



本文作者 Lance Martin,斯坦福博士、LangChain 工程师。内容整理自他与 Manus 联合创始人纪逸超(Yichao “Peak” Ji)的一次视频分享后的笔记与思考。
在这场对话中,Lance 讨论了一个既重要又常被忽视的话题——上下文工程(Context Engineering),并结合 Manus 等智能体的实践,分享了如何通过更聪明的上下文管理来提升模型表现。
希望这些经验能给你带来启发,无论你是做智能体开发、LangChain 应用,还是单纯对 AI 感兴趣。
为什么需要上下文工程

早些时候,我参加了与 Manus 联合创始人兼首席战略官纪逸超(Yichao “Peak” Ji)的网络研讨会。下面是我的笔记。
Anthropic 将智能体定义为一种系统:“在这种系统中,大模型可以自主管理自己的流程和工具使用,同时掌控完成任务的方式。简单来说,就是 大模型在一个循环中调用各种工具。”
Manus 是目前最受欢迎的通用消费者级智能体之一。一个典型的 Manus 任务通常会调用 50 次工具。如果没有上下文工程,这些工具调用的结果就会不断累积到 LLM 的上下文窗口里。随着上下文窗口变满,很多人发现 LLM 的性能会下降。
举个例子,Chroma 有一项关于上下文衰退的优秀研究,而 Anthropic 也解释过,上下文增长会消耗 LLM 的注意力预算。因此,在构建智能体时,仔细管理哪些信息进入 LLM 的上下文窗口非常重要。Karpathy 对此总结得很清楚:
“上下文工程是一门微妙的艺术与科学,它的核心在于为智能体的下一步行动,精准填充上下文窗口所需的“刚好合适”的信息。”
上下文工程的方法

每次 Manus 会话都会使用一台专用的云端虚拟机,为智能体提供一个虚拟计算环境,包括文件系统、用于操作文件的工具,以及在沙箱环境中执行命令(例如内置工具和标准 shell 命令)的能力。
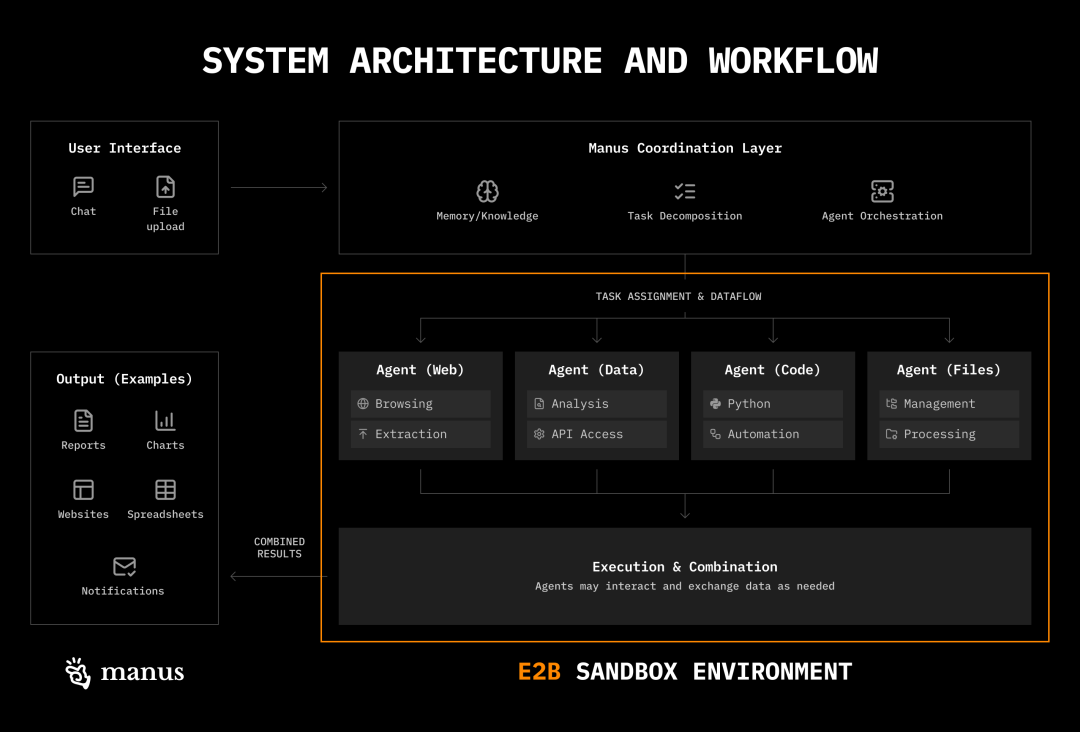
在这个沙箱中,Manus 使用三种主要的上下文工程策略,这些策略与 Anthropic 提出的方式类似,我在许多项目中也见过:
减少上下文(Reduce Context)
卸载上下文(Offload Context)
隔离上下文(Isolate Context)
上下文减少

在 Manus 中,每次工具调用都有完整(full)和精简(compact)两种表示方式。完整版本包含工具调用的原始内容(例如完整的搜索结果),并存储在沙箱中(如文件系统)。精简版本则只保存指向完整结果的引用(例如文件路径)。
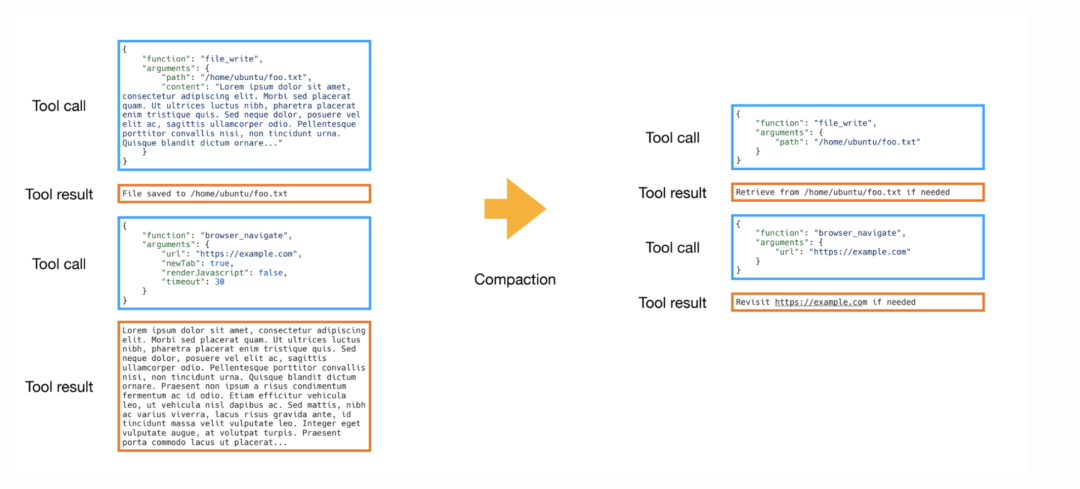
Manus 会对较老的过期工具结果进行精简处理,也就是用精简版本替换完整结果。这样,智能体仍然可以按需获取完整内容,但通过删除已经被用来决策的过期结果节省了 token。
较新的工具结果会保留完整,以指导智能体的下一步决策。这是一种通用的上下文减少策略,也类似于 Anthropic 的上下文编辑功能:
当上下文接近 token 上限时,上下文编辑会自动清理过期的工具调用和结果,同时保留对话流程,从而延长智能体无需手动干预就能执行任务的时间。
当上下文接近 token 上限时,上下文编辑会自动清理过期的工具调用和结果,同时保留对话流程,从而延长智能体无需手动干预就能执行任务的时间。
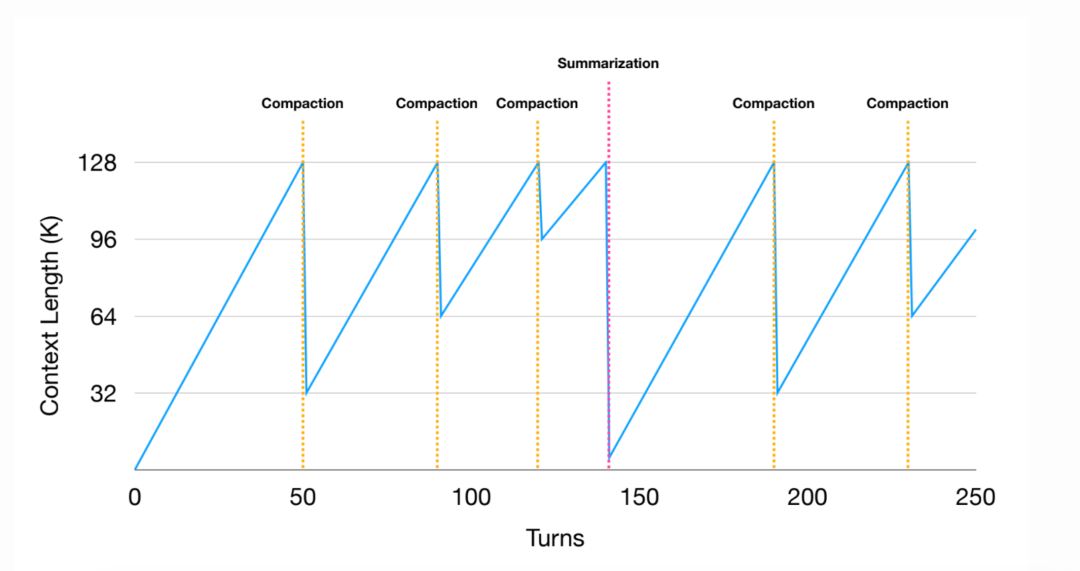
当精简达到边际效益递减时(见下图),Manus 会对整个轨迹进行总结。总结是基于完整工具结果生成的,并通过固定的 schema 定义字段,确保为每条智能体轨迹生成一致的摘要对象。
上下文隔离

Manus 对多智能体采用务实策略,不人为划分角色。人类通常按角色组织(设计师、工程师、项目经理),是因为认知能力有限,而 LLM 不一定有这些限制。
因此,在 Manus 中,子智能体的主要目标是隔离上下文。例如,如果有一个任务要完成,Manus 会将任务分配给拥有自己上下文窗口的子智能体。
Manus 使用多智能体系统,包括:
规划者(planner):分配任务
知识管理者(knowledge manager):审核对话并决定哪些内容保存到文件系统
执行者子智能体(executor sub-agent):执行规划者分配的任务
最初,Manus 使用 todo.md 来规划任务,但发现大约三分之一的动作都花在更新任务列表上,浪费了大量 token。后来,他们改为专门的规划者智能体,通过调用执行者子智能体来完成任务。
在一次播客中,Anthropic 的多智能体研究员 Erik Schluntz 提到,他们也用类似方式设计多智能体系统:规划者分配任务,并使用函数调用作为启动子智能体的通信协议。Erik 和 Walden Yan(Cognition)指出,多智能体的一个核心挑战是规划者与子智能体之间的上下文共享。
Manus 解决方式有两种:
简单任务:规划者只需子智能体的输出,直接通过函数调用传递指令即可,类似 Claude Code 的任务工具。
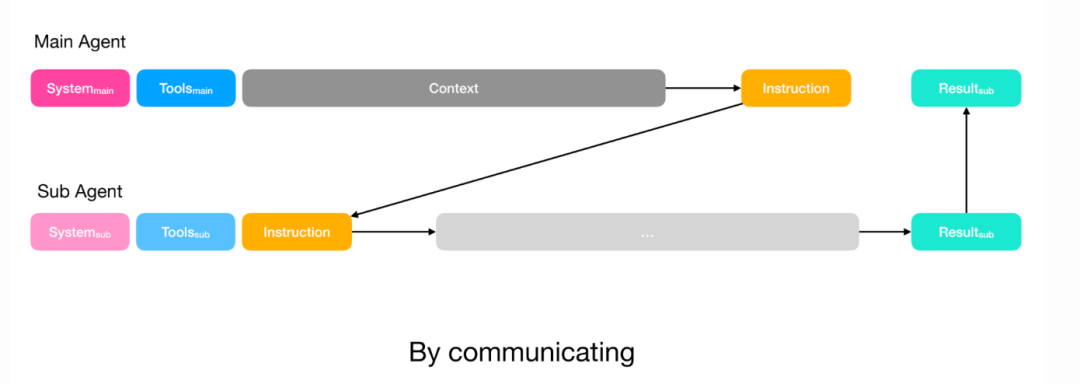
复杂任务:如果子智能体需要写入规划者也会使用的文件,规划者会将完整上下文共享给子智能体。子智能体仍然有自己的操作空间(工具和指令),但可以访问与规划者相同的完整上下文。
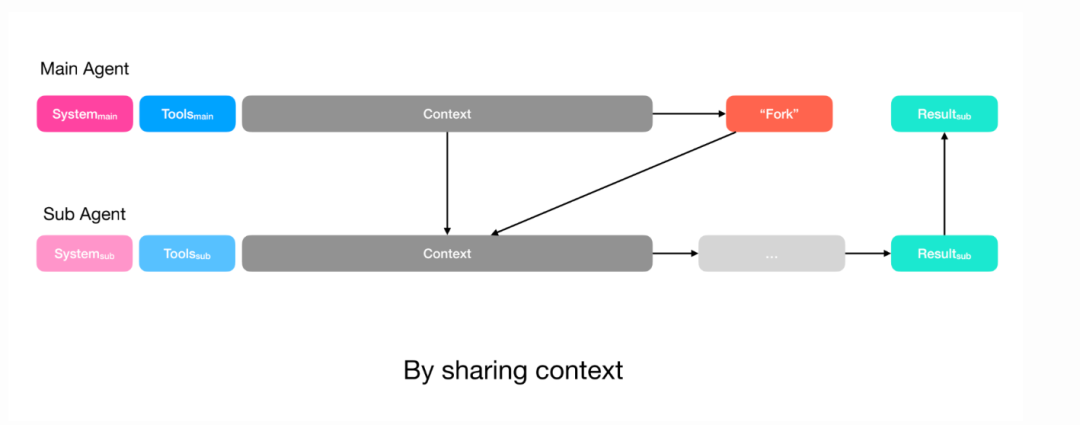
无论哪种情况,规划者都会定义子智能体的输出 schema。子智能体通过 submit results工具填写,然后返回给规划者,同时 Manus 使用受限解码保证输出符合预定义格式。
上下文卸载

工具定义
我们希望智能体能执行多种操作。理论上,可以给 LLM 绑定大量工具,并提供详细使用说明。但工具描述会占用宝贵 token,而且工具过多(尤其是重叠或模糊的工具)容易让模型混淆。
一种趋势是,让智能体只使用少量通用工具,从而访问计算环境。例如,仅用 Bash 工具和几个文件系统访问工具,智能体就能执行广泛操作!
Manus 将这一思路视为分层操作空间:函数/工具调用层 + 虚拟计算沙箱。Peak 提到,Manus 使用少量原子函数(<20),包括 Bash、文件系统管理工具、代码执行工具等。
Manus 并不是把所有操作都放在函数调用层,而是把大多数操作卸载到沙箱层。在沙箱中,Manus 可以直接用 Bash 工具执行各种实用工具,MCP 工具也通过 CLI 暴露,智能体同样可以通过 Bash 调用执行。
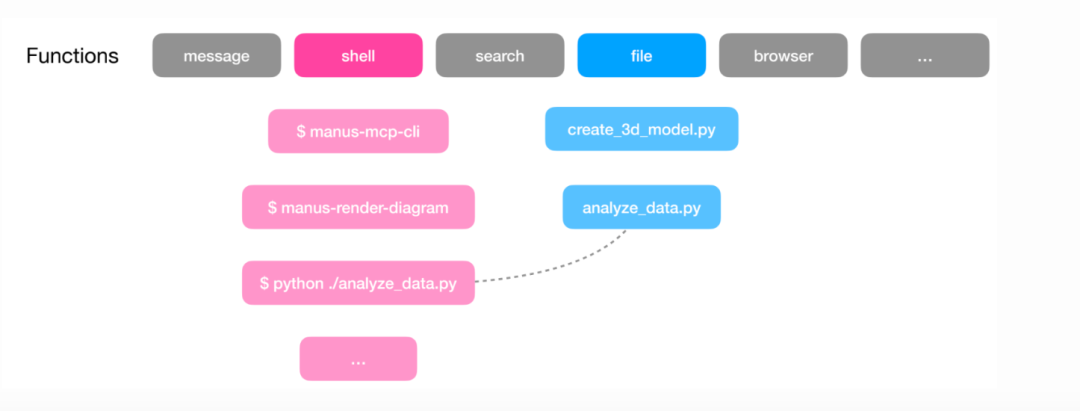
Claude 的技能功能也是类似思路:技能存储在文件系统中,而不是绑定工具,Claude 只需少量函数调用(Bash、文件系统访问)即可逐步发现和使用技能。
渐进式加载(Progressive disclosure)是智能体技能灵活可扩展的核心原则。就像一本组织良好的手册,先有目录,再有章节,最后附详细附录,技能只在需要时加载,无需一次性全部读入上下文窗口。
工具结果
由于 Manus 可以访问文件系统,它也能卸载上下文(例如工具结果)。这是上下文减少的关键:工具结果被存储到文件系统,以生成精简版本,从而裁剪掉过期 token。类似 Claude Code,Manus 使用基本工具(如 glob 和 grep)搜索文件系统,无需索引(如向量数据库)。
模型选择

Manus 不固定使用单一模型,而是按任务路由:编程任务可能用 Claude,多模态任务用 Gemini,数学或推理用 OpenAI。总体而言,模型选择主要受成本驱动,KV 缓存效率是核心因素。
Manus 使用缓存(如系统指令、旧工具结果)减少多轮智能体操作的成本和延迟。Peak 提到,分布式 KV 缓存在开源模型中难以实现,但在前沿服务提供商中支持良好。这使得前沿模型在某些智能体场景下更经济。
牢记Bitter Lesson

讨论最后,我们谈到 Bitter Lesson(苦涩经验)。我一直关注它在 AI 工程中的启示。Claude Code 创始人 Boris Cherny 提到,Bitter Lesson 影响了他让 Claude Code 保持中立设计,以便更容易适应模型升级。
持续构建在不断改进的模型之上意味着要接受持续变化。Peak 提到,Manus 自三月发布以来已经重构五次!
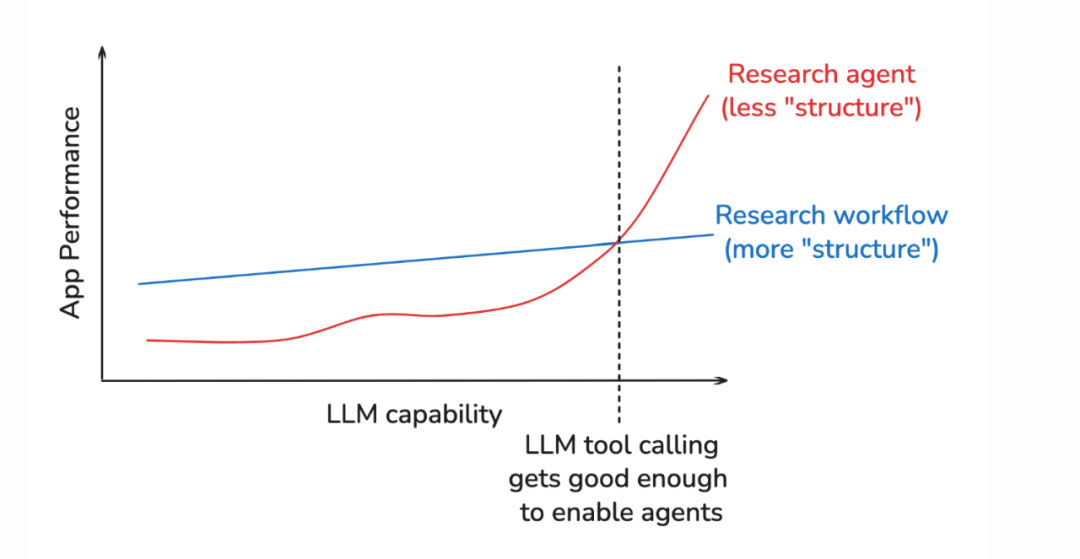
此外,Peak 提醒,智能体框架可能限制模型性能提升,这正是 Bitter Lesson 所强调的挑战:为了短期性能添加结构,可能会限制未来计算能力增长时的表现。
为防止这种情况,Peak 建议在不同模型能力下进行智能体评估。如果性能未随更强模型提升,可能是框架在拖慢智能体。这有助于检验你的智能体是否“面向未来”。
Hyung Won Chung(OpenAI/MSL)的相关演讲也强调,随着模型改进,需要持续重新评估框架(如你的 harness/假设)。
根据现有计算和数据添加必要结构,后续再移除,因为这些捷径可能成为进一步提升的瓶颈。
总结

为智能体提供计算环境(文件系统、终端、实用工具)是许多智能体常用的模式,包括 Manus。它支撑了几种上下文工程策略:
卸载上下文(Offload Context)
将工具结果存储到外部:完整结果保存到文件系统,按需用
glob、grep访问将动作推到沙箱:用少量函数调用(Bash、文件系统访问)执行沙箱中的多种工具,而不是绑定每个工具
减少上下文(Reduce Context)
精简过期结果:用引用(如文件路径)替换旧工具结果,最近结果保持完整指导决策
需要时生成总结:当精简达到边际效益递减,用 schema 对整个轨迹生成总结
隔离上下文(Isolate Context)
用子智能体完成独立任务:子智能体有自己的上下文窗口,主要为了隔离上下文
有意共享上下文:简单任务只传指令,复杂任务共享完整上下文(轨迹 + 文件系统)
最后,要确保你的框架不会限制模型提升。在不同模型能力下测试性能,简单、中立的设计往往更容易适应模型升级。随着模型改进,也不要怕重建智能体(Manus 自三月以来已重构五次)。
大模型图书推荐


塞巴斯蒂安·拉施卡|著;叶文滔 | 译
塞巴斯蒂安·拉施卡|著;覃立波,冯骁骋,刘乾 | 译
包梦蛟,刘如日,朱俊达 | 著
《大模型技术30讲》:以独特的一问一答式风格展开,从最基础的神经网络,到计算机视觉、自然语言处理,再到模型部署与评测,每一讲都围绕一个真实存在的核心问题展开思考与拆解。
《从零构建大模型》如何从零开始构建大模型的指南,通过清晰的文字、图表和实例,逐步指导读者创建自己的大模型。
《从零构建大模型习题解答》:书中内容围绕《从零构建大模型》一书的结构展开,覆盖代码和主要概念问题、批判性思维练习、单项选择题以及答案解析等内容。
《百面大模型》:大模型面试实战的代表之作。作者手把手拆解了真实的大厂大模型面试题。精选约 100 道高频真题,按照“二星到五星”难度划分,覆盖 MoE、预训练、SFT、PEFT、RLHF、DPO、RAG、智能体等关键考点,帮助读者实现从基础认知到深入思考的逐步进阶。

[沙特] 杰伊·阿拉马尔,[荷] 马尔滕·格鲁滕多斯特 | 著;李博杰 | 译
[沙特] 杰伊·阿拉马尔, [荷] 马尔滕·格鲁滕多斯特 | 著;李博杰 孟佳颖 | 译
《图解大模型》:备受关注的大模型“袋鼠书”,全书通过 300 幅全彩插图,以极致视觉化的方式呈现大模型的核心原理与工程实现,覆盖从底层机制、应用开发到性能优化的完整链条。内容结合真实数据集、实用项目与典型场景,注重实操性。
《图解DeepSeek》:2 小时搞懂 DeepSeek 底层技术。近 120 幅全彩插图通俗解读,内容不枯燥。从推理模型原理到 DeepSeek-R1 训练,作者是大模型领域知名专家 Jay & Maarten, 袋鼠书《图解大模型》同系列,广受欢迎。
Agent实战营

9 周实战,实现从 0 到 1 打造智能 Agent,从基础原理到工具调用,从协作系统到项目落地,每周直播 + 社群陪跑,明星导师李博杰亲自授课。
随买随学,所有直播都有回放。笔记、资料、拓展学习路线全打包给你。保姆级教程,你只要跟着做就能快速起飞。

AI工程抢读版

上市一周登上亚马逊计算机图书销量榜首,成为开发者与研究者口口相传的实战圣经。
如今,它依旧稳居亚马逊图书销量榜第一,被视为 AI 工程领域的必读之作。
纸质版(139.8 元) + 电子版(69.9 元)原价 209.7 元,限时特惠 139 元!

原视频观看地址:
https://www.youtube.com/watch?v=6_BcCthVvb8


















 14
14

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









