







摘要 本报告就开源威胁情报信息抽取的工作进行汇报,参考了一些高引用量的文献、博客、论坛视频和项目,有助于深入了解威胁情报的全貌,尤其侧重于用于信息提取的大型语言模型。通过阅读本篇报告,可以了解到:
1.2015年以来非结构化威胁情报抽取的发展沿革和各时期的代表性工作
2.2023年使用LLM和PLM进行开源威胁情报信息抽取的最新工作
3.讨论LLM和SLM在网络安全领域落地的性能和成本比较
4.LLM现存的局限性和探索的解决方案
1.引言
网络威胁情报(CTI)的概念在2013年被Gartner提出[1],它是指收集、评估和应用的有关安全威胁、威胁行为者、漏洞利用、恶意软件、IOC的数据集,代表威胁的基于证据的知识。
开源威胁情报(OSCTI)是一种外部威胁情报,是指一些网络公开平台中分享的以文本报告形式呈现的情报。它的自动化识别和提取是网络安全领域的核心工作之一,可以帮助SOC人员更快了解有效信息。这一过程涉及将非结构化的OSCTI转换为标准化的格式,具体而言,包括从报告中抽取威胁行为者、漏洞利用、恶意软件、IOC的NER的任务;抽取不同实体之间关系的RE任务;以及从文档中提取安全事件的事件检测任务,最总将抽取出来的内容映射到OpenIOC、STIX等标准化开源威胁情报格式。
2.历来的工作
这一节,将介绍开源威胁情报信息抽取的三个时期的代表性工作,这三个时期是根据实现识别和抽取的技术方法的不同而划分的。分别是使用早期NLP、机器学习和关系模型构造技术的古早时代,预训练语言发展后的时代,以及如今身处的大模型时代。
2.1古早时代(2015-2020年)
非结构化CTI报告处理工作的历史并不长,网络上能找到的最早公开的非结构化威胁情报处理工具是Accenture Technology Labs在2015年Black Hat上展示的UTIP[2],现存资料只是一些吉光片羽,它使用了自然语言处理技术从非结构化文本源收集威胁情报映射到 STIX1.0。2017年的TTPDrill[3]建立在 UTIP 之上,通过基于增强BM25加权函数的TF-IDF方法度量候选项与本体中已知威胁行为之间的相似性,来实现将提取到的TTP映射到标准化框架,包括ATT&CK 和杀伤链模型,虽然作者说还想构建TTP图进一步分析并预测新的TTPs,但这个项目再没人维护过。转到2019年,微软防御研究部门的Soman在Black Hat上展示了他们的项目[4],演讲描述了构建网络实体提取器的过程,并且评估了序列标记任务常用的CRF和LSTM方法,他们展示了一个demo,能够根据上下文来识别技术和实体,如图1所示。另一个经典的工作是同年的Tram[5],它使用AI/ML模型将威胁报告在句子级别上映射到 MITRE ATT&CK 技术,他们的项目是MITRE Engenuity威胁防御中心2021年评选的13 个ATT&CK典型项目之一,项目是开源的且至今仍在维护。
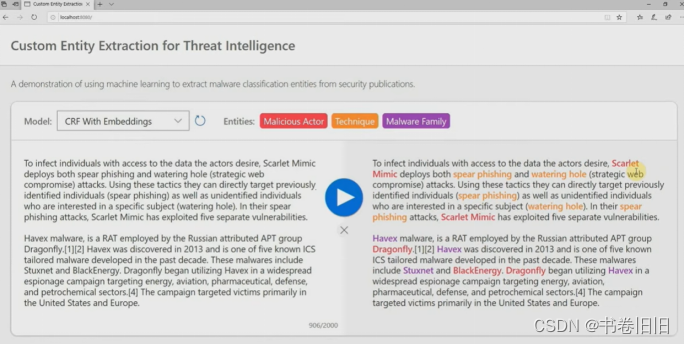
图 1 Soman在Black Hat上展示的demo
除了上述这些特别经典的项目之外,Cui等人[6]的综述,对这一时期做的工作进行了系统的调研梳理,这一时期的工作使用的方法并没有一个恰当的分类方法,通常是混合了多种技术,如图2中的部分所示。综述中指出之后的工作方向应当是融合机器学习技术与OSCTI,提升恶意软件和网络攻击的检测精度,并开发更多自动化工具来加快响应时间和提高效率。

图 2 cui等人文献中开源威胁情报识别提取相关文献分类总结对比(部分)
2.2后BERT时代(2020年-2023年)
ELMo以来的预训练语言模型发展飞快,步入预训练语言的时代,BERT于2018年被提出。“预训练+下游任务改造”的NLP第三范式,快速席卷各个垂直领域的研究,这点从国内的NLP专利布局分布就能直观看到,从2018到2020年,几乎成指数高速增长[7]。预训练方法可以通过自监督学习从大规模数据中获得与具体任务无关的预训练模型,然后用训练好的预训练模型提高下游任务的性能。
最早使用预训练语言模型来完成CTI抽取任务的代表工作是2020年Taneeya等的CASIE框架[8],它用于提取来自文本的网络安全事件信息,框架在词嵌入层加入预训练的BERT模型,相比于Domain-Word2Vec和Transfer-Word2vec性能更好,作者指出这可能是由于BERT向量更大且对上下文更敏感。此后2021年国内的Guo等人[9]利用基于内容和基于上下文的提取机制从非结构化数据中提取敏感信息的方法,使用 BERT-BiLSTM-Attention 的方法,根据上下文特征来标记文本中的敏感信息实体,可以有效地从非结构化数据中提取敏感信息。到2023年9月,作者团队又在此基础上改进[10],继而提出威胁情报提取和融合的框架,从结构化和非结构化数据中提取、关联和统一网络安全实体关系三元组,使用预训练模型BERT联合提取来生成词向量,利用BERT-BiGRU-Attention的方法提取句子特征。
这段时期还有一些使用C-GCN[11]、PCNN[12]的方法,最新的一篇2023年12月的文章,Tang等人提出了STIOCS一种结合主动学习和半监督自我训练的 IOC 提取半监督框架,通过集成CNN和RNN从CTI文本中提取局部特征和序列特征,增加CRF层利用上下文有效识别IOC实体,但从文献调研的统计结果来看,这些不使用Pre-train的方法并非2019-2023年间的主流工作。
直到现在2023年,出于对于系统可行性、效果、部署成本、数据准备难度的考虑,主流的抽取方案仍然是各种预训练语言模型的使用或者微调,表1统计了一些使用预训练语言模型较新的工作。
表1 2023年预训练语言模型相关文献
| 参考 | 时间 | 抽取内容 | 模型方法 | 数据集 | 效果 |
|---|---|---|---|---|---|
| Kashan[13] | 2024.1 | 12类CTI实体和关系联合提取 | RoBERTa-BiGRU-CRF | 852个 APT 和勒索软件报告 | 比表现最好的RoBERTa-BiLSTM-CRF基线模型F1高出 7% |
| Xiang[14] | 2023.12 | APT事件提取 | BERT-BiGRU-CRF | 130个事件信息类型的数据集,作者进行了DuEE1.0标注 | 效果优于BiGRU-CRF和BERT,F1分别高出10%和4% |
| Tanvirul[15] | 2023.11 | MITRE ATT&CK攻击模式提取 | BERT和RoBERTa和XLM-RoBERTa | 包括36 种恶意软件相关的 CTI 报告,LADDER是目前最大的有BIO标注的开源数据集 | 实体提取XLM-RoBERTa-large性能最好,F1有78.98%;RE任务BERT-large性能最好,F1有92.62%;句子级别的攻击模式提取RoBERT-large性能最好,F1有89.62% |
| Moumita[16] | 攻击技术提取 | AllenNLP SRL | BERT为语义角色标记 | 1,000 条Twitter 推文 | 是首次在现实情况下提取技术表现的研究工作,实现了 88.59% 的精确率 |
| Guo[10] | 2023.9 | STIX 对象实体和关系联合提取 | BERT-BiGRU-attention | CyberMonitor的APT报告 | 实体与关系抽取上,联合提取比传统管道模式在F1上有显著提高 |
| Marchiori[17] | 2023.9 | STIX 对象实体和关系提取 | Sentence BERT | 作者创建的开源句子数据集,包含不存在 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3474
3474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









