




 本文探讨了多种针对预训练语言模型的微调技术,包括LoRA的低秩矩阵适应,PromptTuning的前缀添加,AdapterTuning的参数高效迁移学习,PrefixTuning的连续提示优化,以及P-Tuning的不同变体。这些方法旨在在保持模型推理效率的同时,提高特定任务的性能,且在参数量增加有限的情况下,能接近全微调的效果。
本文探讨了多种针对预训练语言模型的微调技术,包括LoRA的低秩矩阵适应,PromptTuning的前缀添加,AdapterTuning的参数高效迁移学习,PrefixTuning的连续提示优化,以及P-Tuning的不同变体。这些方法旨在在保持模型推理效率的同时,提高特定任务的性能,且在参数量增加有限的情况下,能接近全微调的效果。
PEFT(Parameter-Efficient Fine-Tuning)快速总结
针对矩阵分解的
- LoRA:把W=W0+BAW=W_0+BAW=W0+BA分解,BA的参数量级远低于W
- AdaLoRA:把LoRA换成SVD分解
针对prompt的
- PREFIX_TUNING:给prompt增加前缀,前缀用mlp结构来训练,每个任务用相同的前缀
- PROMPT_TUNING:是PREFIX_TUNING的简化,把mlp简化没了(只要预训练模型够大,难训练的问题就没有),只保留个embedding即可,每个任务用相同的前缀
- P-Tuning:prefix和prompt都是加前缀,P-Tuning直接对整个Prompt过Encoder,Encoder论文中是lstm或者mlp的结构。P-Tuning要解决的是 [X] is located in [Y], [Y] is the country of [X]之类模版带来的问题
- P-Tuning V2:只搞prompt还不够,要把Prompt token再给模型多传几层
针对self attention
- (IA)^3:缩写是Infused Adapter by Inhibiting and Amplifying Inner Activations,方法是把标准的self-attention加一些参数。给标准self-attention的K,V各hadamard product一个参数,给position-wise feed-forward层的结果也hadamard product一个参数。最后相当于对每层Transformer block都hadamard product了三个参数;另外(IA)^3还贡献了unlikelihood loss(discourages the model from predicting tokens from incorrect target sequences,来自于Improving and Simplifying Pattern Exploiting Training这篇paper,实际上就是构造一个错误序列集合,1减去和错误集合匹配的概率,最后拼成一个cross entropy的形式)和length-normalized loss(把长度的因素也评成一个cross entropy的形式)
Adapter Tuning
来自Parameter-Efficient Transfer Learning for NLP,介绍了adapter结构:首先是一个down-project层将高维度特征映射到低维特征,然后过一个非线形层之后,再用一个up-project结构将低维特征映射回原来的高维特征;同时也设计了skip-connection结构,确保了在最差的情况下能够退化为identity。
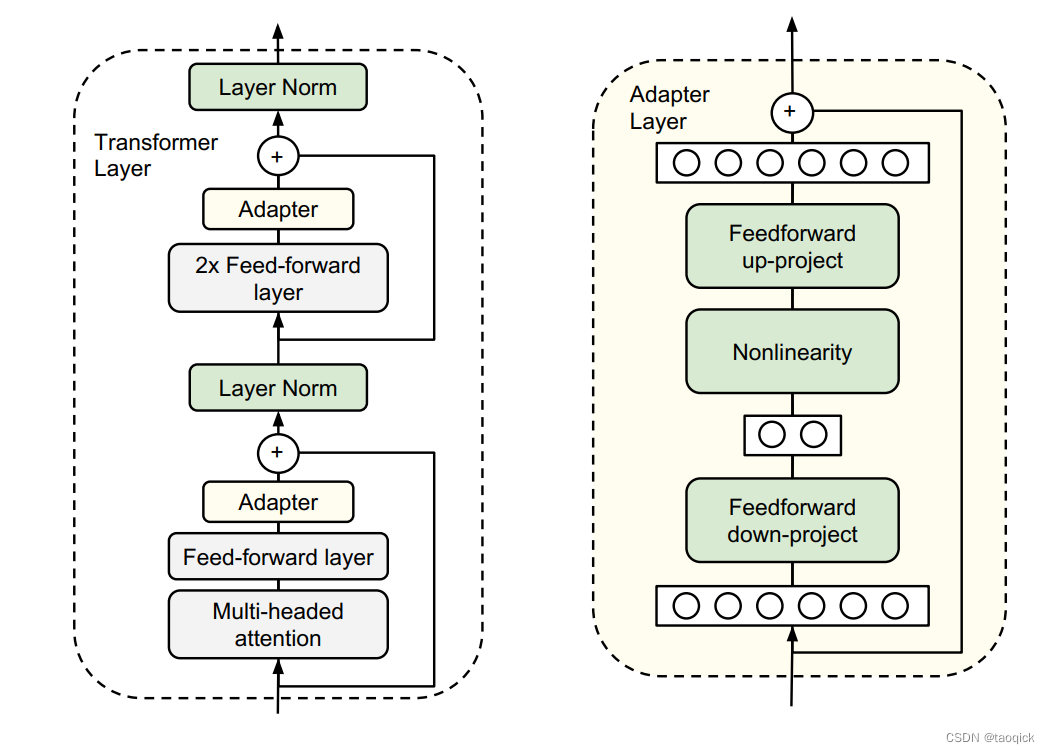
从实验结果来看,该方法能够在只额外对增加的3.6%参数规模(相比原来预训练模型的参数量)的情况下取得和Full-finetuning接近的效果(GLUE指标在0.4%以内)
Prefix Tuning
来自Prefix-Tuning: Optimizing Continuous Prompts for Generation,在输入token之前构造一段任务相关的virtual tokens作为Prefix,然后训练的时候只更新Prefix部分的参数,而Transformer中的其他部分参数固定。该方法其实和构造Prompt类似,只是Prompt是人为构造的“显式”的提示,并且无法更新参数,而Prefix则是可以学习的“隐式”的提示。
同时,为了防止直接更新Prefix的参数导致训练不稳定的情况,他们在Prefix层前面加了MLP结构(相当于将Prefix分解为更小维度的Input与MLP的组合后输出的结果),训练完成后,只保留Prefix的参数。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 789
789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









