





一、背景简介[1][2]
encoder-decoder模型如下图。我们关注的是encoder过程(下图一个注意力分散的例子)
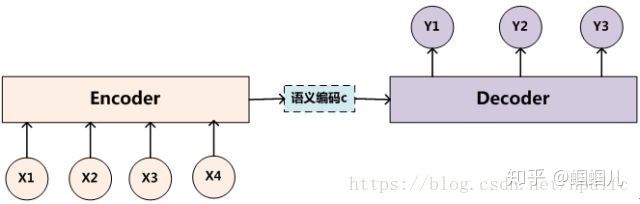
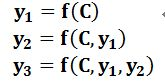
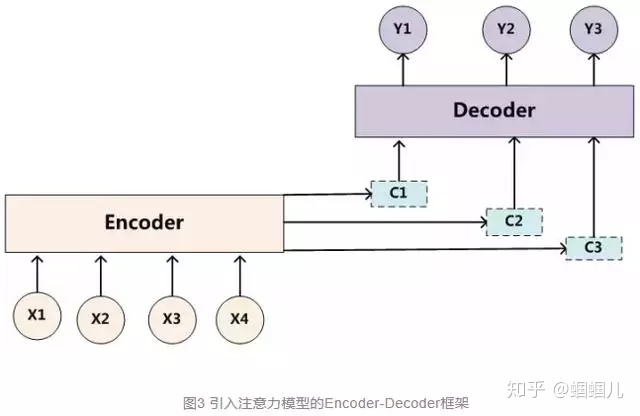
- encode过程会生成一个中间向量C,用于保存原序列的语义信息。但是这个向量长度是固定的,当输入原序列的长度比较长时,向量C无法保存全部的语义信息,上下文语义信息受到了限制,这也限制了模型的理解能力。所以使用Attention机制来打破这种原始编解码模型对固定向量的限制。
- attention模型用于解码过程中,它改变了传统decoder对每一个输入都赋予相同向量的缺点,而是根据单词的不同赋予不同的权重。在encoder过程中,输出不再是一个固定长度的中间语义,而是一个由不同长度向量构成的序列,decoder过程根据这个序列子集进行进一步处理。
二、transformer模型
transformer是google brain 在《attention is all you need》中所提的seq2seq模型,目前已经得到非常广泛的应用,BERT(Birectional Encoder Representations From Transformer)就是从transformer中衍生出来的预训练语言模型。
tranformer是并行的(对比:RNN是循环的),可以大大提升计算速率。如下图所示,transformer完成机器翻译任务,左边是encoder,右边是decoder
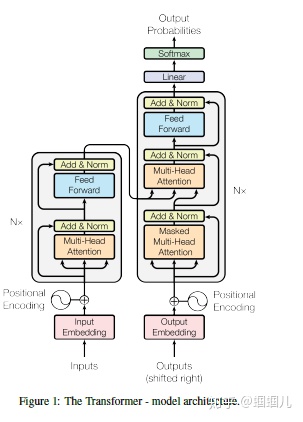
encoder会涉及到如下几个过程:
- 位置嵌入position embedding
lstm、RNN等序列模型都是按顺序处理的,但tranformer是并行处理的、没有循环神经网络中的迭代操作,那如何表示识别语言中的顺序关系呢?因此需要定义一个位置嵌入的概念,位置嵌入维度为[max sequence length, embedding dimension].
论文[3]的实现很有意思,使用正余弦函数。公式如下: PE(pos,2i)=sin(pos/100002i/dmodel)PE(pos,2i)=sin(pos/100002i/dmodel) PE(pos,2i+1)=cos(pos/100002i/dmodel)PE(pos,2i+1)=cos(pos/100002i/dmodel) 其中,pos是指词语在序列中的位置。可以看出,在偶数位置,使用正弦编码,在奇数位置,使用余弦编码。随着embedding dimension的增大,位置嵌入函数呈现不同的周期变化。
2. 自注意机制 self-attention[4]
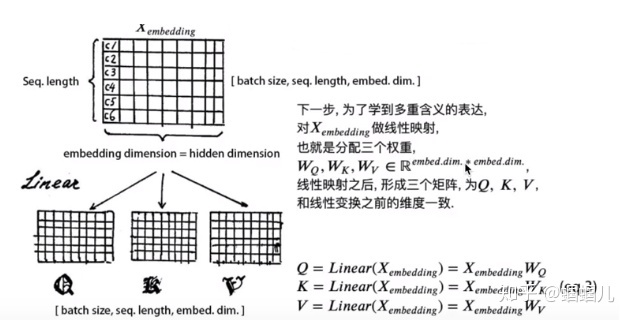
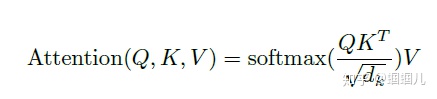
multi-head attention:注意嵌入的维度(embedding dimension)必须整除num. of heads(h), 就是必须均匀地把embedding dimension矩阵切割了h份。
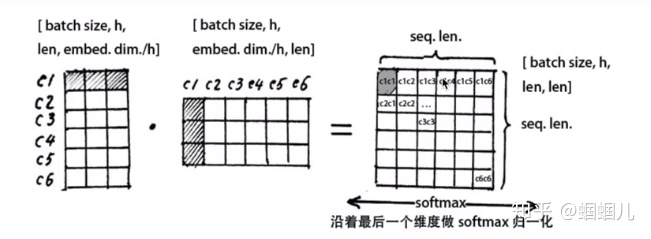
使用softmax归一化,使每个字跟其他所有字地注意力权重的和为1,注意力权重矩阵地作用就是一个注意力权重的概率分布。
点积:两个向量越相似(θ越小,cosθ越大),他们的点积就越大
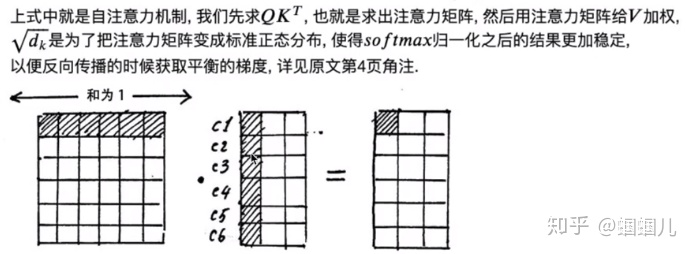
这样,每个字都含有当前句子中其他所有字的信息(且注意力权重和=1)
另外,注意有个attention mask的问题:
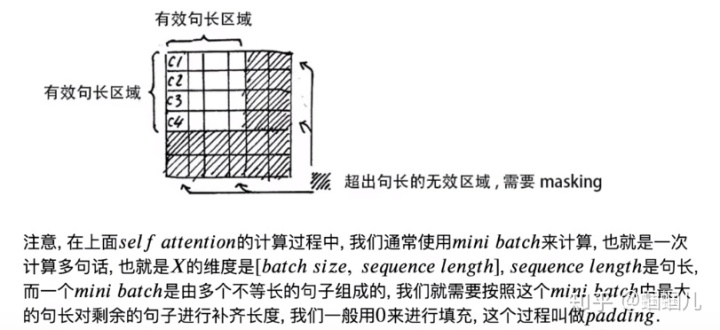
模型还涉及到l残差链接等,没看懂,算了。
参考
- ^注意力机制的基本思想和实现原理 https://blog.youkuaiyun.com/hpulfc/article/details/80448570
- ^Attention注意力机制介绍 https://www.cnblogs.com/hiyoung/p/9860561.html
- ^Attention Is All You Need https://arxiv.org/abs/1706.03762
- ^https://github.com/aespresso/a_journey_into_math_of_ml/tree/master/03_transformer_tutorial_1st_part

















 3585
3585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









