文章和问题分别编码,再对其进行解码得到问题的答案。语音识别。输入是语音信号序列,输出是文字序列。
由于这种Encoder-Decoder结构不限制输入和输出的序列长度,因此应用的范围非常广泛,比如:机器翻译。Encoder-Decoder的最经典应用,事实上这一结构就是在机器翻译领域最先提出的文本摘要。输入是一段文本序列,输出是这段文本序列的摘要序列。阅读理解。将输入的文章和问题分别编码,再对其进行解码得到问题的答案。语音识别。输入是语音信号序列,输出是文字序列。
这里我们将Encoder阶段叫做编码阶段。对应的Decoder阶段叫做解码阶段。中间语义向量C可以看做是所有的输入内容的一个集合,所有的输入内容都包括在C里面。
二 Seq2Seq的应用场景
Seq2Seq的应用随着计算机技术、人工智能技术、算法研究等方面的发展以及社会发展的需求,它在许多领域产生了一些运用。目前,它主要的应用场景有(如果你感兴趣可以看看这里):
① 机器翻译(当前最为著名的Google翻译,就是完全基于Seq2Seq+Attention机制开发出来的)。
② 聊天机器人(小爱,微软小冰等也使用了Seq2Seq的技术(不是全部))。
③ 文本摘要自动生成(今日头条等使用了该技术)。
④ 图片描述自动生成。
⑤ 机器写诗歌、代码补全、生成 commit message、故事风格改写等。
三 Seq2Seq原理解析
了解了Seq2Seq的应用场景,你有没有急切的学习它的冲动呢?如果有,那么请继续向下看。
首先,我们要明确Seq2Seq解决问题的主要思路是通过深度神经网络模型(常用的是LSTM)将一个作为输入的序列映射为一个作为输出的序列,这一过程由编码输入(encoder)与解码输出(decoder)两个环节组成。
这里我们必须强调一点,Seq2Seq的实现程序设计好之后的输入序列和输出序列长度是不可变的。
3.1 最基础的Seq2Seq模型
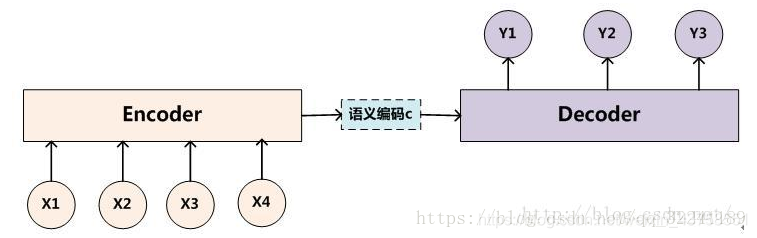 图2 简单的Seq2Seq模型
图2 简单的Seq2Seq模型
如图2,最基础的Seq2Seq模型包含了三个部分,即Encoder、Decoder以及连接两者的中间状态向量C,Encoder通过学习输入,将其编码成一个固定大小的状态向量c,继而将c传给Decoder,Decoder再通过对状态向量c的学习来进行输出。
注意:图中每一个box代表了一个RNN单元(记住!!),通常是LSTM或者GRU。
3.2 一个典型的实例
了解了最简单模型之后,我们举一个常见的栗子来详细说明。
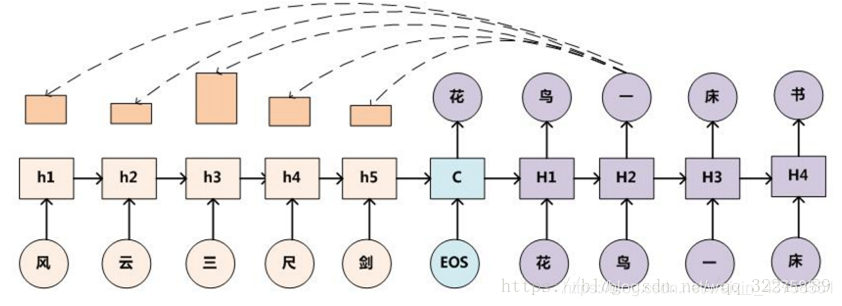 图3 Seq2Seq实例图
图3 Seq2Seq实例图
首先说明一点,图中的一些谬误(①Decoder阶段,每次都会参考中间状态向量C,不仅仅是图中的H1②目前,输入的语句序列一般采用倒序输入)。
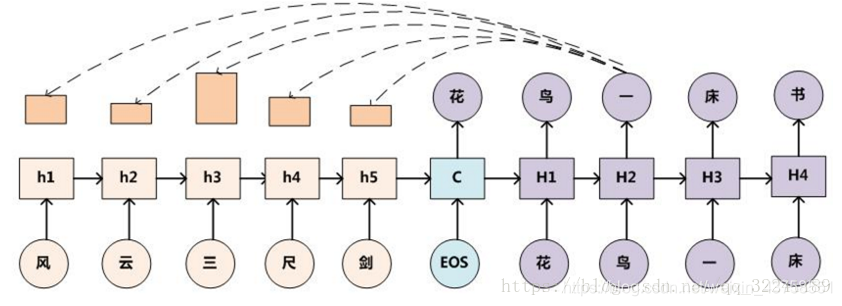
图4 Seq2Seq+Attention机制
如图4为加入Attention机制后的Seq2Seq模型示意图。
LSTM模型虽然具有记忆性,但是当Encoder阶段输入序列过长时,解码阶段的LSTM也无法很好地针对最早的输入序列解码。Attention注意力分配的机制被提出,就是为了解决这个问题。在Decoder阶段每一步解码,都能够有一个输入,对输入序列所有隐藏层的信息h_1,h_2,…h_Tx进行加权求和。打个比方就是每次在预测下一个词时都会把所有输入序列的隐藏层信息都看一遍,决定预测当前词时和输入序列的那些词最相关。
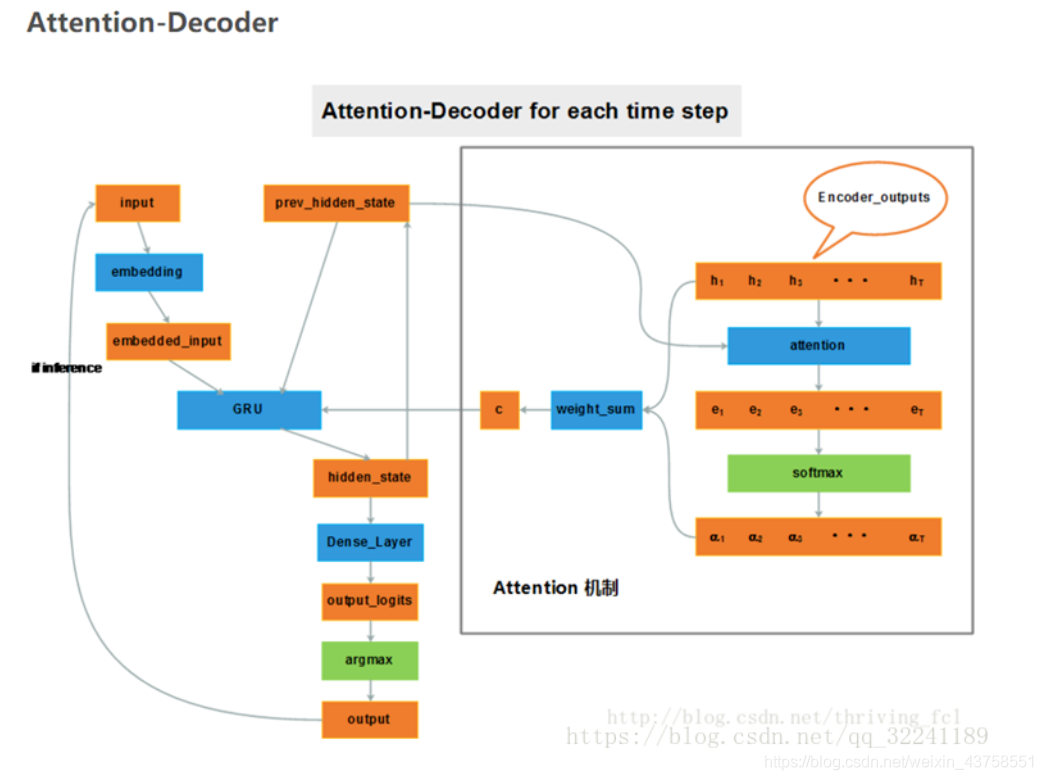
四 Seq2Seq的预处理
最后,我们要说的还有一点关键的预处理工作。
如果你有一定的基础,那么应该知道我们的NLP乃至人工智能处理的数据都是数字,那么这里的文字该怎么处理呢?我们都知道OneHot,TF,TF-IDF,词袋法等等都可以将文档数值化处理。那么,我们这里怎么进行数据的预处理工作呢?我们通常的预处理步骤如下:
① 首先我们假设有10000个问答对,统计得到1000个互异的字以及每个字对于出现的次数。
② 根据统计得到的这1000个字,按照次数从多到少进行排序,序号从0开始到999结束(得到我们的字典表ids)。
③ 对于问答对,进行One-Hot编码。
④ 由于One-Hot编码的维度较大且0较多,因此我们进行embedding降维(具体维数自定义)得到我们的特征矩阵。

















 1251
1251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









