







 本文探讨了内存屏障在多核处理器中的关键作用,涉及共享与独占状态、屏障类型(写屏障、读屏障、全能型)、以及它们在程序执行流程中的影响。重点讲解了为何CPU1在执行前后需要smp_mb(),以及内存屏障如何确保数据一致性。
本文探讨了内存屏障在多核处理器中的关键作用,涉及共享与独占状态、屏障类型(写屏障、读屏障、全能型)、以及它们在程序执行流程中的影响。重点讲解了为何CPU1在执行前后需要smp_mb(),以及内存屏障如何确保数据一致性。
读了Why Memory Barriers?中文翻译(上)这篇文章中关于内存屏障的介绍,现在有几个问题。
假设一个场景(这是上述那篇文章中的一个场景,上述文章是对 perfbook 的附录C Why Memory Barrier的翻译)
cpu0执行代码
a=1;
smp_wmb(); (写内存屏障)
b=1;
cpu1执行代码
while(b==0) continue;
assert(a==1);
在上面的代码片段中,我们假设a和b初值是0,a在CPU 0和CPU 1都有缓存,a变量对应的CPU0和CPU 1的cacheline是shared状态。b处于exclusive状态,被CPU0独占。
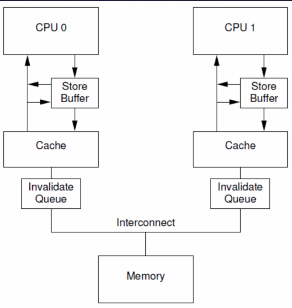
1.CPU 0执行a=1的赋值操作,由于a在CPU 0 local cache中的cacheline处于shared状态,因此,CPU 0将a的新值“1”放入store buffer,并且发送了invalidate消息去清空CPU 1对应的cacheline。
2.CPU 1执行while (b == 0)的循环操作,但是b没有在local cache,因此发送read消息试图获取该值。
3.CPU 1收到了CPU 0的invalidate消息,放入Invalidate Queue,并立刻回送Ack。
4.CPU 0收到了CPU 1的invalidate ACK之后,即可以越过程序设定内存屏障(第四行代码的smp_mb() ),这样a的新值从store buffer进入cacheline,状态变成Modified。
5.CPU 0 越过memory barrier后继续执行b=1的赋值操作,由于b值在CPU 0的local cache中,因此store操作完成并进入cache line。
6.CPU 0收到了read消息后将b的最新值“1”回送给CPU 1,并修正该cacheline为shared状态。
7.CPU 1收到read response,将b的最新值“1”加载到local cacheline。
8.对于CPU 1而言,b已经等于1了,因此跳出while (b == 0)的循环,继续执行后续代码
9.CPU 1执行assert(a == 1),但是由于这时候CPU 1 cache的a值仍然是旧值0,因此assertion 失败
10.该来总会来,Invalidate Queue中针对a cacheline的invalidate消息最终会被CPU 1执行,将a设定为无效,但素,大错已经酿成。
问题
1.在上述场景中,当到达第9步,CPU1 load a的值的时候,他并不会去它的Invalidate Queue中查看有没有关于a的消息,而直接把本地cache中的处于share状态的a值读取(此时由于Invalidate 操作尚未执行,所以a在cpu1中还处于共享状态,),所以程序会a==1为false,我的问题是CPU load的时候如果Invalidate Queue中没有设置屏障,那么cpu就不会去扫描Invalidate Queue吗。
现在对上述场景做一下修改
cpu1执行代码
while(b==0) continue;
smp_rmb(); (读内存屏障)
assert(a==1);
其他不变 perfbook 对这种场景的描述,如下(1-8)步不变
9.CPU 1现在不能继续执行代码,只能等待,直到Invalidate Queue中的message被处理完成
10.CPU 1处理队列中缓存的Invalidate消息,将a对应的cacheline设置为无效。
11.由于a变量在local cache中无效,因此CPU 1在执行assert(a == 1)的时候需要发送一个read消息去获取a值。
12. CPU 0用a的新值1回应来自CPU 1的请求。
13.CPU 1获得了a的新值,并放入cacheline,这时候assert(a == 1)不会失败了。
问题
现在在Invalidate Queue对列中加了屏障后,对列中有一个关于a的消息,那么对a的load将等待,我猜测smp_rmb(); 这条指令的意思就是说CPU不断扫描Invalidate Queue,直到关于这个关于a的操作被执行,屏障才会消失。也就是说,在load操作时,CPU是不扫描Invalidate Queue队列的,而这个动作本事正是是smp_rmb();的语义,这样理解对吗?如果现在咱们继续改变一下场景,在程序后面加一个无数据依赖关系的load操作,那么对c加载操作能否排到对a的Invalidate 消息执行之前,换句话说,如果屏障标记的东西和后续的操作无依赖关系,那么这两个动作能否重排。
cpu1执行代码
while(b==0) continue;
smp_rmb(); (读内存屏障)
d=c; (c在cpu1的Cache中并且是独占状态)
assert(a==1);
问题
1.写屏障是作用于store buffer的,标记进入写缓冲的操作顺序,使写入缓存操作按顺序执行,读屏障是作用于Invalidate Queue,标记Invalidate信号顺序,使针对同一地址的操作按序执行,不过还有一个全能型屏障,我的问题是这个全能型屏障是如何实现的,他的作用位置在哪,如果加了这个屏障,那么是在上面两组硬件中各添加一个读和写的屏障吗?
2.在cpu里还有loadStore和StoreLoad这两个barriers,那么这个屏障是怎么实现的(我现在所能理解的全部就是在store buffer中插入storeStore,和在Invalidate Queue中插入LoadLoad).
3.假设另一个场景,现在cpu0和cpu1中都存有a的值,都是share状态,并且a值已经被cpu1加载到他的寄存器中,现在cpu0申请对a值的独占权,发送Invalidate 消息到总线,cpu1接到消息,并清除cache中的a值,那么这个动作会对寄存器中的a值有影响吗?
/******************************************分界线********************************************/
知乎用户G0K17q给的回答
我建议你不要读那个文档,那个文档的作者缺乏软件架构思维(虽然知道该作者技术很牛,也没有说错什么,但在这个问题上,入题角度是有问题的),会让你越看越乱的。现在目视所有答案,基本上不着边界,可能和业界充斥这种缺乏架构思维的描述有关。
你要避免被这种文章破坏你的名称空间,推荐多读教材和Spec,这种文章可以读,但要少,要作为补充读物来读。
程序是工作在OS,编译器,物理硬件共同营造的虚拟环境中的,(在本文中,我们把这个环境称为”程序运行环境“),程序运行环境有一定的规则,不同的OS/编译器/CPU等有千万种方法来实现这个规则,但这个规则本身是不变的,我们要看到这个规则,而不是看到实现,规则和实现是交织在一起的,架构眼光就是要从所有的实现中看到不变的部分(承诺的规则)和可变的部分(实现的规则)。
先看如下程序序列:
a=1;
b=2;
c=a+b;
printf("a=%d, b=%d, c=%d\n", a, b, c);
上面这个程序序列,作用于程序运行环境的时候,环境规则能承诺的是,计算c的时候,a肯定等于1,b肯定等于2。最后打印的时候,c肯定等于3。
但它没有承诺的是:
1. a,b,c是内存上的地址(也可以是寄存器一类的东西)
2. a首先变成1,然后b才变成2
3. 如果其他设备或者CPU修改这些内存地址,反应是什么
4. 等等
所以,编译器和CPU在满足前面的规则的时候,总是玩各种小九九,在满足前面”承诺“的规则的前提下,(非有意地)破坏没有承诺的规则。
这种破坏不但出现在Cache上,还常常出现在如下位置上:
1. 编译器:编译器通过重排指令的顺序,可以充分利用寄存器和流水线,所以,编译器有可能把b=2排到a=1的前面
2. 指令调度器:指令调度器可以对指令执行的步骤进行重排,甚至可以随意修改寄存器的索引名,这会引起指令生效时间的改变
3. 指令发射器:多Issue的CPU,可以同步发出多条没有依赖的指令,这些指令的先后顺序受CPU执行影响,不一定和软件输入的一致
4. Cache系统:即使保证了指令的发射依赖,Cache到达内存的时间,也受Cache的多级调度算法影响
5. 等等
但是,程序只有一个,程序不能为你考虑你编译器的问题,不能为你考虑指令发射的问题。程序如果每下去一个操作都要想想这个操作会在cache上形成怎样的执行序列,编译器又会怎样进行编排,程序不用写了。所以,在SMP系统中,Linux增加了smp_mb()系列的操作,这些操作,在不同平台上有不同的实现,但无论是哪个实现,必须遵守新的规则:
当smp_mb()结束后,对本CPU来说,运行环境一定可以保证smb_mb()之前的内存操作已经完成,并反应到对应的内存子系统中。
同时,内存子系统中所有的未竟操作,在smp_mb()后,必须对本CPU生效。
基于这两条规则,我们很容易理解例子中的那个案例,为什么在第一个线程已经使用smp_mb()的情况下,第二个线程还需要使用一次smp_mb(),因为第一个线程只保证了这种依赖对本CPU和内存子系统生效,并不保证对第二个CPU(那个CPU有自己的Cache等运行环境系统)也生效,如果那个CPU不做smp_mb()操作,外界的这种变化就不会反应到这个CPU上。
mb()系列调用和这个类似,不过面对的是系统的CPU和IO,而不是CPU与CPU而已。
而原文举的那些Cache系统实现的各种问题,并非软件逻辑的根因。更大的问题是,实际上现代CPU的模型远远不是这里描述的样子,如果你用这个简单模型去决定如何写程序,只会什么都写不出来,这就是我为什么认为那个文档缺乏软件构架思维。
最后,作为一个证据,我贴一下ARM64的smp_mb的实现(DMB)的Spec:
Data Memory Barrier (DMB)
The DMB instruction is a data memory barrier. The processor that executes the DMB instruction is referred to
as the executing processor, Pe. The DMB instruction takes the required shareability domain and required
access types as arguments. If the required shareability is Full system then the operation applies to all
observers within the system.
A DMB creates two groups of memory accesses, Group A and Group B:
Group A
Contains:
Group B
• All explicit memory accesses of the required access types from observers in the same
required shareability domain as Pe that are observed by Pe before the DMB instruction.
These accesses include any accesses of the required access types and required
shareability domain performed by Pe.
• All loads of required access types from observers in the same required shareability
domain as Pe that have been observed by any given observer, Py, in the same required
shareability domain as Pe before Py has performed a memory access that is a member
of Group A.
Contains:
• All explicit memory accesses of the required access types by Pe that occur in program
order after the DMB instruction.
• All explicit memory accesses of the required access types by any given observer Px
in the same required shareability domain as Pe that can only occur after Px has
observed a store that is a member of Group B.
Any observer with the same required shareability domain as Pe observes all members of Group A before it
observes any member of Group B to the extent that those group members are required to be observed, as
determined by the shareability and cacheability of the memory locations accessed by the group members.
大家应该注意到,整个语义的描述,并非针对Cache的,而是基于Observation的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









