










1. 单链表
单链表是一种链式存储结构,其包括data域以及next域。data内存放数据,next指向下一个节点。
1.1 巨丑的图解

如图即是单链表的逻辑结构
2. 操作
2.1 节点类
class Node<E>{
/**
* data域
*/
public E data;
public Node<E> next;
public Node(E data){
this.data = data;
}
@Override
public String toString() {
return "Node{" +
"data=" + data +
'}';
}
}
2.2 添加
添加非常简单,如上图,不难看出添加节点只需要将链表的最后一个节点的next域指向所需要的添加的节点即可,代码如下:
/**
* 添加节点,传入data
* @param e
*/
public void add(E e){
Node<E> data = new Node<E>(e);
Node<E> temp = head;
while (temp.next != null){
temp = temp.next;
}
temp.next = data;
size++;
}
2.3 删除
删除可以分为你要删除内容为某某的节点,或者删除第几个节点,图示如下:
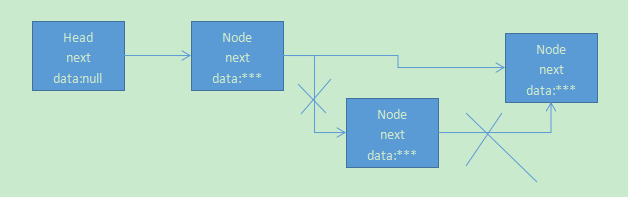
如图,就把第二个节点删除,代码实现如下:
/**
* 删除第index个元素
* @param index
*/
public void delete(int index){
if (index > size){
throw new RuntimeException("越界删除");
}
Node<E> temp = head;
for (int i = 1; i < index; i++){
temp = temp.next;
}
temp.next = temp.next.next;
size--;
}
/**
* 删除节点为e的节点
* @param e
*/
public void delete(E e){
Node<E> temp = head;
while (temp.next != null){
if (temp.next.equals(e)){
break;
}
temp = temp.next;
}
if (temp.next == null){
throw new RuntimeException("该节点不存在");
}
temp.next = temp.next.next;
size--;
}
2.4 链表长度
/**
* 返回长度
* @return
*/
public int size(){
return size;
}
2.5 获取链表数据
遍历链表,到第i个元素停止,返回即可
/**
* 获取第index个数据
* @param index
* @return
*/
public E get(int index){
if (head.next == null || size < index - 1){
throw new RuntimeException("下标越界");
}
Node<E> temp = head;
for (int i = 0; i <= index; i++){
temp = temp.next;
}
return temp.data;
}
3. 完整的代码
package com.nansl.stucts.linkedList;
import java.util.LinkedList;
public class SingleLinkList<E>{
/**
* 头结点。指向链表的第一个元素,该节点data为空,next为链表内第一个有效节点
*/
private Node<E> head;
/**
* 记录链表长度
*/
private int size;
/**
* 链表构造器
*/
public SingleLinkList(){
head = new Node<E>(null);
head.next = null;
this.size = 0;
}
/**
* 添加节点,传入data
* @param e
*/
public void add(E e){
Node<E> data = new Node<E>(e);
Node<E> temp = head;
while (temp.next != null){
temp = temp.next;
}
temp.next = data;
size++;
}
/**
* 删除第index个元素
* @param index
*/
public void delete(int index){
if (index > size){
throw new RuntimeException("越界删除");
}
Node<E> temp = head;
for (int i = 1; i < index; i++){
temp = temp.next;
}
temp.next = temp.next.next;
size--;
}
/**
* 删除节点为e的节点
* @param e
*/
public void delete(E e){
Node<E> temp = head;
while (temp.next != null){
if (temp.next.equals(e)){
break;
}
temp = temp.next;
}
if (temp.next == null){
throw new RuntimeException("该节点不存在");
}
temp.next = temp.next.next;
size--;
}
/**
* 获取第index个数据
* @param index
* @return
*/
public E get(int index){
if (head.next == null || size < index - 1){
throw new RuntimeException("下标越界");
}
Node<E> temp = head;
for (int i = 0; i <= index; i++){
temp = temp.next;
}
return temp.data;
}
/**
* 返回长度
* @return
*/
public int size(){
return size;
}
/**
* 获取单链表倒数第K个节点
* @param K
* @return
*/
public E getK(int K){
if (K > size){
throw new RuntimeException("当前链表不存在超过K个元素");
}
if (K <= 0){
throw new RuntimeException("请从倒数第一开始,不要小于等于0");
}
Node<E> temp = head;
for (int i = 0; i <= size - K; i++){
temp = temp.next;
}
return temp.data;
}
/**
* 反转链表
*/
public void reversal(){
if (size <= 1){
return;
}
Node<E> reversalHead = new Node<>(null);
Node<E> cur = head.next;
Node<E> next = null;
while (cur != null){
//记录当前节点的下一个 因为需要将此节点放在reversalHead节点的后面 并且其后的节点反转
next = cur.next;
//这两步可以使链表反转 即在前面的节点 会成为后面节点的next
cur.next = reversalHead.next;
//此时cur后面指向的是他前面的反序的节点
reversalHead.next = cur;
//换下一个节点
cur = next;
}
head.next = reversalHead.next;
}
}
class Node<E>{
/**
* data域
*/
public E data;
public Node<E> next;
public Node(E data){
this.data = data;
}
@Override
public String toString() {
return "Node{" +
"data=" + data +
'}';
}
}
下一篇文章计划写反转单链表,写的不好多多包涵。

















 251
251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









