 AI编程提效实战指南
AI编程提效实战指南




引言:你用AI写代码多久了?
作为一名深度使用AI编程工具的技术从业者,从接触用AI辅助写代码已经差不多半年了。实话实说,体验确实超出预期——它真的帮我节省了大量时间,这一点相信试过的朋友都有同感。
作为一名爱折腾的技术人,我一直想系统体验下市面上主流大模型的实际效果、性能差异及功能侧重点。这种“折腾”精神,大概是我们这行从业者的共同特质吧。不过真要对比各家模型,就得在不同平台间来回切换,逐个注册账号、申请API Key,过程确实相当繁琐。
直到最近,我发现了一个挺不错的解决方案,只需要标准的HTTP请求就能调用主流模型,无需安装额外的SDK。目前像GPT-5、Claude 4.5和Gemini 2.5 Pro这些模型都可以直接调用,省去了不少环境配置的麻烦!
API调用实战:代码示例与效果对比
通过不同的大模型来实现对话聊天功能,show me code!
基础API配置
import requests
import json
# 平台API配置
API_BASE = "https://api.ufunai.cn/v1"
# key 替换为自己的KEY
API_KEY = "sk-xxxx"
def chat_completion(messages, model="gpt-5", temperature=0.7):
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
data = {
"model": model,
"messages": messages,
"temperature": temperature,
"max_tokens": 1000
}
response = requests.post(f"{API_BASE}/chat/completions",
headers=headers,
json=data)
if response.status_code == 200:
return response.json()
else:
raise Exception(f"API调用失败: {response.status_code} - {response.text}")
多模型效果对比
# 调用GPT-5 - 与OpenAI完全相同的请求格式
messages = [
{"role": "user", "content": "解释机器学习中的过拟合现象。要求:字数限制在200字,要通俗易懂。"}
]
response = chat_completion(messages, model="gpt-5-mini-2025-08-07")
print("\n" + "=" * 60)
print("gpt-5-mini-2025-08-07 总结:")
print(response['choices'][0]['message']['content'])
print("=" * 60)
qwen_response = chat_completion(messages, model="qwen3-coder-plus")
print("\n" + "=" * 60)
print("qwen3-coder-plus 总结:")
print(qwen_response['choices'][0]['message']['content'])
print("=" * 60)运行结果对比
GPT-5返回结果:
============================================================
gpt-5-mini-2025-08-07 总结:
过拟合是指模型在训练数据上表现很好,但在新数据(测试集)上表现差,说明它学到了噪声或特例而非普遍规律。常因模型太复杂、训练样本太少或有噪声导致。
判断方法:训练误差低但验证/测试误差高。
常用缓解措施:简化模型、增大训练集、正则化(L1/L2、dropout)、交叉验证、早停和数据增强。
============================================================Qwen3返回结果:
============================================================
qwen3-coder-plus 总结:
过拟合就像学生死记硬背答案一样。
在机器学习中,模型通过训练数据学习规律。但有时模型学得太"认真",不仅记住了数据中的真实规律,还把噪声和特殊情况也当作规律记下来了。这就导致模型在面对新数据时表现很差,因为它学到的"规律"其实并不通用。
**形象比喻**:就像考试前只做了一套练习题,结果考试时遇到稍微变化的题目就不会做了。
**典型表现**:
- 训练误差很小,测试误差很大
- 模型过于复杂
**解决方法**:
- 增加训练数据
- 简化模型复杂度
- 使用正则化技术
- 交叉验证
关键是让模型学会"举一反三",而不是"死记硬背"。
============================================================不同模型对同一问题的响应风格各异:
- GPT-5:侧重技术定义,强调过拟合的成因(如模型复杂度过高)和缓解措施(如正则化、数据增强)。
- Qwen-3:使用比喻解释(如“死记硬背的学生”),突出训练与测试表现的差异。
这种差异源于模型架构和训练数据,开发者可根据需求选择合适工具。还支持其它大模型,想玩其他模型的,代码拿去!只需要修改模型名称,直接run,感兴趣的自己去研究。
IDE集成:VSCode配置全流程
插件安装与配置
继续给大家深扒一下,如何将这把神器无缝集成到你每天都在用的开发环境里。正所谓“工欲善其事,必先利其器”,通过 RooCode 的插件,你就能在你熟悉的IDE中直接召唤这个强大的AI工具,实现真正的“AI随行”,编码如虎添翼。
目前,这款插件已经全面支持市面上主流的编程IDE,无论是轻量灵活的 VSCode、以AI为核心的 Cursor,还是新兴的 CodeBuddy、Trae 等平台,都能轻松接入。其配置过程堪称“傻瓜式”,大同小异,非常容易上手。
VSCode配置步骤
下面,我就以大家最熟悉的 VSCode 为例,手把手带你走一遍流程,让你一分钟内从零搭建起属于自己的AI编程助手。
在插件市场搜索Roo Code,然后安装。

安装完成之后,打开Roo Code,进行配置

点击之后可以看到相关的配置页面
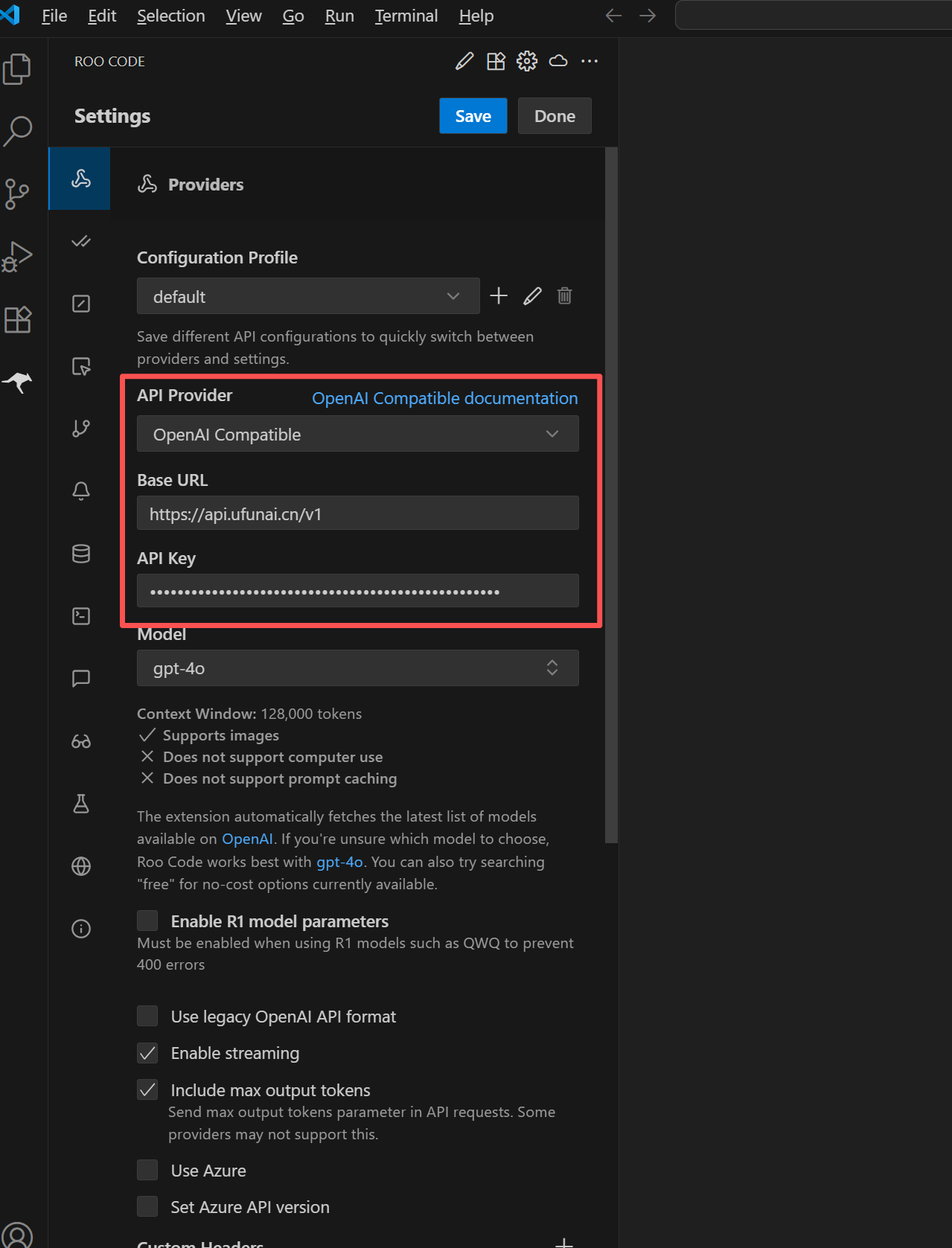
参考上面示例图
API Provider: 选择OpenAI Compatible
BaseURL填:https://api.ufunai.cn/v1 (有其他服务商的也可以)
API KEY:从上面BaseURL服务商平台上面注册获取到的密钥
Model:这里是支持的大模型列表了,你要的都有!(我用的是claude-sonnet-4-5-20250929)
下面列一部分我写代码喜欢用的模型作为示例。
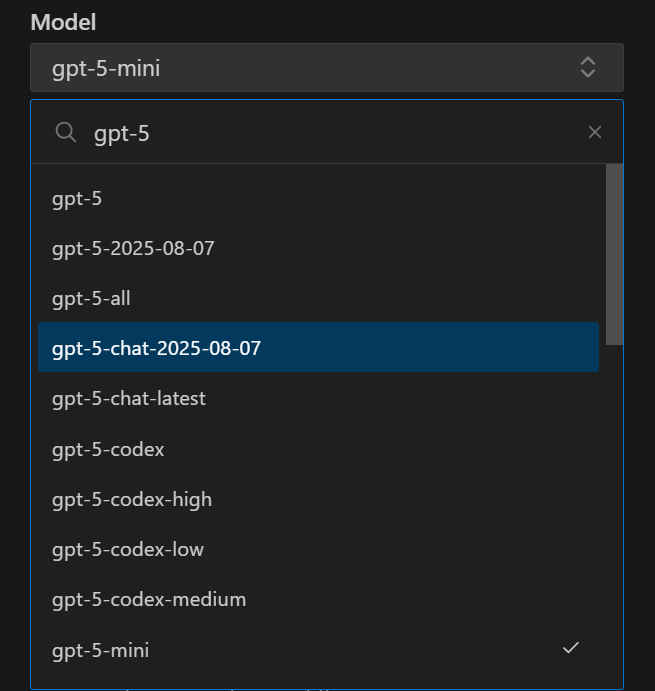
1、GPT(GPT-5整体感受还行,速度挺快)
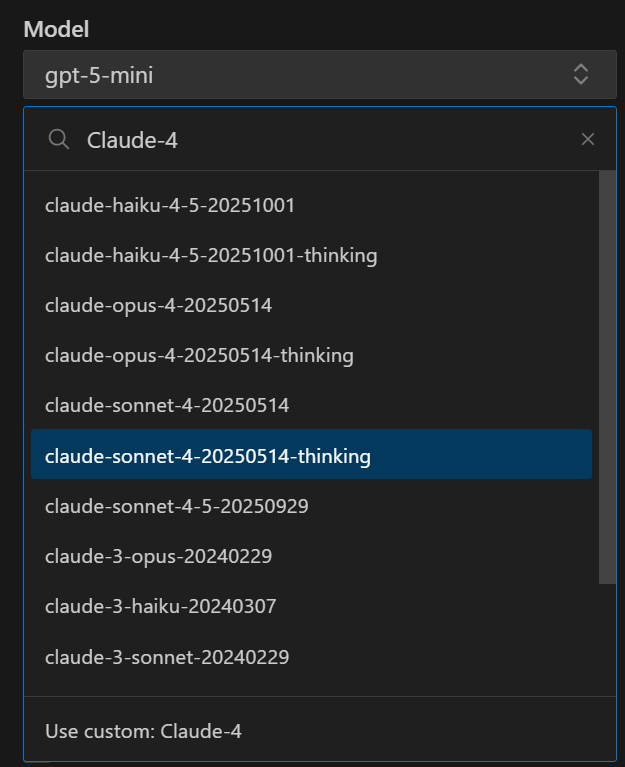
2、Claude(个人偏好,之前使用sonnet-4、现在使用sonnet-4-5,新版本比老版本快很多,优化了不少,也有可能是用的人少!嘻嘻)
3、还有其他的DeepSeek等

其他的就不列举了。基本上常用写代码的模型这里都有了。
配置完成之后点击Let's go,然后在右上角点击Save、Done

在左下角的框框中输入你的需求,然后回车,模型就开始干活了,直接生成到项目里面去,不需要你动手。
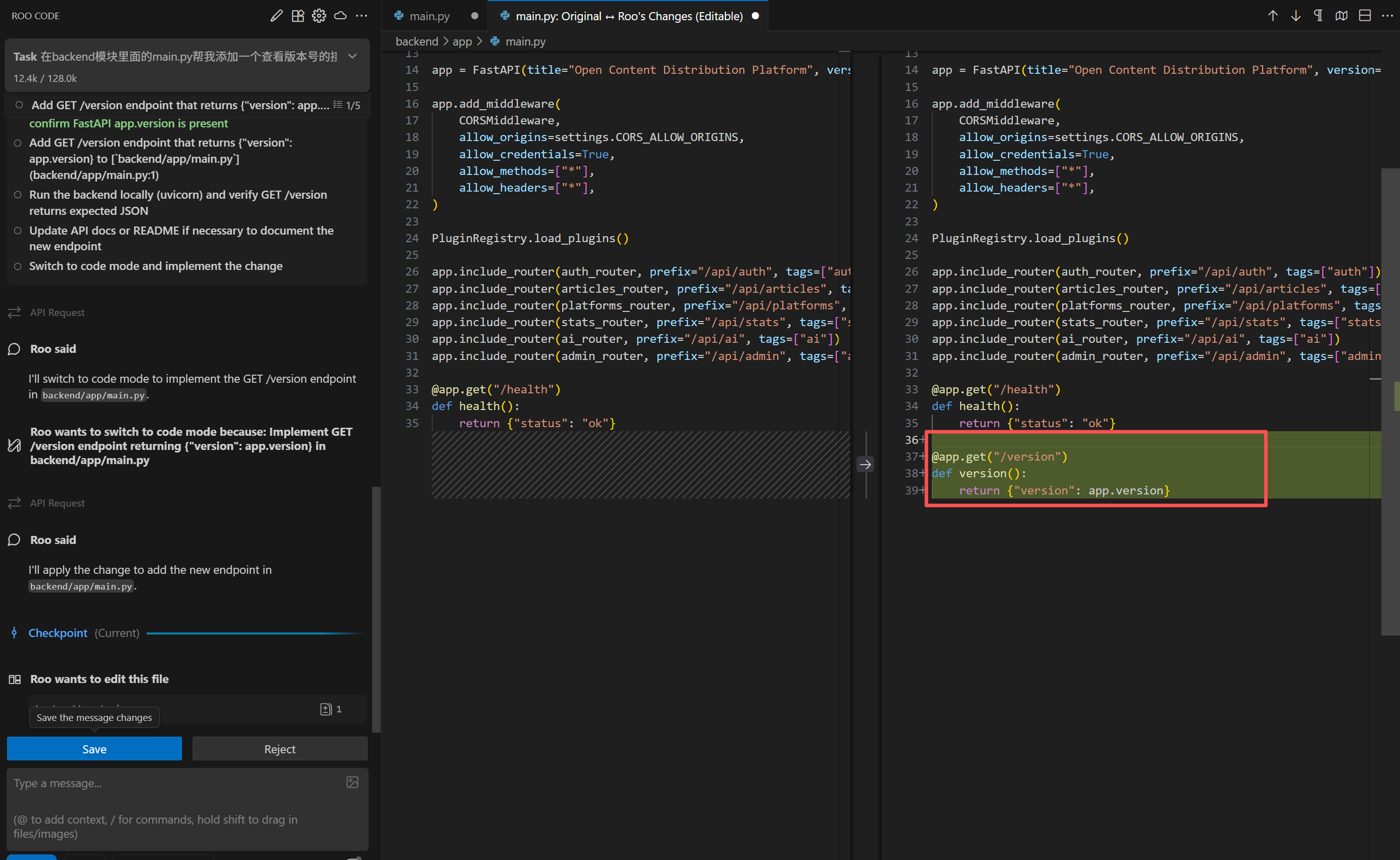
代码就生成好了,点击Save就可以了。
其他IDE都是一样的配置方式,在插件里面安装Roo Code插件就行,用AI全自动写代码,自己摸鱼,别提感觉多好了!(当然写完了,还是得自己在验证下,然后改吧改吧。)
不会现在还有全手搓写代码的把!现在工具这么多,还不会使用AI摸鱼的程序员不是好程序员!!!
后文在给大家讲怎么接入使用文生图跟文生视频,还可以接入到Dify哈!用法超级多,有创意就有无限空间,拿这个去做各种项目,接单,做独立开发者是不是又打开了一扇大门!
----------------------------------------------------- 本文完 -----------------------------------------------------
不会现在还有全手搓写代码的吧!现在工具这么多,还不会使用AI摸鱼的程序员不是好程序员!!!
创作不易,码字更不易,如果觉得这篇文章对你有帮助,记得点个关注、在看或收藏,给作者一点鼓励吧~


















 316
316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











