









 本文介绍了如何使用深度优先搜索(DFS)解决全排列问题。通过递归方式动态生成排列组合,避免了固定层数循环的限制。在递归过程中,通过设置递归出口避免无限循环,并通过示例代码展示了DFS如何逐步生成所有可能的排列。最后,优化后的代码将中间状态存储在结果数组中,使得输出更整洁。
本文介绍了如何使用深度优先搜索(DFS)解决全排列问题。通过递归方式动态生成排列组合,避免了固定层数循环的限制。在递归过程中,通过设置递归出口避免无限循环,并通过示例代码展示了DFS如何逐步生成所有可能的排列。最后,优化后的代码将中间状态存储在结果数组中,使得输出更整洁。
搜索本质上也是对解空间的枚举,本文介绍搜索算法中的深度优先搜索(图论)。
全排列问题
给定一个没有重复数字的序列,返回其所有可能的全排列。例如对于数列[1, 2, 3]其全排列为[[1, 2, 3], [1, 3, 2], [2, 1, 3], [2, 3, 1], [3, 1, 2], [3, 2, 1]]。
我们可以使用n层循环,每一层循环内确定一位数字,在最内层循环内判断该排列是否符合要求,例如对于数列nums = [1, 2, 3],可以写出如下代码。
for i in nums:
for j in nums:
for k in nums:
if i != j and j != k and i != k:
print i, j, k
复制代码这道题目分析到这里,其实和我的第一篇文章的问题很有很大相似的地方,但不同的是在于百鸡百钱问题的自变量个数是固定的,即循环层数是固定的。
上述代码中我们试图通过每一层循环来确定一个数值,但这段代码只适用于len(nums) == 3的情况,但是如果nums长度为4,5,或更高呢?我们无法动态生成n层循环,除非是用程序编写程序,递归为我们巧妙地解决了这个问题。
在递归中,我们则通过每一层函数的嵌套来确定一个数值,并且我们只需给出顶层的实现就够了。
于是我们得出了下面的代码(涉及python中list与set的使用)。
def solution(nums, status):
if set(nums) == set(status):
print status
for x in nums:
solution(nums, status+[x])
复制代码上述代码中,status表示当前函数层次的状态,即一个排列结果,该递归函数可以理解为一个数学表达式:solution = for + solution,那么该solution函数就会被展开为下面的样子。
for ... in range(...):
for ... in range(...):
...
if ... : print ... # 只有在第n层,条件才会成立
复制代码这就和我们最开始给出的代码看上去差不多了。但是现在代码虽然是有限的,可实际展开的时候依旧是无穷无尽的,这就需要我们为solution函数加上一个终止条件,也称递归出口。
如果把递归的过程想象成包子馅的包子,那么如果没有递归出口,这个包子将会变成馒头。
那么递归出口我们如何去定义呢?
通过题意不难推出当对于当前层,若当前排列结果status长度大于nums数列长度,即可终止递归。
于是可得出正确代码如下。
def solution(nums, status):
if len(status) > len(nums):
return
if set(nums) == set(status):
print status
for x in nums:
solution(nums, status+[x])
solution([1,2,3], [])
# [[1, 2, 3], [1, 3, 2], [2, 1, 3], [2, 3, 1], [3, 1, 2], [3, 2, 1]]
复制代码这段代码虽然可以正确运行,但我们可以让他更加美观。最终代码如下。
这一次,我们将递归出口定义在进入递归函数前,并且将中间状态记录在了ans数组中。
def solution(nums, status, ans):
if len(nums) == len(status):
ans.append(status)
for x in nums:
if x not in status:
solution(nums, status+[x], ans)
return ans
print solution([1,2,3], [], [])
# [[1, 2, 3], [1, 3, 2], [2, 1, 3], [2, 3, 1], [3, 1, 2], [3, 2, 1]]
复制代码如果在solution的开始输出status的值,我们会得到如下的输出结果。
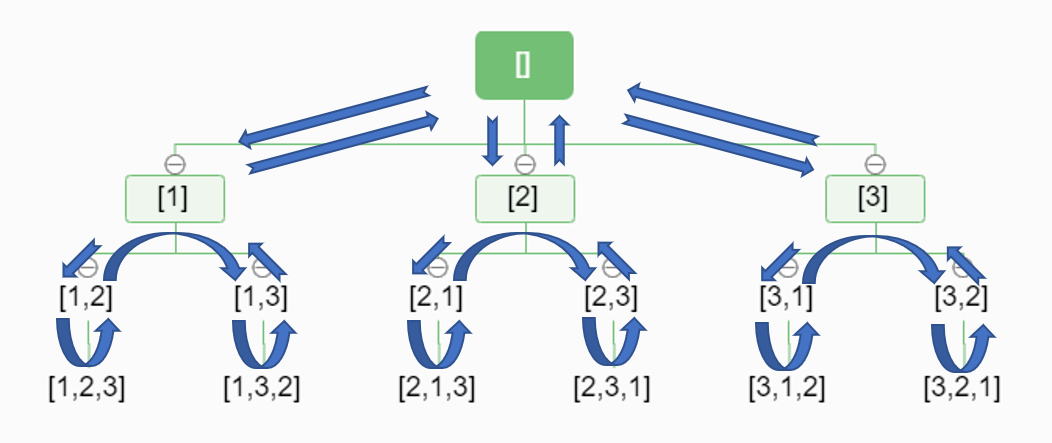
[1]
[1, 2]
[1, 2, 3]
[1, 3]
[1, 3, 2]
[2]
[2, 1]
[2, 1, 3]
[2, 3]
[2, 3, 1]
[3]
[3, 1]
[3, 1, 2]
[3, 2]
[3, 2, 1]
复制代码观察程序的输出与下面的图片,体会该迭代方法被称作深度优先搜索的原因。
本文示例题目与leecode 46.全排列一致,读者可自行尝试提交,验证自己代码的正确性。
作者:Gniqus
链接:https://juejin.cn/post/6861160844521603080
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









