



身为一名软件从业人员,在当今时代如果还不拥抱 AI 技术,那就只能等待淘汰的命运,这已成为行业的共识而无需赘言。如此,则软件从业人员需进化为 AI 从业人员,根据其角色,则构成如下图所示的 AI 技能金字塔:
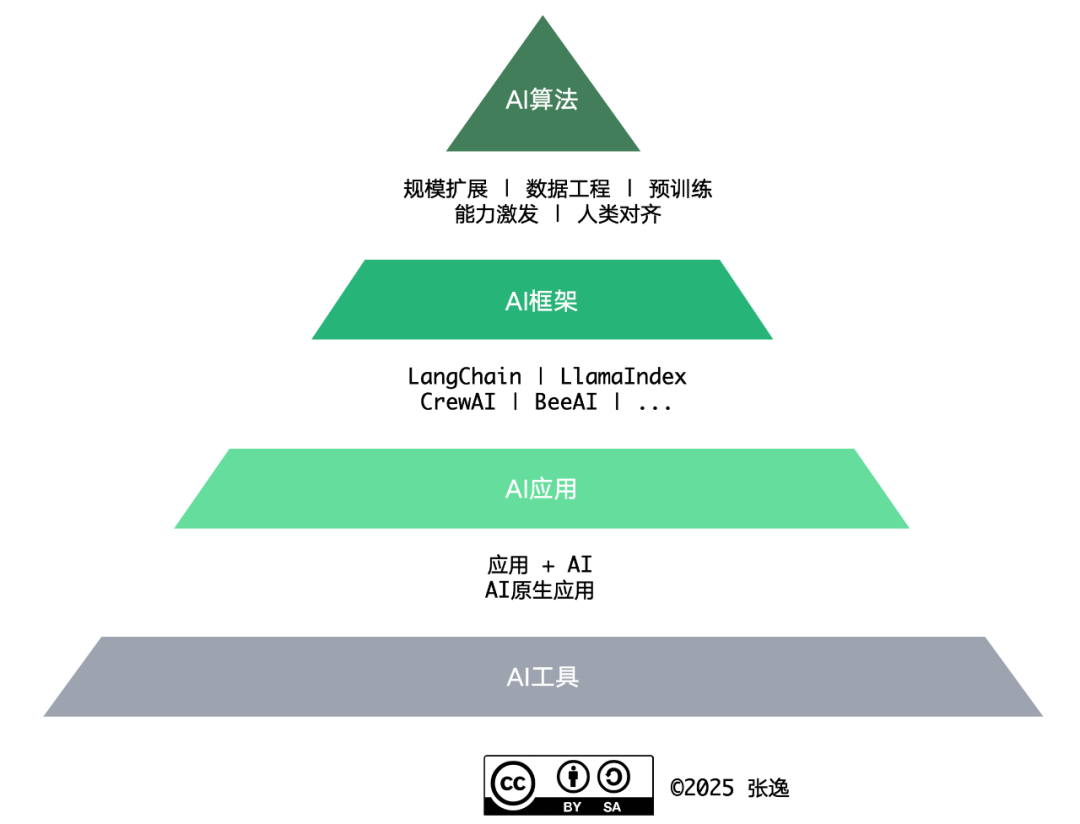
毫无疑问,对 AI 工具的使用无疑能够帮助软件从业人员尤其是软件研发人员提升工作效率,但正因为如此,如果软件从业人员仅仅是 AI 工具的使用者,就更容易被 AI 所替换。
倘若一名软件从业人员能够从事对 AI 算法的研究和研发,自然也就攀上了 AI 从业人员的金字塔尖;但要站在塔尖,又谈何容易?!虽然现在仍是 LLM 群雄并起的时代,各家发力大模型的顶尖企业都在争抢顶尖的算法人才,但毕竟具有这方面知识和能力的人才终归是凤毛麟角。因而,对于大多数软件研发人员而言,我们可能更多地还是从事 AI 应用的研发,当然也包括研发各种 AI 框架。
针对这两种角色的 AI 从业人员,还有必要深度学习大语言模型吗?我认为这一点毋庸置疑——即便我们不会参与 AI 算法的研发,也需要深入了解大语言模型的算法原理和构建过程,如此才能让我们突破“知其然”的境界,达到“知其所以然”的高度,才能更好地帮助我们理解 AI 框架,根据不同的应用场景选择适合的大语言模型,做好参数调优,并学会利用不同的技术来优化 AI 的性能,并做出正确的决策。
倘若想要系统地学习大语言模型的理论知识,可又受困于复杂的数学算法与公式,因而不得其门而入,该怎么办?以我的经验,倘若能结合阅读《图解大模型》和《从零构建大模型》这两本书,足以满足 AI 框架开发和 AI 应用开发需要的大语言模型知识了。
我将这两本书视为学习大语言模型的最佳拍档,只有这两本书双剑合璧,才能发挥最大的威力。两本书的叙述风格非常相似,虽然是讲解大语言模型理论,却完全摒弃了晦涩的数学公式和艰深的理论知识,以大量的代码案例驱动读者的学习过程,非常符合程序员的“审美习惯”。然而,两本书的侧重点又各有不同,恰好可以形成内容的互补,组合起来,就能给读者带来更多的收获。
《图解大模型》的特点是“全”,全书几乎涵盖了与大语言模型有关的主要算法以及周边的各种知识点。例如,它深入讲解 Transformer 算法中的前向传播、贪心解码,以及由自注意力层和前馈神经网络层构成的 Transformer 块,又深入讲解了与预训练大模型有关的文本分类、文本聚类和主题建模,与大模型微调有关的 BERT 模型、SetFit 框架,并着重介绍了微调文本生成模型的两种方法:监督微调和偏好调优,这其中当然还少不了 PEFT(参数高效微调)的两种方案:适配器与低秩适配(LoRA)。本书中文版还非常体贴地翻译了作者在今年发表的最新文章,为我们揭秘了 DeepSeek-R1 的训练原理。
除了这些核心理论知识与相关算法之外,本书还拓展地介绍了提示工程、RAG,并展示了如何通过 LangChain 的链式架构扩展 LLM 的能力。
所有知识点都提供了对应的代码实现,这就为读者提供了非常好的实战机会。我自己就敲入了大多数章节的代码示例,如此就能通过代码实现及输出结果观察执行过程,理解实现原理。当然,由于开发环境和版本的差异,可能需要对书中的代码做少量的微调,才能最后运行起来。
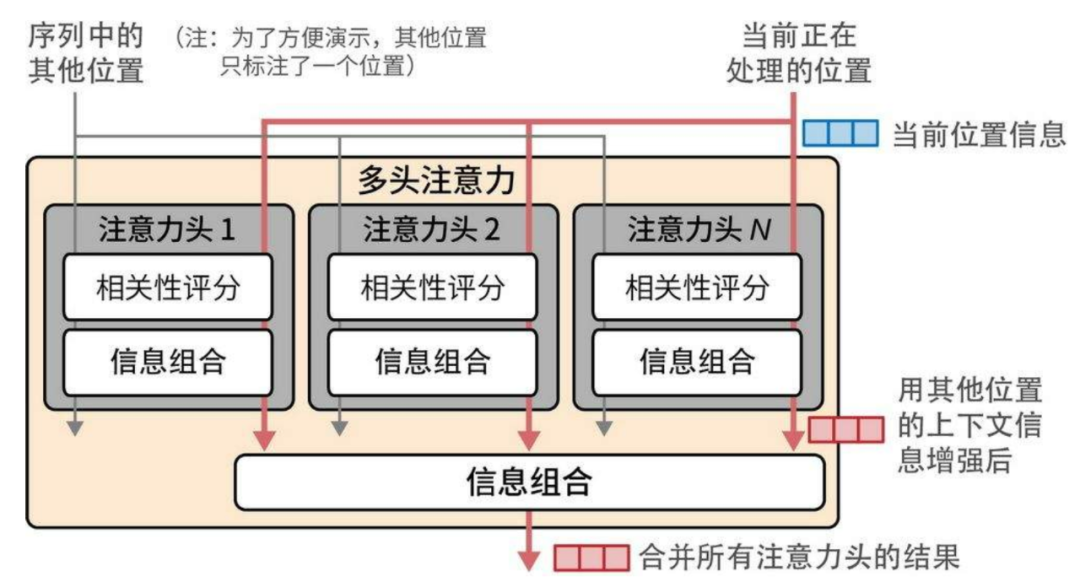
《图解大模型》一书的另一个优势就是提供了大量彩色印刷的配图,生动而形象地展现了对应的知识点。例如,演示并行执行多头注意力计算的过程:
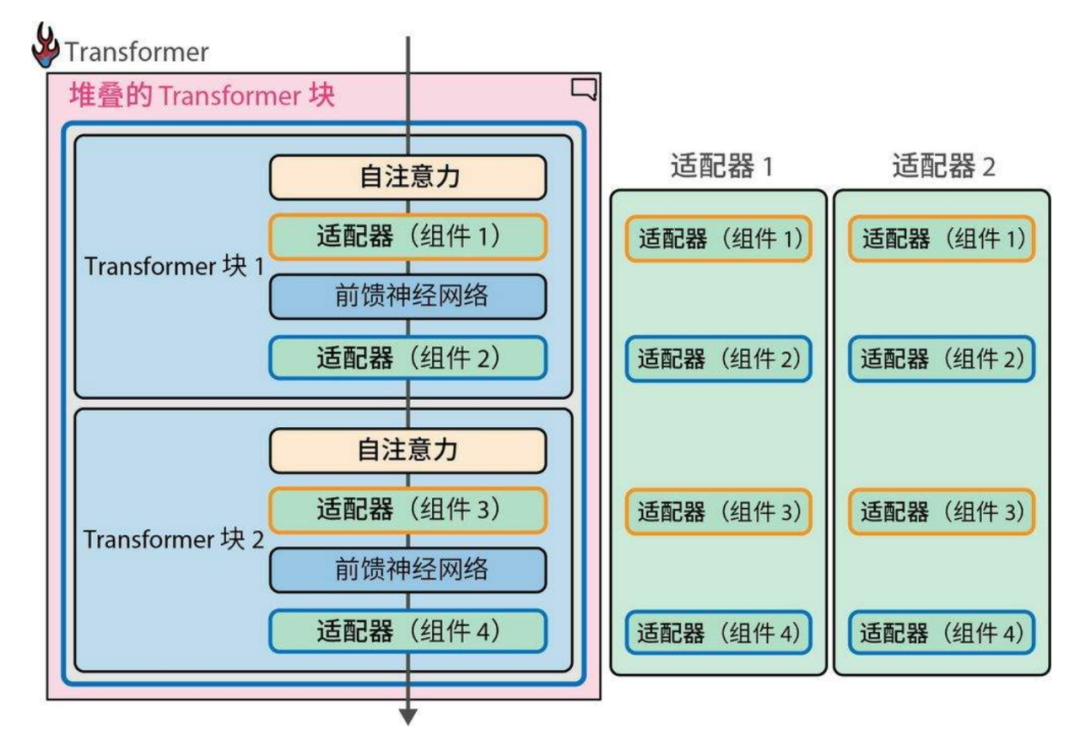
下图则非常直观地呈现了堆叠的 Transformer 块的结构:
类似这样的彩图遍布全书,既让人翻阅此书倍感赏心悦目,又让冷冰冰的科技知识变得更加有爱,更加温暖。出版社也真是舍得花血本了。
既然《图解大模型》已经如此全面,为何我还要推荐《从零构建大模型》呢?因为《图解大模型》介绍的知识虽然全面,每个知识点就如珍珠一般璀璨而美丽,可它就这般堆砌在那里,因为过于耀眼,反而让读者难以发现串联这些知识点的线索,读完之后,由于脑海积累了太多知识,反而显得有些茫然无序!若要更好地通过该书理解大模型的相关理论知识,需要你自行花费较大的精力把这些珍珠串起来,编织成更加珍贵的珍珠项链。
《从零构建大模型》则不然,它讲解的知识点确实不如《图解大模型》全面,但它的叙述目标就是帮助读者能够自行手搓一个大模型,因而把内容收敛到一个准确的边界中,并从一开始就给出了指导读者学习的路线图。该图位于该书 1.7 节“构建大语言模型”:
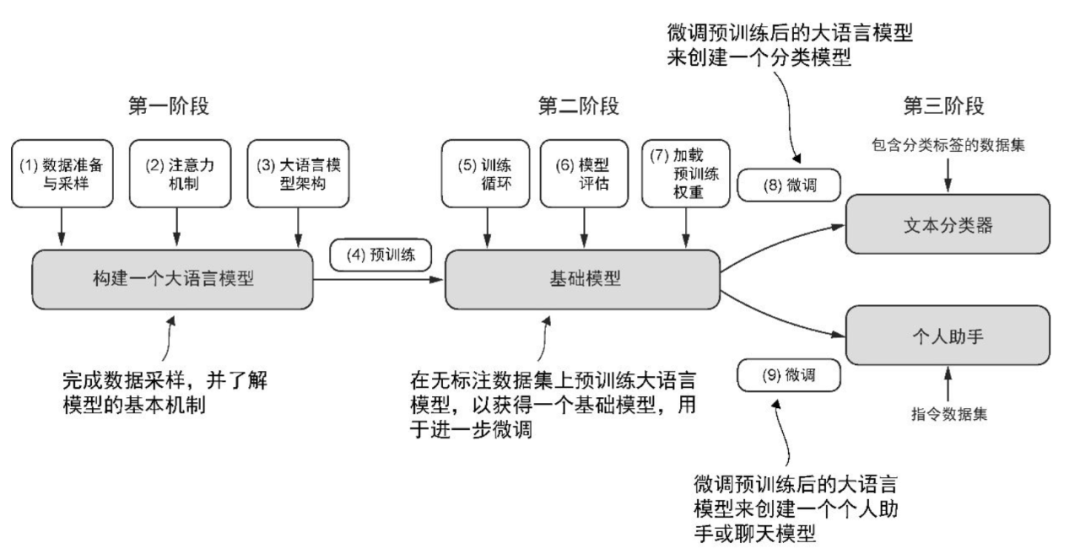
该路线图清晰地给出了构建大模型的三个阶段,并总结了 9 个步骤,对应本书第 2 章到第 7 章的内容。从第 2 章开始,每章的开头都会回顾这幅路线图,并指出当前章节的内容位于路线图的哪一个阶段哪一个步骤。以第 6 章为例,下图所示说明第 6 章的内容对应到第三阶段的步骤 8,即实现对文本分类的微调:
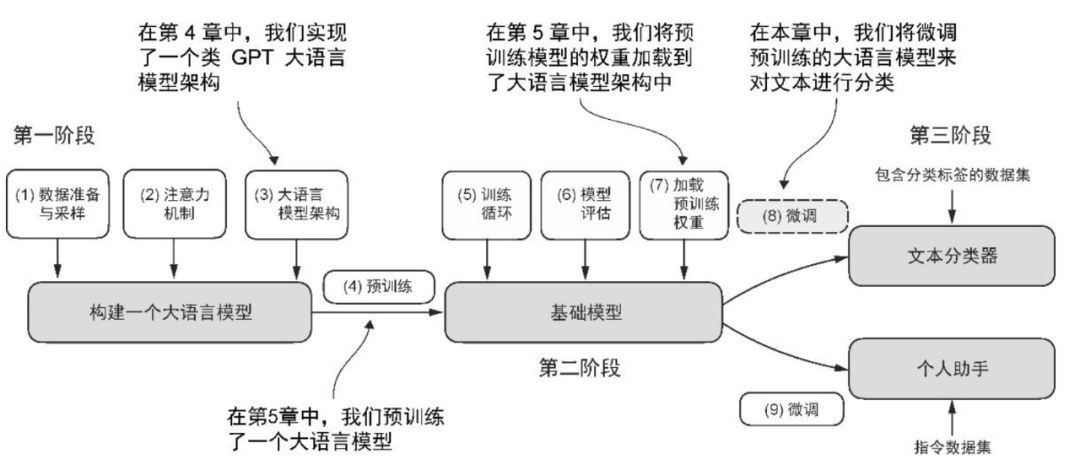
如此,读者就能按图索骥,一步一个脚印的前进,每行进一步,我们都清楚当前所处的位置,更明确前进的方向,也能回看一路前行留下的一步步脚印。
受限于它的篇幅内容,当我们发现与此路线图相关的知识点讲解得还不够详细时,又可以翻开《图解大模型》,去看看另一本书是如何讲解,彼此印证,就能加深对该知识点的印象。一路读来,不断熟悉,不断加强,或许我们也可以借鉴《从零构建大模型》的路线图,为《图解大模型》绘制一幅类似的图,帮助我们更好地理解大模型。
无论学习哪一本书,我的建议是都必须在本地环境输入书本给出的代码示例,通过运行代码,才能更好地理解整个模型的执行过程。如果只是阅读文本,难免有浮光掠影的嫌疑。
以《从零构建大模型》第 2 章讲解的“编码单词位置信息”为例,输入书中的代码后,通过观察 token embedding、positional embedding 和 input embedding 的内容,就能更好地理解书中插图要展现的如何从输入的文本编码为最终为大语言模型可理解的输入嵌入:
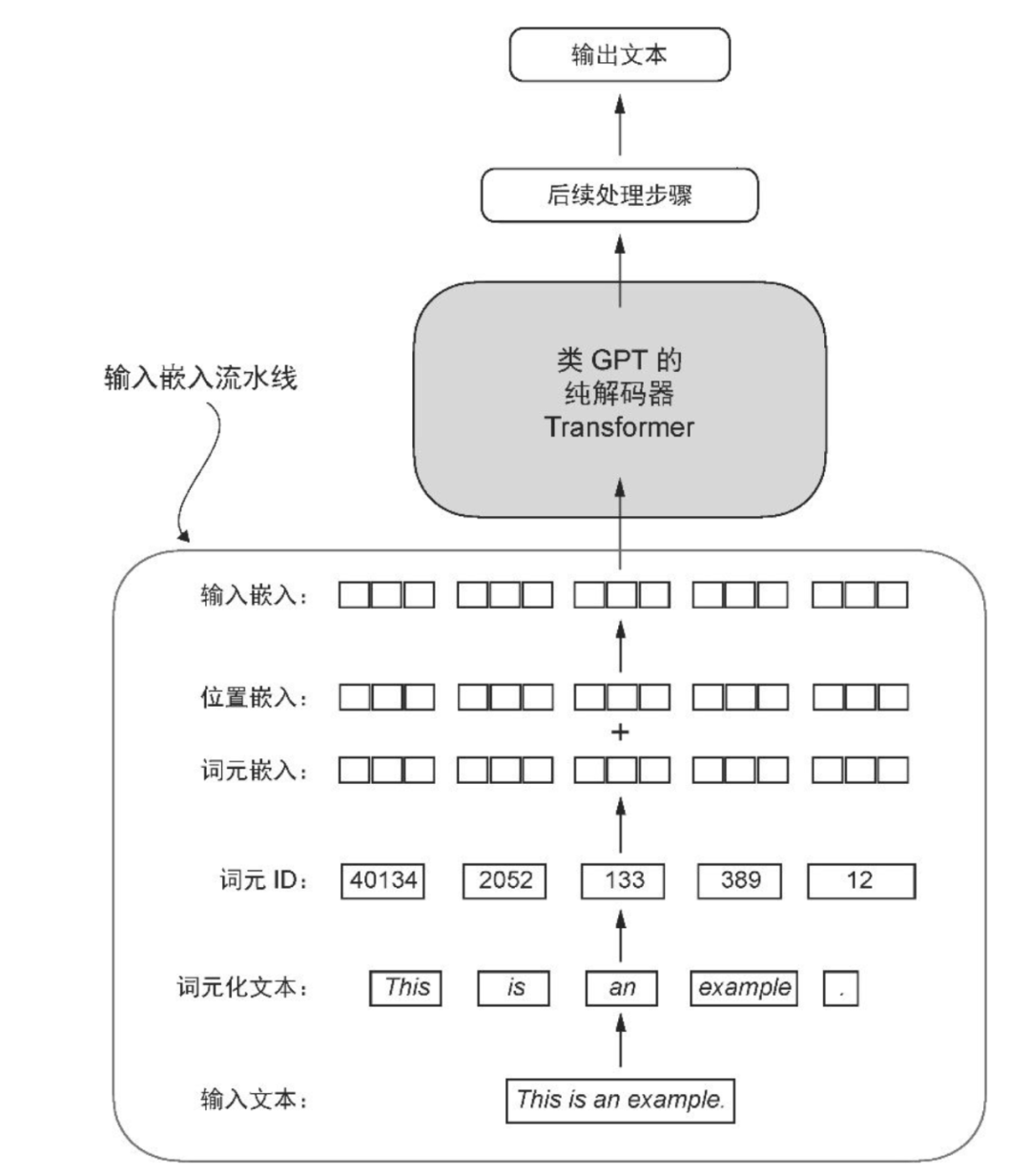
读完这两本书,我相信你已经拥有了必备的大语言模型知识。当然,这并不意味着你就可以自行创建能够媲美 DeepSeek 的大语言模型,也不意味着你能够创造新的算法,发布震撼全球的科研论文;但不可否认,掌握这些必备知识,一定能为你奠定坚实的基础,以便于进一步开展 AI 框架和 AI 应用开发,成为一名在 AI 时代能够脱颖而出的 AI 开发工程师,弄潮 AI 革命的浪潮之巅,而不是被波涛无情的吞噬。
因此,我很愿意向您推荐这两本大语言模型的佳作!
未来属于那些能站在更高层次思考、善于沟通、懂得如何指挥 AI 解决复杂问题的开发者。如果你已经走到今天这一步,其实你已经具备了大部分所需的能力。
你只需要开始学会和 AI “共舞”。说真的,这支舞一旦跳顺了,还挺有意思的。
革命不是即将到来,而是已经发生。问题只在于,你是要参与塑造它,还是被它塑造。
大模型学习不再孤单,如果不想一个人孤军奋战,快来扫码加入共学营一起学习吧👇



















 15
15

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









