



最近上海人工智能实验室在 2025 全球开发者先锋大会(GDC)上发布“以人为本”(Human-Centric Eval)评测体系,旨在解决传统大模型评测“高分低能”问题。
该体系通过模拟真实人类需求(如学术研究、决策支持等),结合人类主观反馈评估模型的实际应用价值。实验显示,DeepSeek-R1、GPT-o3-mini 和 Grok-3 在不同领域各有优势,例如 DeepSeek-R1 在生物和教育领域表现突出。这一评测思路标志着行业从单纯追求技术指标转向关注社会价值。

可以看出,人们对大模型的运用越来越关注其社会价值了。价值和风险并存,很多学者对于大模型的“欺骗性价值对齐”问题引发担忧,例如:生成误导性内容或泄露隐私数据。360 创始人周鸿祎曾提出“以模制模”方案,构建覆盖基座模型、知识库和智能体的全链路安全体系。
而对于我们小白或者刚刚开始学习大模型的读者来说,我们现在最重要的就是理清大模型的基础知识,包括大模型相关的基础知识,底层的神经网络以及自然语言处理相关的关键技术实践。
最近刚阅读完塞巴斯蒂安·拉施卡(Sebastian Raschka)的《大模型技术30讲》,这本书的作者是真是超级厉害,记得当年入门机器学习的时候,就是使用他的一本关于机器学习的图书。如今这本书新书中,有关大模型的基本技术和知识点介绍得也很不错,这里想跟大家分享一下。
内容概览
首先我们来看看这本书的内容,它深入探讨了当今机器学习和人工智能领域中最重要的 30 个问题,问题涉及神经网络、计算机视觉和自然语言处理等相关的领域,书籍结构和详细目录如下:
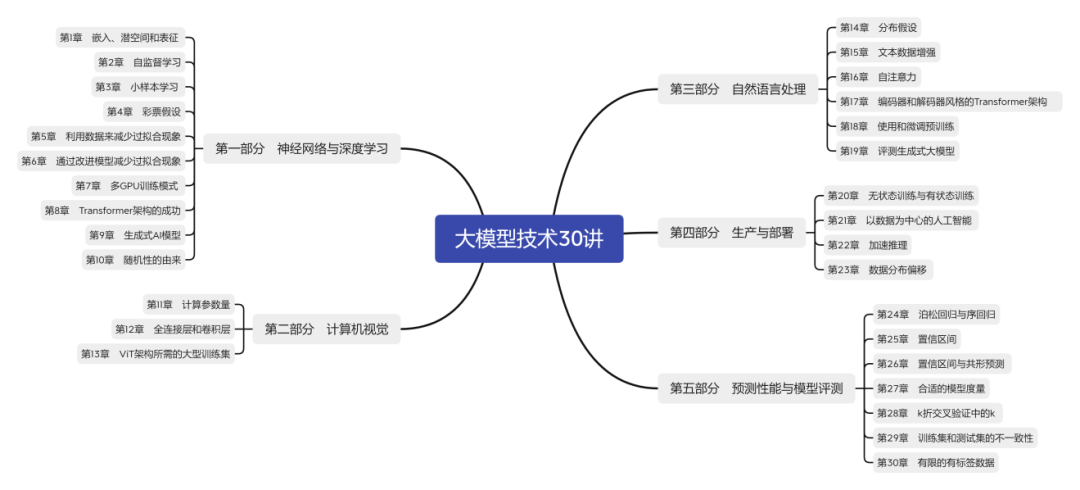
可以看出本书以“大模型技术”为核心脉络,构建了一套从基础理论到产业落地的完整知识体系。通过五大模块、30 个专题的立体化架构,系统性地展现了人工智能领域的前沿技术、工程实践与评估体系。
当然了还有一个特点,就是在每一章节的最后部分,作者都留下了一下值得思考的小问题,比如说基于 MINST 数据集如何进行小样本数据集的划分和小样本的学习。章节后的每一个问题都值得我们去研究,作者还在书的附录部分做了非常详细的解答。
理论与实践的螺旋式演进
既然我看了这本书,我就谈一下个人对这本书的感觉吧:这本书有基础、有深入、有工程也有相应的闭环内容:
基础夯实(第 1-13 章):嵌入表示与潜空间理论为深度学习奠定数学基础,结合小样本学习、多源模型等章节,解析模型如何从数据中提炼知识;数据优化与模型改进体现的辩证思维让人叹为观止,而 Transformer 架构与生成式 AI 的深度拆解,揭示了当前技术革命的底层逻辑,你现在明白 Attention 是多么伟大了吧!
领域深化(计算机视觉与 NLP):通过图像过拟合优化(第 5-6 章)、自然语言数据增强(第 15 章)等专题,渗透 CV 与 NLP 的核心挑战揭示深入理解的重要性。编码器-解码器架构(第 17 章)和文本生成评测,直击大模型在语言任务中的关键技术瓶颈,毕竟自然语言相关的技术基本上就是大模型的基础啊。
工程落地(第 20-23 章):好的大模型的工程落地肯定也是非常优秀的,这些章节讲述了从无状态训练到推理加速,构建了从实验室到生产环境的技术通路。数据分布偏移的专题分析,为工业级模型部署提供了风险预警框架。
评估闭环(第 24-30 章):置信区间将统计学严谨性注入 AI 评估,直指当前大模型验证体系的盲区。大模型的评估工作越来越多,让我们重新审视大模型给生产生活带来的优势和弊端,如何平衡两者之间的关系才是科技为民啊。
这些章节的内容技术共同对大模型相关的前沿知识进行了梳理,还提供了最佳的实践指南,可以说不管哪个大模型火,你都绕不开这 30 个核心问题!一个章节一个技术,不管在理论还是实践都非常详细,理论与实践的螺旋式演进。
章节赏析
评测大模型已从单一质量评估发展为覆盖技术、伦理、经济价值的综合体系,一般的评测维度有:
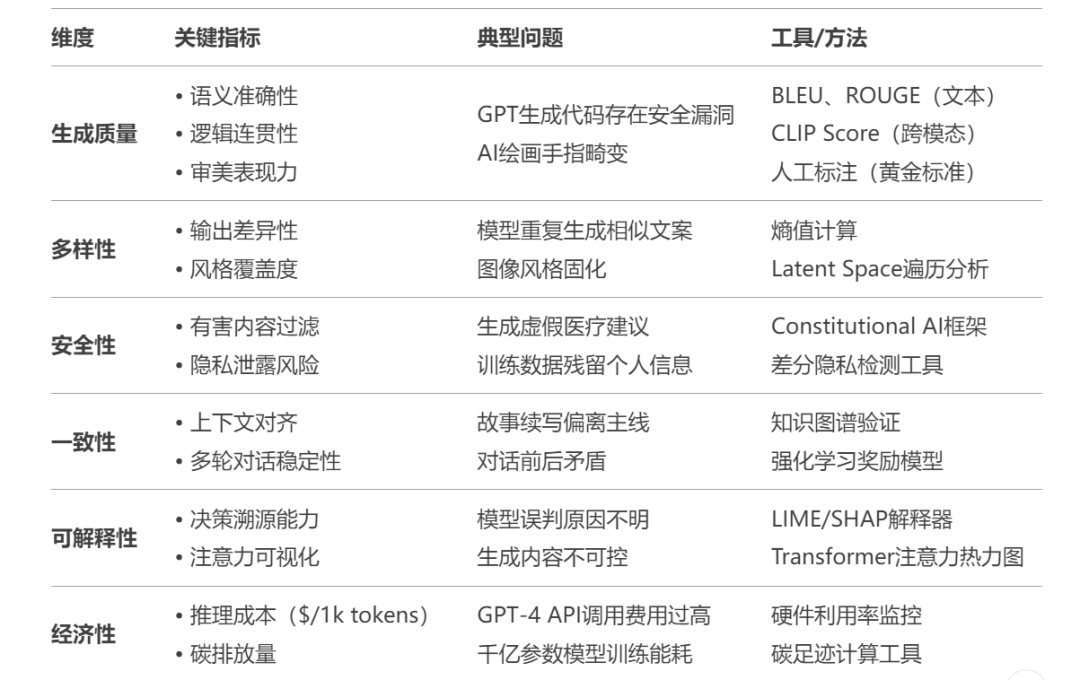
有生成质量、多样性、安全性等角度的评测,我们来看一下本书中的关于生成质量的评测,该方法是 BLEU:

可以看出,作者非常详细的解释了 BLEU 的计算步骤,通过使用简短的例子非常好地说明了如何对一个大模型的生成质量进行细致的评测,作者也针对 BLEU 方法的缺陷提出了改进方法。
这对于不了解大模型评测方法的我来说,一下子就能掌握多种评测方法以及改进的方向,所以这本书在一定程度上面对层出不穷的新模型、新概念,其提供了稳定的技术锚点。这也是我们对这本书的期待的一面。
作译者简介
作者塞巴斯蒂安·拉施卡(Sebastian Raschka) 极具影响力的人工智能专家,GitHub 项目 LLMs-from-scratch 的 star 数达 42k。 现在大模型独角兽公司 Lightning AI 任资深研究工程师。博士毕业于密歇根州立大学,2018~2023 年威斯康星大学麦迪逊分校助理教授(终身教职),从事深度学习科研和教学。 除本书外,他还写作了畅销书《从零构建大模型》和《Python机器学习》。
译者叶文滔,中国计算机学会自然语言处理专委会委员。曾任职于字节跳动、蚂蚁集团、星环科技、平安科技等互联网科技企业,负责过多个人工智能、大模型领域研发项目,并拥有多项人工智能相关专利,并著有多篇相关论文。
适合谁读
掌握大模型已经不是非常陌生的一个话题了,不管是高校学生作为能力提升还是开发者提升办公效率都是非常必要的,那这本书适合谁来读呢?
计算机科学或工程专业的学生:无论是计算机专业的学生还是软件开发者,这本书都值得一读。学习本书不需要深厚的数学或编程背景,但它能帮助你更好地理解大模型的底层技术实现。
对大模型技术感兴趣的自学者:大模型蕴含的知识就像一个浩瀚的宇宙,如果你对 LLM 或生成式 AI 充满兴趣,并希望深入探索相关领域,这本书将是你的绝佳入门指南。
大模型工程师:如果你正在从事 LLM 或大模型相关工作,这本书不仅能帮助你加深理解,还能让你在实践中温故知新,拓展思维。
扫码进群,找搭子一起交流。群里能畅聊图书内容、技术难题,还能抢先读新书,紧跟领域新进展,更有专属福利。别等了,快进群,咱们抱团学习,一起进步!



















 19
19

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









