







 本文探讨了在AC算法中,策略loss(loss_pi)的变化趋势及其背后的逻辑。作者指出在负奖励环境中,loss_pi增大并不意味着策略网络不收敛,而是策略在逐渐优化。随着Critic网络的更新,actor的目标是使Critic网络输出增大,即使得Q值更接近最优。当Critic网络接近当前策略的Q值时,loss_pi趋于平缓,表明策略正在改进。强调在强化学习中,不能简单地用监督学习的思路来理解loss的收敛行为。
本文探讨了在AC算法中,策略loss(loss_pi)的变化趋势及其背后的逻辑。作者指出在负奖励环境中,loss_pi增大并不意味着策略网络不收敛,而是策略在逐渐优化。随着Critic网络的更新,actor的目标是使Critic网络输出增大,即使得Q值更接近最优。当Critic网络接近当前策略的Q值时,loss_pi趋于平缓,表明策略正在改进。强调在强化学习中,不能简单地用监督学习的思路来理解loss的收敛行为。
记录
在记录DDPG等AC算法的loss时,发现其loss如下图:
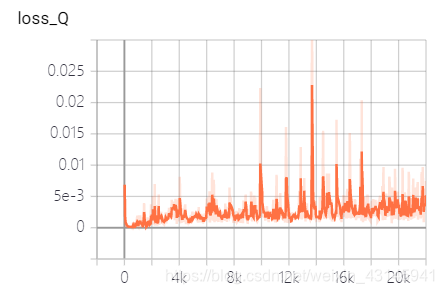
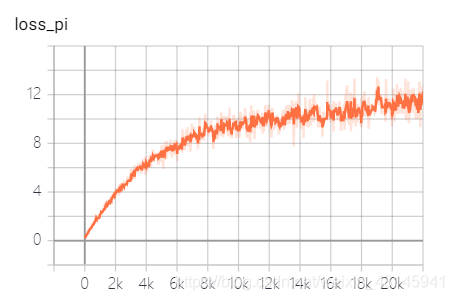
最开始的想法:策略pi的loss不是负的q值吗,如果loss_pi增大意味着q减小,pi不是朝着q增大的方向吗?
经过和别人的讨论以及自己的思考,得出如下结论:
- 我的环境所有奖励都是负奖励,这是这个问题思考的基础点。
- 由于都是负奖励,所以无论是什么策略下的Q值都是负数,最优策略下的Q值也是负数。
- Critic网络在初始化后权重都是非常接近0的数,导致Critic网络的所有预测Q值都接近0,而loss_pi是batch_size个负Q的均值,因此此时loss_pi接近0,这解释了loss_pi的起点为什么是0。
- 明确一个观点:loss_pi增大并不是策略网络不收敛,因为AC算法的Actor大都采用的是使用策略梯度进行网络更新,其loss仅仅是负Q的平均

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1298
1298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











