






你们单位可能有些数据比较机密,比较敏感,不能连接互联网。但又想用LLM(Large Language Model 大语言模型)来提高工作效率,这个时候你可以利用ollama在内网本地部署LLM来实现。本文以部署deepseek为例。
大家可以先在自己电脑上用虚拟机部署好,再用U盘或或者光盘把虚拟机文件复制到内网去。也可以直接把安装文件和模型文件复制到内网再安装和配置。
一、使用ollama部署本地LLM模型
1、安装设置ollama
1、官网https://ollama.com/下载自已电脑对应的ollama 版本。
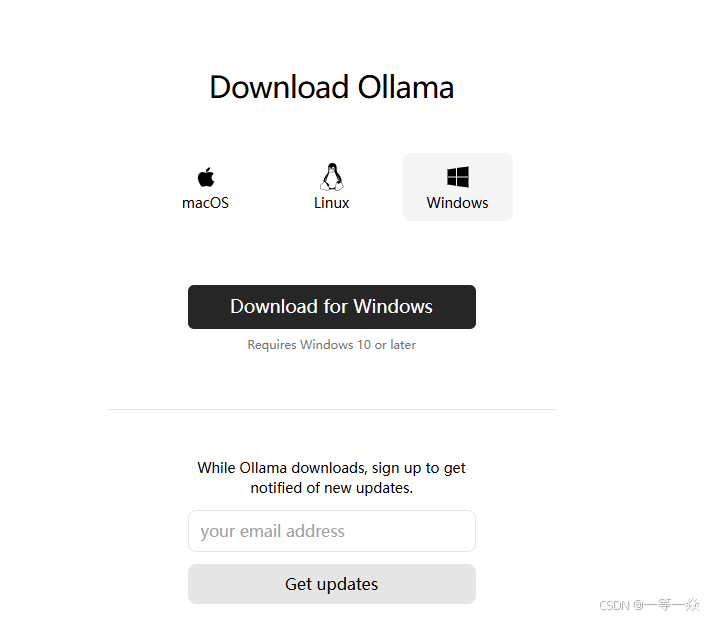
直接下载 可能报错,最好用迅雷或其它下载工具下载。
安装比较简单,直接点击下载好的OllamaSetup.exe文件下一步下一步就好。
装好后,软件会自动启动
以windows系统为例
win+R ->cmd 打开终端输入
ollama -v
如下图显示ollama版本即表示安装成功。

2、环境变量设置 windows 电脑
模型文件默认放在**C:\Users\(你电脑的登录用户).ollama\models这个目录下,如我的电脑为C:\Users\tt.ollama\models。这样很容易造成C盘空间不足,若想更换模型文件位置需要设置系统环境变量。
设置->系统->系统信息
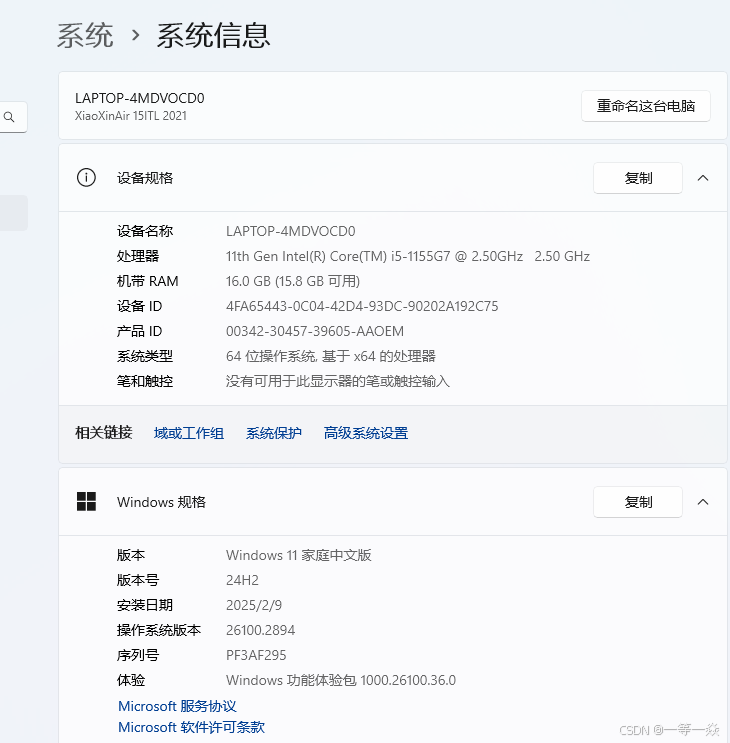
选择高级系统设置
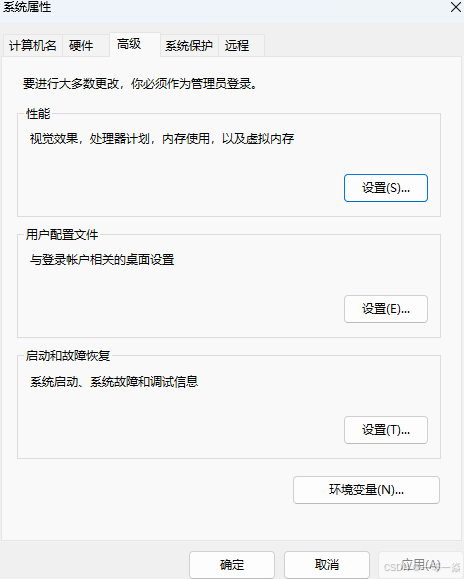
选择环境变量->选择新建

这两个新建都可以
按下图新建一个OLLAMA_MODELS的环境变量,变量值就是你有模型文件放置的位置

然后重启电脑ollama设置就会生效了。
2、
2、下载模型
可以选择两种方法。
1、第一种是直接用ollama下载。可以按官网https://www.ollama.com/library/deepseek-r1的命令直接下载对应版本的deepseek即可?

右侧为模型文件大小,模型文件是放在显存或者内存里运行的,所以模型文件大小不要超过你电脑的显存或者内存的50%。如8g显存,可以选择7b或8b版本,集成显卡的可以选择1.5b版本,选择14b版本可能会跑不动,你大可动手一试。具体情况因个人电脑而异。1.5b为参数数量,数字越大参数越多,deepseek越聪明。
这里我以1.5b版本为例。
ollama run deepseek-r1:1.5b
然后ollama便会开始下载模型。
下载好后,通过以下命令查看已安装好的模型。
ollama list
查看已经安装好的模型

下载速度开始很快,后面会慢到几十K甚至几K,这里下载模型文件推荐另一种方法。
2.魔搭社区下载deepseek.gguf模型文件。
先进入阿里的魔搭社区,点击模型库,魔搭社区,模型很多,可以直接在搜索栏里搜索***deepseek guff***

选择一个适合自己电脑的模型文件下载
比如选择第一个点开
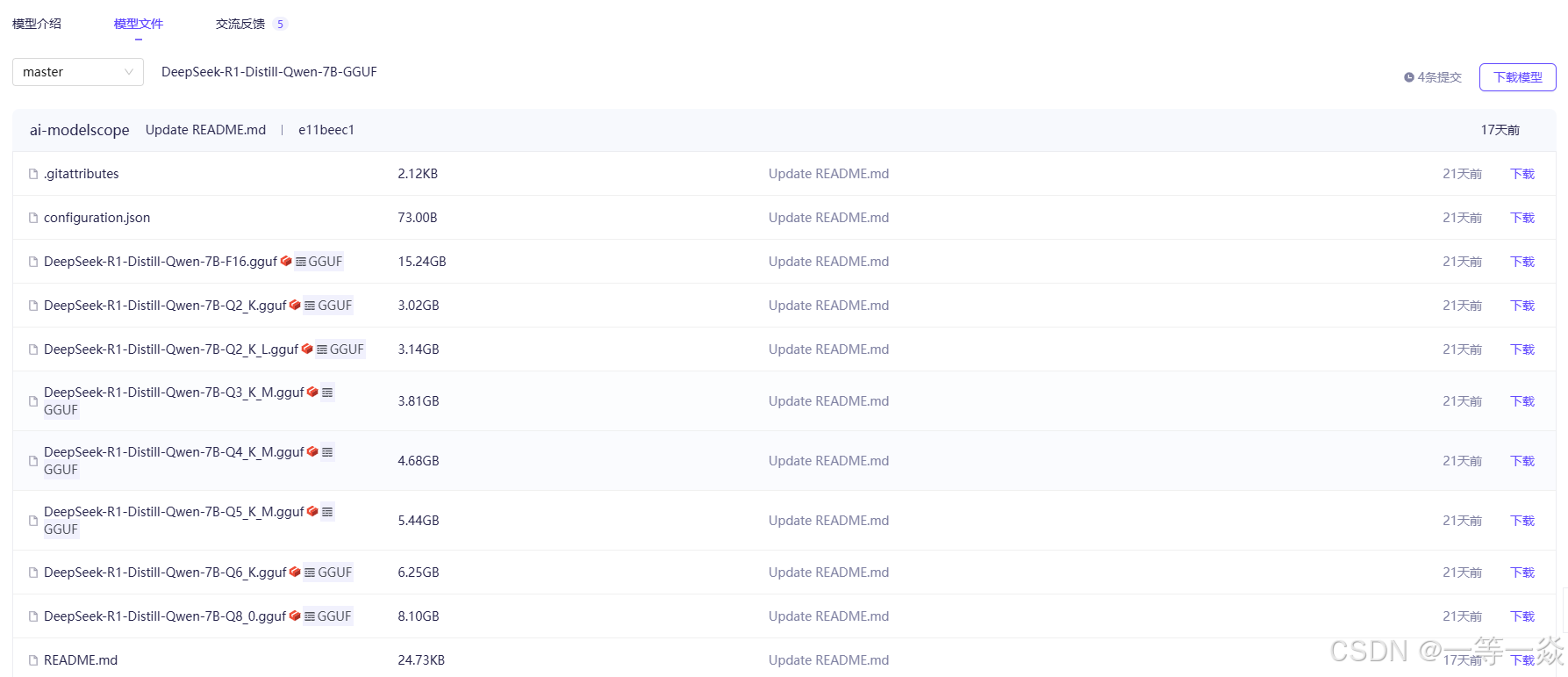
这里的gguf文件都可以下载,而且速度很快,文件越大,精度越高,越聪明,电脑也运行越吃力。
将文件下载后,复制到刚才环境变量里设置的***OLLAMA_MODELS***文件夹下,我这里是***D:\AImodels***
3、创建模型
1、进入你的OLLAMA_MODELS文件夹,我这里是D:\AImodel,创建Modelfile文件,新建一个记事本文件,并打开,文件中写入下面内容
FROM D:\AImodel\DeepSeek-R1-Distill-Qwen-1.5B.gguf
然后再去掉文件的.txt后缀名!!!!!!!
2、在D:\AImodel文件夹 下输入cmd 命令ollama create (这里填你下载的模型名字,记得名字要和Modelfile里的文件名一致) -f Modelfile如下图

如上图所示表示模型安装成功
也可以使用命令 ollama list查看安装的模型
ollama list
查询结果如下图所示

4、运行模型
使用***ollama run (模型名)*** 运行模型,模型名比较长的,可以先打个ollama list再复制即可
ollama run DeepSeek-R1-Distill-Qwen-1.5B:latest
如下图所示,模型开始运行,LLM本地部署成功。

未完待续…

















 5437
5437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









