



1. Embedding模型配置
使用ollama模型,导入qwen3的embedding-8B模型,导入流程参考:
Ollama离线部署模型
qwen3-Embedding模型文件可从魔塔社区下载:
Qwen3-Embedding-8B
1.2 Coze配置
在coze_studio/docker目录下输入:
vim .env
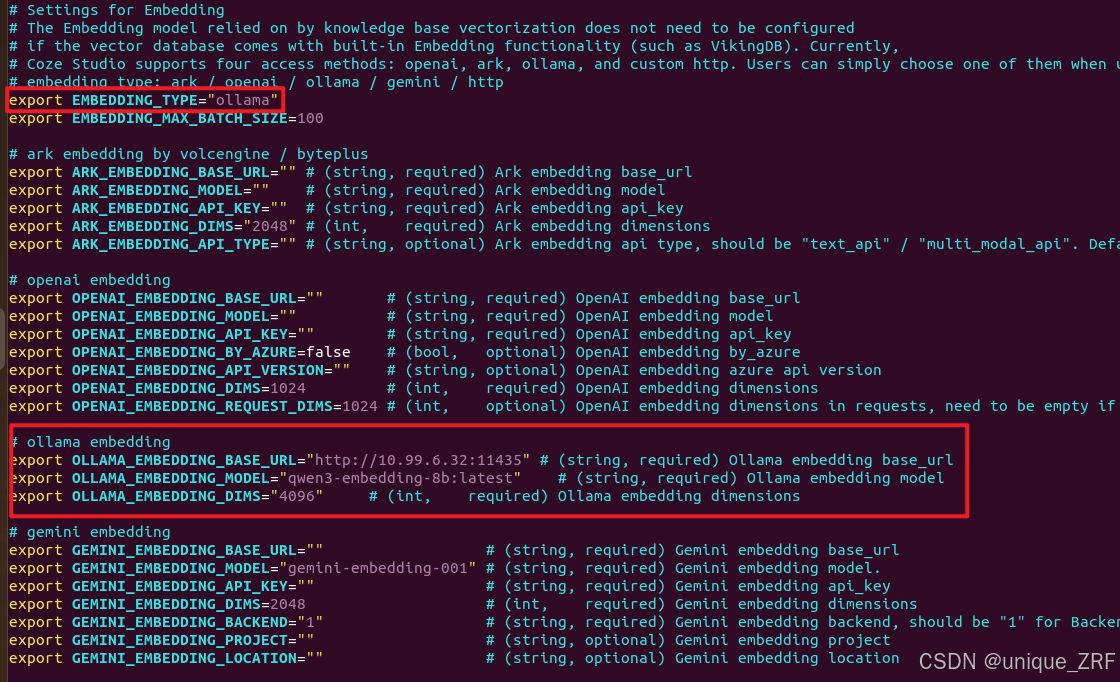
找到Embedding设置:
将EMBEDDING_TYPE改为ollama,并修改下面的ollama调用的url和模型名称
ollama中的模型如下:
ollama list
配置完成后输入 :wq 保存vim编辑的内容;


然后返回docker目录下输入:
docker停止:
docker stop $(docker ps -q)
coze启动:
docker-compose --profile ‘*’ up -d
coze启动后在资源库中创建知识库,并上传文件
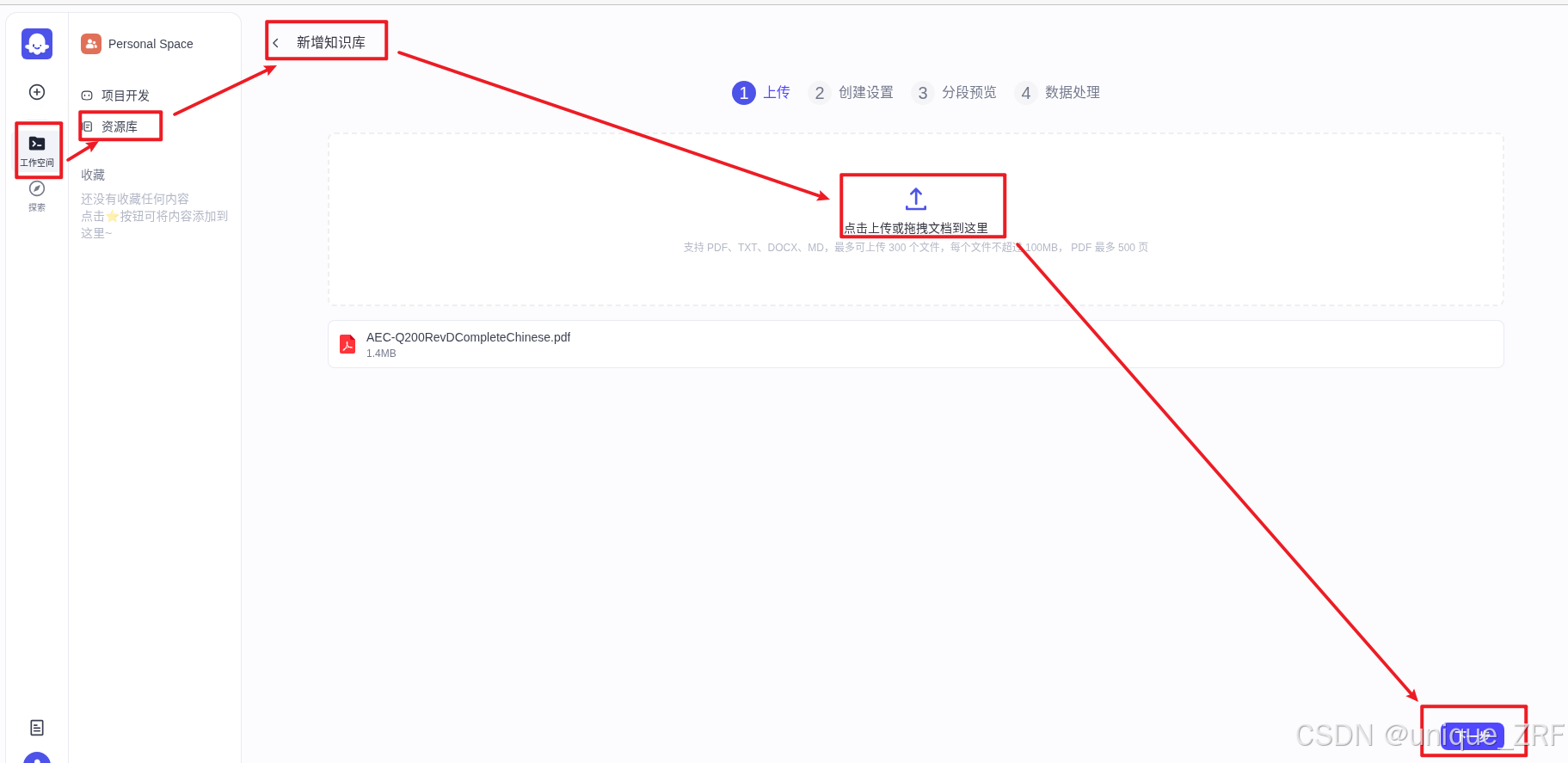
然后创建设置:
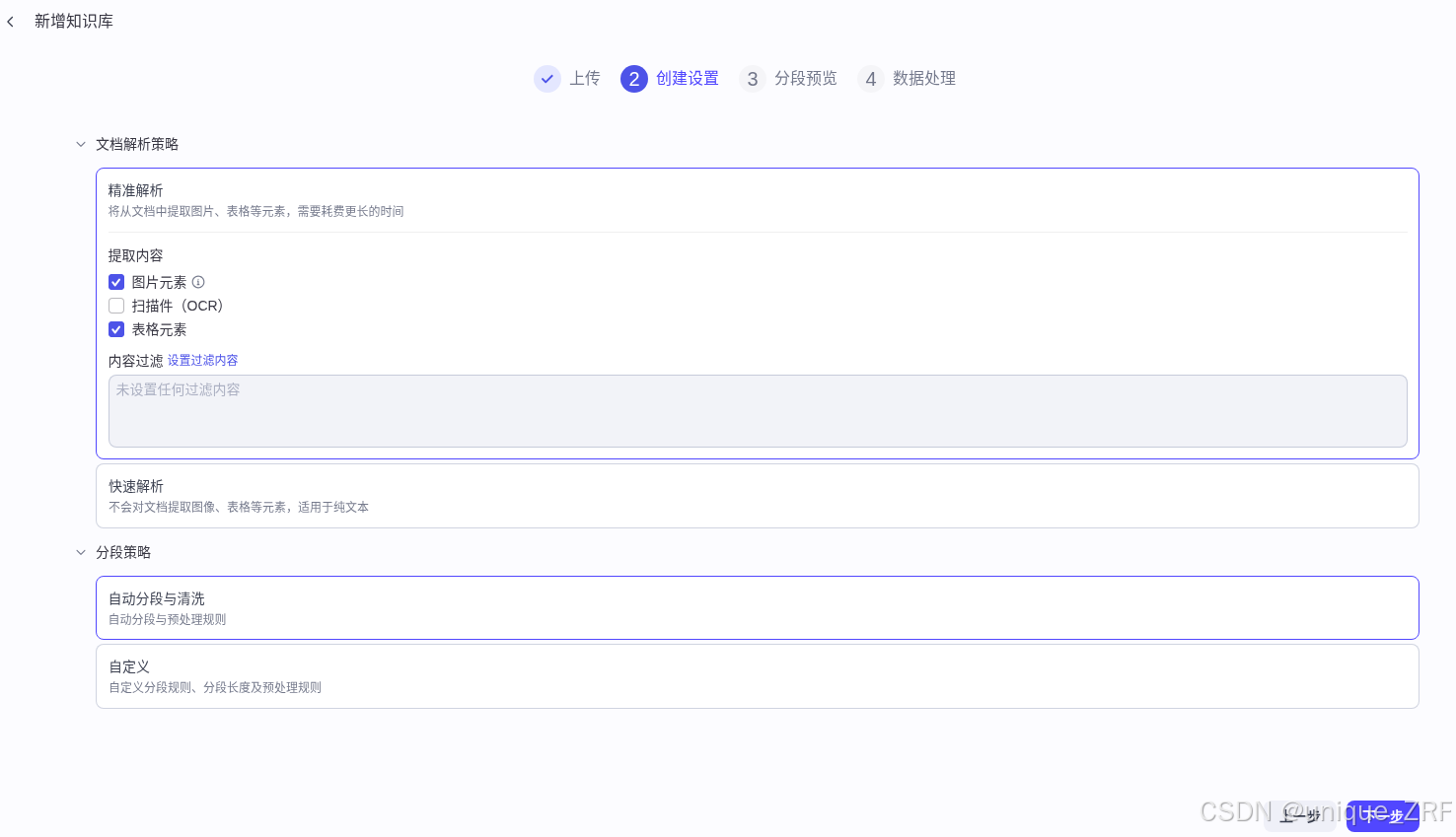
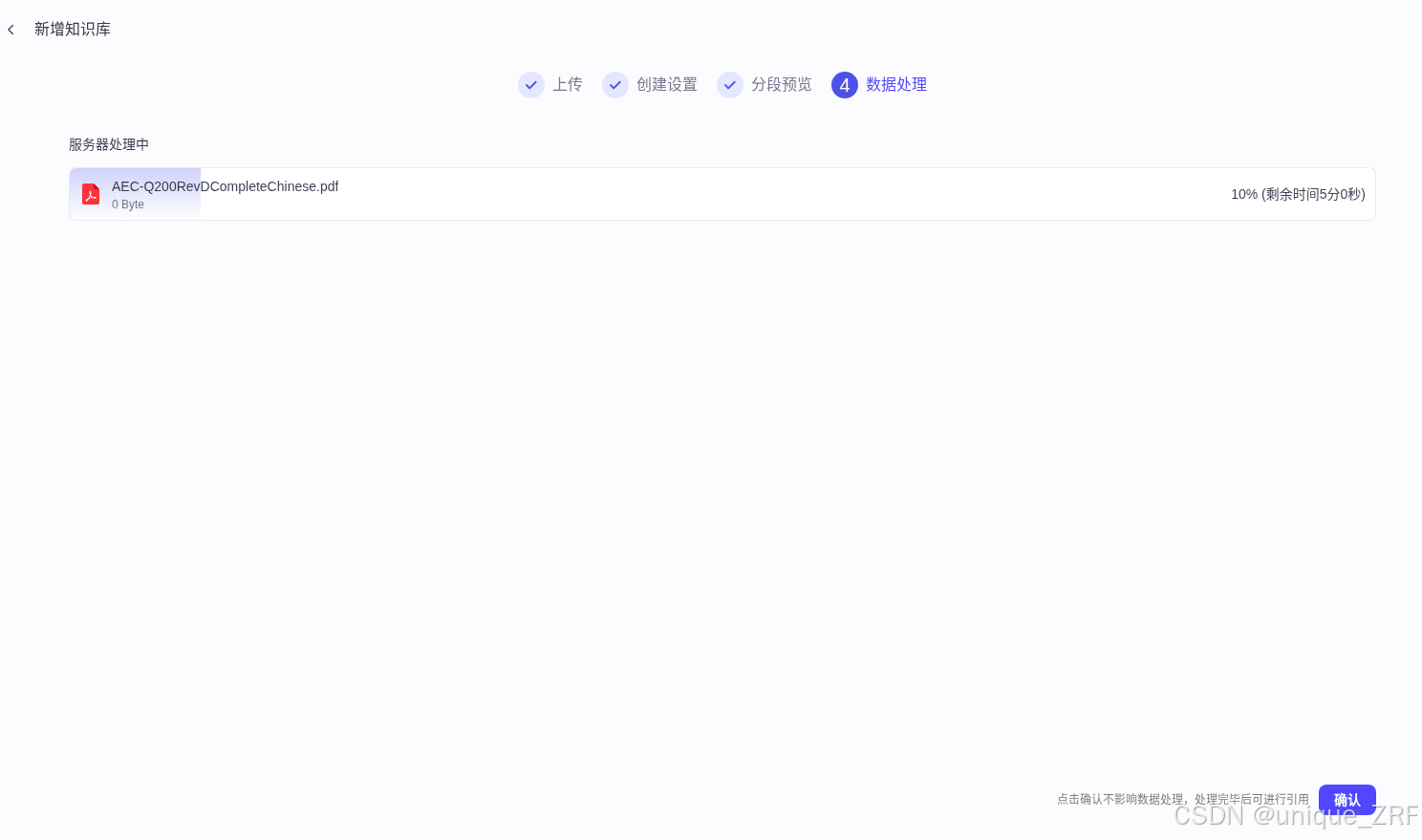
分段预览和数据处理:
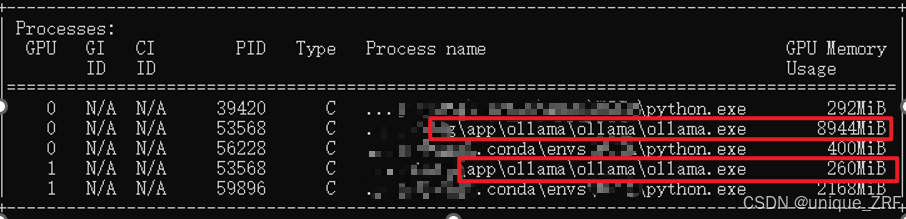
在cmd命令行输入nvidia-smi:
可以看到GPU使用情况:
2. PaddleOCR模型配置
2.1 paddle-ocr安装和代码编写
首先安装PaddleOCR:
pip install paddleocr
pip install paddlepaddle
pip install fastapi uvicorn
paddlerocr运行代码,注意inference参数可能需要自己下载:
from flask import Flask, request, jsonify
from paddleocr import PaddleOCR
import base64, numpy as np, cv2
ocr = PaddleOCR(use_angle_cls=True, use_gpu=False,
det_model_dir='./inference/ch_PP-OCRv3_det_infer',
rec_model_dir='./inference/ch_PP-OCRv3_rec_infer',
cls_model_dir='./inference/ch_ppocr_mobile_v2.0_cls_infer')
app = Flask(__name__)
@app.route("/ocr", methods=["POST"])
def ocr_api():
img_b64 = request.json["image"]
img = cv2.imdecode(np.frombuffer(base64.b64decode(img_b64), np.uint8), 1)
res = ocr.ocr(img, cls=True)
return jsonify(res)
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8999)
然后创建paddle_structure.py
from fastapi import FastAPI, UploadFile, File
from paddleocr import PaddleOCR, PPStructure
import uvicorn
import os
app = FastAPI()
# 初始化版面结构化 OCR
table_engine = PPStructure(show_log=True, lang='ch')
UPLOAD_DIR = "uploads"
os.makedirs(UPLOAD_DIR, exist_ok=True)
@app.post("/structure")
async def do_ocr_structure(file: UploadFile = File(...)):
file_path = os.path.join(UPLOAD_DIR, file.filename)
with open(file_path, "wb") as f:
f.write(await file.read())
result = table_engine(file_path)
return {"code": 0, "msg": "success", "data": result}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=9999)
对于离线环境,需要下载paddler-ocr的inference文件并配置:
inference下载和使用
2.2 Coze配置
终端 coze的docker目录下输入:
vim .env
对OCR进行配置并保存:
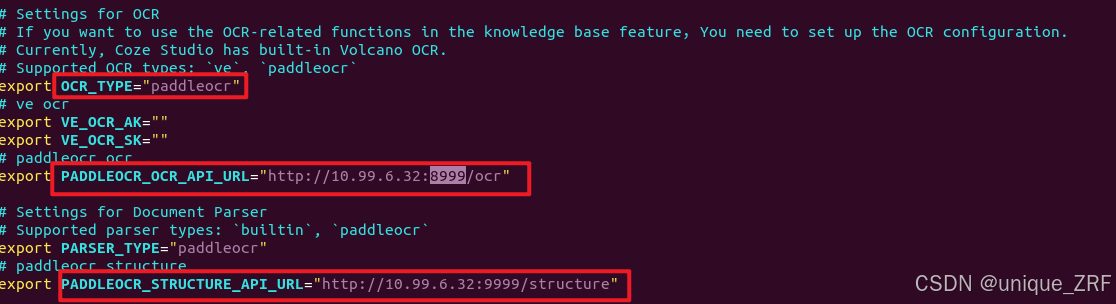
然后返回docker目录下输入:
docker停止:
docker stop $(docker ps -q)
coze启动:
docker-compose --profile ‘*’ up -d
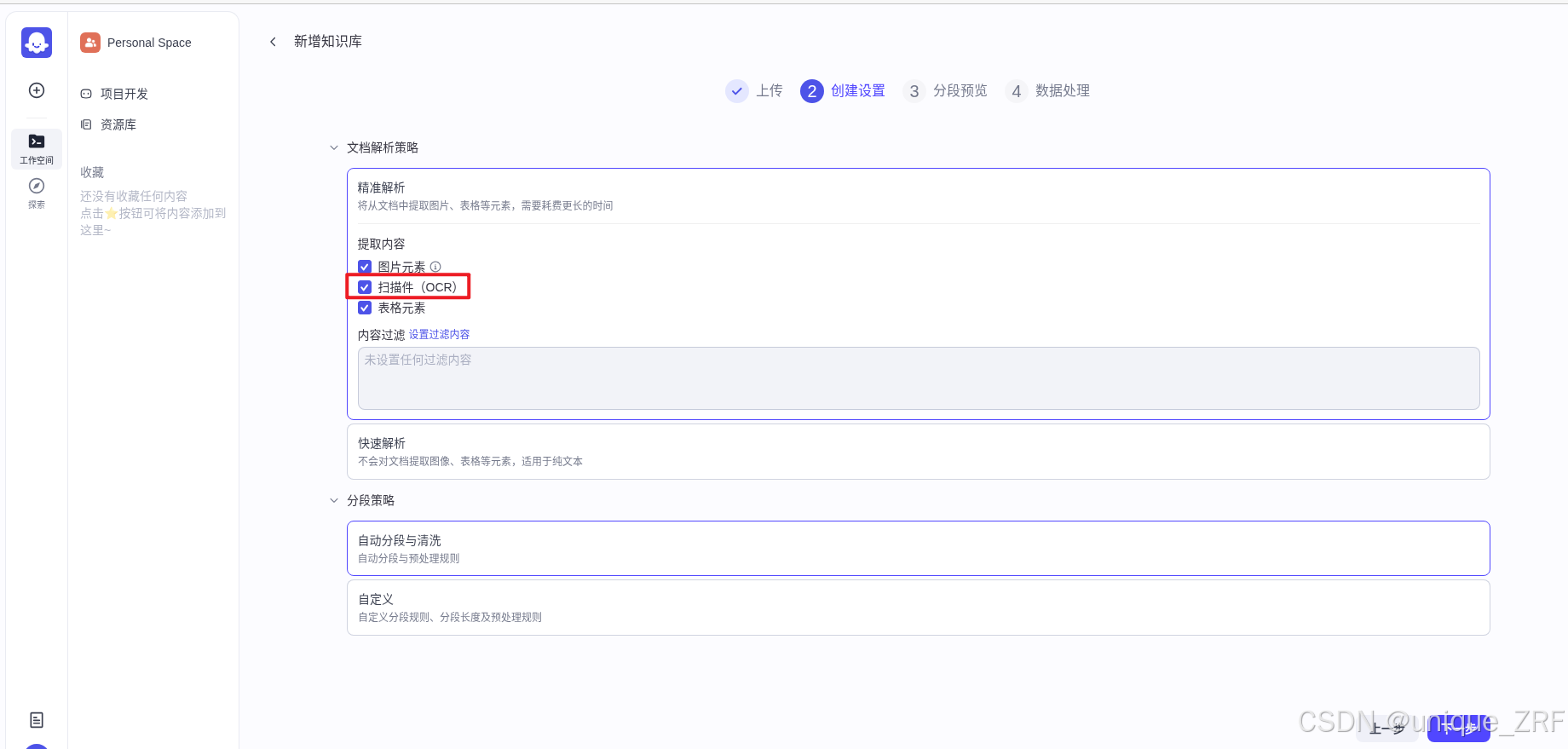
coze启动后在资源库中创建知识库,并上传文件,勾选扫描件(OCR)选项,点击下一步之后进行数据处理
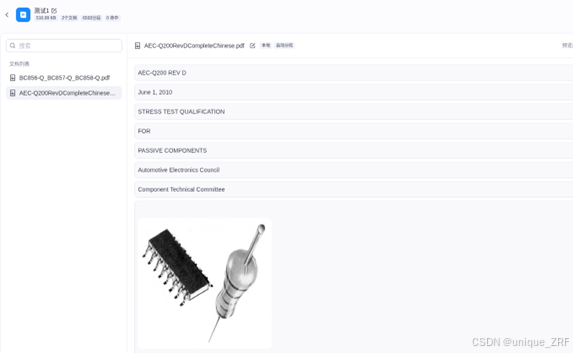
解析结果如下:



















 796
796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









