




开篇:为什么要用一个系列来聊LangChain?
相信很多开发者朋友和我一样,在体验了直接调用大模型API的新鲜感之后,很快会遇到一些瓶颈:
-
知识孤岛:模型的知识是静态的,无法触及私有数据和最新信息。
-
能力单一:模型很聪明,但它不会帮我查数据库、发邮件或做计算。
-
流程繁琐:想做一个能联网、能查文档的AI助手,需要写大量的胶水代码来串联各种服务。
LangChain的出现,正是为了系统性地解决这些问题。 它不是一个简单的API包装器,而是一个完整的框架(就像Java里面的Spring Boot、Spring Cloud框架),旨在帮助开发者构建由LLM驱动的、端到端的应用程序。
正因为它的能力庞大而复杂,像一本厚重的"武功秘籍",如果囫囵吞枣,很容易迷失在细节里。因此,我将它拆解成一个循序渐进的系列来给大家说:
-
第一篇(本文):打好基础,理解LangChain核心思想,掌握与模型对话的"正确姿势"——Model I/O。
-
第二篇:解锁核心应用场景,用 Retrieval 模块为模型注入私有知识,构建文档问答机器人。
-
第三篇:进入高级领域,利用 Agents 让模型学会使用工具,成为能思考、会行动的智能体。
-
第四篇:融合记忆、串联工作流,构建真正强大的AI应用。
-
第五篇:实战,构建企业级AI应用系统
目标是:每篇文章,都能掌握一个核心概念,并完成一个可运行的实战项目。 好,从第一篇开始。
一、LangChain是什么?一套构建AI应用的"乐高"
你可以把LangChain想象成一套专门为大语言模型应用设计的高级"乐高"积木。
-
在没有乐高之前(直接调用API):你得到了一堆塑料原料(模型),虽然潜力无限,但想造一座城堡,你需要自己熔化、塑形、拼接,过程极其繁琐。
-
有了LangChain之后:它为你提供了标准化的积木块(模块),如门窗、城墙、楼梯。你可以按照图纸(最佳实践),快速、灵活地拼出你想要的任何东西,从一个小屋到一座宏伟的城堡。拿来即用!
这些核心的"积木块"主要包括:
-
Model I/O:与模型通信的基础积木,负责所有"听"和"说"的环节。
-
Retrieval:与外部知识库连接的桥梁积木,让模型能"查阅资料"。
-
Agents:赋予模型决策能力的"大脑"积木,让它能自主选择使用哪些工具。
-
Chains:将多种积木组合成工作流的连接件。
-
Memory:为对话赋予上下文记忆的存储积木。
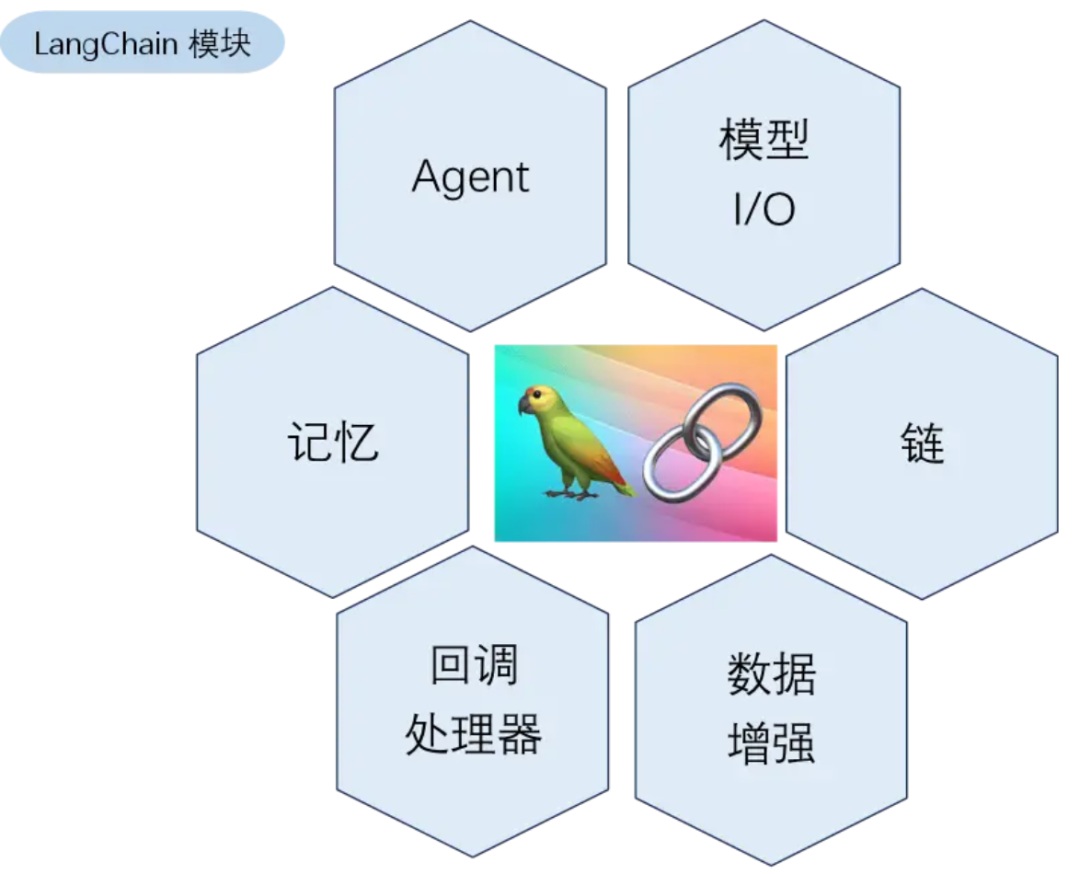
LangChain模块组成
今天,重点搭建最底层的"基础积木"——Model I/O。
二、基础理论:Model I/O —— 与模型对话的"正确姿势"
直接调用API,往往需要手动拼接提示词,并费力地解析模型返回的文本。Model I/O模块通过三个核心组件,将这个流程标准化、自动化。
1. Models(模型):选择你的"大脑"
LangChain将模型抽象为两类:
-
LLMs:接收字符串,返回字符串的纯文本补全模型(如
text-davinci-003)。 -
ChatModels:专为多轮对话设计,接收消息列表(
SystemMessage,HumanMessage,AIMessage),返回一条消息的模型(如GPT-3.5-Turbo, GPT-4)。这是我们目前最常打交道的类型。
2. Prompts(提示模板):让提问变得规范且可复用
提示模板是你不会把用户变量(如城市名)硬编码在提示词中,而是使用模板。
例如,一个读书笔记的提示模板:
# 错误示范(硬编码):
prompt = "请为《三体》这本书生成读书笔记" # 如果用户换一本书,你就得重写整个字符串
# 正确示范(模板):
template = "请为《{book_title}》这本书生成一份读书笔记,包含核心观点和关键摘录。"
prompt = PromptTemplate.from_template(template)
final_prompt = prompt.format(book_title="三体") # 只需替换变量
这样做的好处是解耦和可复用,同一个模板可以服务于无数个用户查询。
3. Output Parsers(输出解析器):让模型输出"规规整整"
模型返回的是非结构化的文本,但程序需要的是结构化的数据。Output Parser就是用来解决这个问题的。
例如,你希望模型返回一个结构化的读书笔记:
{
"book_title": "三体",
"core_themes": ["宇宙社会学", "黑暗森林法则"],
"key_quotes": ["不要回答!不要回答!不要回答!"],
"personal_insights": "对人性与宇宙关系的深刻思考"
}
Output Parser会做两件事:
-
指导格式:在提示词中明确告诉模型"请以JSON格式输出..."。
-
解析与验证:将模型返回的文本解析成Python字典或对象,如果格式错误还会自动尝试修复。
三、项目实战:构建智能读书笔记生成器
现在,我们将理论付诸实践,构建一个能返回结构化读书笔记的生成器。因为没有本地部署的大模型环境,所以本文使用大模型聚合平台(优趣AI)提供的API来调用我们需要的大模型。
项目目标:用户输入书名,程序返回一个结构化的JSON对象,包含书籍核心主题、关键观点和个人见解。
技术栈:LangChain (Model I/O)
代码如下:
import requests
import json
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import JsonOutputParser
from pydantic import BaseModel, Field
# ==================== 全局配置 ====================
# 聚合平台 http://www.ufunai.cn 配置
BASE_URL = "https://api.ufunai.cn/v1"
API_KEY = "sk-xxxxx" # 替换为你的API密钥
MODEL_NAME = "gpt-4" # 指定要测试的模型名称
# 1. 定义我们希望输出的结构化数据模型
class ReadingNotes(BaseModel):
book_title: str = Field(description="书籍标题")
core_themes: list[str] = Field(description="书籍的核心主题列表")
key_insights: list[str] = Field(description="书中的关键观点或理论")
personal_reflection: str = Field(description="阅读后的个人思考和见解")
# 2. 自定义HTTP模型类,用于LangChain集成
class HTTPChatModel:
def __init__(self, base_url: str, api_key: str, model: str = "gpt-4"):
self.base_url = base_url
self.api_key = api_key
self.model = model
def invoke(self, messages: list) -> str:
"""通过HTTP请求调用兼容OpenAI的API"""
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {self.api_key}"
}
payload = {
"model": self.model,
"messages": messages,
"temperature": 0.7,
"max_tokens": 1000
}
try:
response = requests.post(
f"{self.base_url}/chat/completions",
headers=headers,
json=payload,
timeout=300
)
response.raise_for_status()
result = response.json()
return result["choices"][0]["message"]["content"]
except requests.exceptions.RequestException as e:
print(f"HTTP请求错误: {e}")
if hasattr(e, 'response') and e.response is not None:
print(f"响应状态码: {e.response.status_code}")
print(f"响应内容: {e.response.text}")
raise
# 3. 初始化HTTP模型和输出解析器
http_model = HTTPChatModel(
base_url = BASE_URL,
api_key = API_KEY,
model = MODEL_NAME # 或您可用的其他模型
)
parser = JsonOutputParser(pydantic_object=ReadingNotes)
# 4. 构建提示模板
template = """
你是一个专业的文学评论家和读书顾问。
请为《{book_title}》这本书生成一份深度的读书笔记。
要求:
1. 分析书籍的核心主题
2. 提取书中的关键观点和理论
3. 提供有深度的个人阅读反思
请严格按照以下格式输出:
{format_instructions}
书籍名称:《{book_title}》
"""
prompt = ChatPromptTemplate.from_template(template)
# 将输出格式指示注入到模板中
prompt = prompt.partial(format_instructions=parser.get_format_instructions())
# 5. 手动实现LCEL链的功能
def execute_chain(book_title: str):
"""手动实现链式调用:提示词 -> 模型 -> 解析"""
# 第一步:构建提示词
formatted_prompt = prompt.format(book_title=book_title)
# 第二步:准备模型输入消息
messages = [
{"role": "system", "content": "你是一个专业的文学评论家和读书顾问。"},
{"role": "user", "content": formatted_prompt}
]
# 第三步:调用模型
print(" 正在生成读书笔记...")
model_response = http_model.invoke(messages)
# 第四步:解析输出
try:
parsed_result = parser.parse(model_response)
return parsed_result
except Exception as e:
print(f"解析错误: {e}")
print(f"原始响应: {model_response}")
# 6. 调用链并获取结果
try:
book_title = "人类简史" # 可以替换为任何书籍
result = execute_chain(book_title)
if "error" in result:
print(f" 处理失败: {result['error']}")
else:
print(f" 书籍: 《{book_title}》")
print("\n 核心主题:")
for i, theme in enumerate(result["core_themes"], 1):
print(f" {i}. {theme}")
print("\n 关键观点:")
for i, insight in enumerate(result["key_insights"], 1):
print(f" {i}. {insight}")
print(f"\n 个人思考:\n {result['personal_reflection']}")
except Exception as e:
print(f"处理过程中出现错误: {e}")
# 7. 额外的:直接HTTP调用示例(不依赖LangChain任何组件)
def direct_http_call_example():
"""直接使用HTTP请求的完整示例"""
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
# 手动构建提示词
prompt_text = """
请为《人类简史》这本书生成一份读书笔记,包含以下字段的JSON格式:
- book_title: 书籍标题
- core_themes: 核心主题列表
- key_insights: 关键观点列表
- personal_reflection: 个人思考
请确保输出是纯JSON格式,不要包含其他文字。
"""
payload = {
"model": MODEL_NAME,
"messages": [
{"role": "user", "content": prompt_text}
],
"temperature": 0.7,
"max_tokens": 1000
}
response = requests.post(
url= BASE_URL + '/chat/completions',
headers=headers,
json=payload,
timeout=300
)
if response.status_code == 200:
content = response.json()["choices"][0]["message"]["content"]
print("\n--- 直接HTTP调用结果 ---")
print(content)
else:
print(f"HTTP请求失败: {response.status_code}")
# 取消注释下面的行来测试直接HTTP调用
direct_http_call_example()
运行效果预览:
正在生成读书笔记...
书籍: 《人类简史》
核心主题:
1. 人类的起源和进化
2. 科技和文化的影响
3. 社会结构和政治经济的发展
关键观点:
1. 人类是如何从非洲大陆的原始生物演变成今天地球上的统治者。
2. 农业革命不仅改变了人类的生活方式,也引发了人口增长、社会分层和权力结构的变化。
3. 科技的发展,特别是在信息和生物科技领域,正在重新定义人类的生活和未来。
4. 资本主义和消费主义的兴起对人类的社会结构和环境产生了深远的影响。
个人思考:
阅读《人类简史》让我深刻反思了人类历史的发展轨迹和我们自身的责任。书中对农业革命的解读特别引人注目,它不仅改变了人类的生活方式,还加剧了社会的不平等。此外,作者对未来科技可能带来的变革提出的前瞻性见解,让我对人类的未来既感到兴奋也感到忧虑。这本书是对人类历史和未来的一次深刻的思考,也是对我们这个时代每一个人的挑战。
附直接使用HTTP调用的结果(direct_http_call_example方法执行结果):
--- 直接HTTP调用结果 ---
{
"book_title": "人类简史",
"core_themes": [
"人类的进化",
"文明的发展",
"科技的影响",
"未来的展望"
],
"key_insights": [
"从非洲大草原到全球主宰的人类旅程",
"农业革命如何改变了人类的生活方式和社会结构",
"科技和科学的发展如何塑造现代世界",
"资本主义和工业革命对社会和环境的影响",
"人类对未来的可能方向和挑战"
],
"personal_reflection": "阅读《人类简史》让我对人类历史有了更深入的理解,特别是对于农业革命和技术进步如何根本改变我们的生活方式和思维方式。书中对未来的展望也引发了我对科技发展与人类社会责任之间关系的深思。我开始思考我们作为个体在这个快速变化的世界中如何找到自己的位置,并对我们可以如何更好地影响未来持续关注。"
}
返回的是一个文本,需要使用json来对结果进行解析。相比之下,使用Model IO的方式实现的更加优雅,可复用性跟代码结构逻辑更清晰!
代码精讲:
1、自定义HTTP模型类 (HTTPChatModel):创建了一个简单的类来封装HTTP请求逻辑,使其能够与LangChain的接口兼容。
2、手动实现链式调用 (execute_chain):手动实现了LangChain LCEL的功能。
-
构建提示词:使用LangChain的模板系统
-
HTTP请求:通过自定义的模型类
-
解析输出:使用LangChain的输出解析器
3、纯HTTP示例:提供了完全不依赖LangChain组件的直接HTTP调用示例,展示底层实现。
四、总结与预告
在这一篇中,我们不仅理解了LangChain的核心价值,还深入了解了其底层HTTP通信机制。通过纯HTTP请求+LangChain组件的组合,我们既保持了灵活性,又享受了LangChain提供的便利性。
本篇核心收获:
-
LangChain的Model I/O模块提供了标准化的模型交互方式
-
即使使用纯HTTP请求,也能与LangChain的其他组件良好集成
-
输出解析器(Output Parser)是确保数据一致性的关键
-
理解底层HTTP通信有助于调试和优化应用
下一篇预告:现在,我们的读书笔记生成器还只能基于模型的已有知识。但在实际应用中,我们经常需要让它处理它没读过的书,比如你刚买的技术书籍、内部研究报告或最新的论文。
在《LangChain实战入门(二):RAG实战——赋予大模型你的私有知识库》中,我们将解锁LangChain最核心的能力之一:Retrieval。你将学会如何将私人文档(PDF、TXT)喂给模型,构建一个真正能"读懂"你指定内容的文档问答机器人!
另:需要源码的同学,请关注微信公众号(优趣AI)在留言区评论!!!
创作不易,码字更不易,如果觉得这篇文章对你有帮助,记得点个关注、在看或收藏,给作者一点鼓励吧~




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











