




在这个信息爆炸的时代,我们每个人都有大量私人数据——工作文档、邮件往来、学习笔记、研究报告等等……如何让这些沉睡的数据变得更智能,让AI真正为我们所用?今天介绍的工具LlamaIndex,正是连接大型语言模型与你私人数据的桥梁,帮你打造专属的知识库助手。
一、为什么需要专属知识库助手?
大型语言模型虽然在处理通用知识上表现优秀,但它们无法直接访问你的私人数据和最新信息。这就导致了以下问题:
-
信息滞后:模型训练数据有截止日期,无法获取最新信息
-
缺乏个性:无法根据你的特定需求和工作背景提供答案
-
数据安全隐患:将私人数据直接上传到公开平台存在泄露风险
LlamaIndex通过检索增强生成技术,让LLM能够实时检索和利用你的外部数据,既保持了模型的强大能力,又注入了你的个性化数据。
二、LlamaIndex是什么?
简单来说,LlamaIndex就是一个专门用于构建基于LLM的数据应用框架,它的核心目标是管理用户数据和LLM之间的交互。它可以接收你的输入数据并为其构建索引,随后使用该索引来回答与输入数据相关的问题。
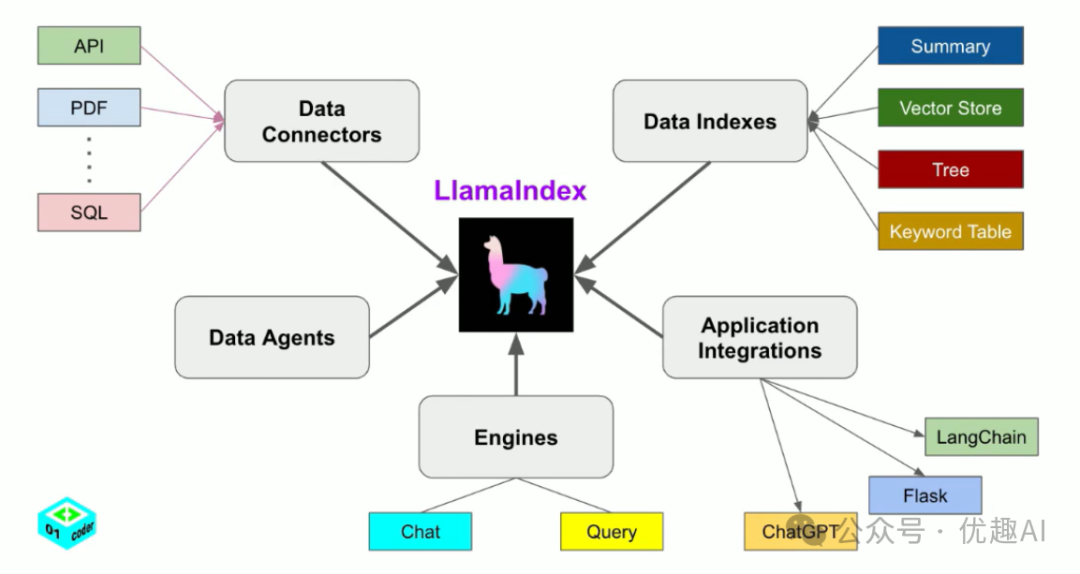
LlamaIndex工作原理
LlamaIndex使用检索增强生成系统,将大型语言模型与私有知识库相结合。它的工作流程可以分为两个主要阶段:
索引阶段:LlamaIndex将你的私有数据有效地索引为矢量索引,创建特定于你领域的可搜索知识库。无论是文本文档、数据库记录还是其他数据类型,索引都会将数据转换为捕获其语义含义的数字向量或嵌入,实现跨内容的快速相似性搜索。
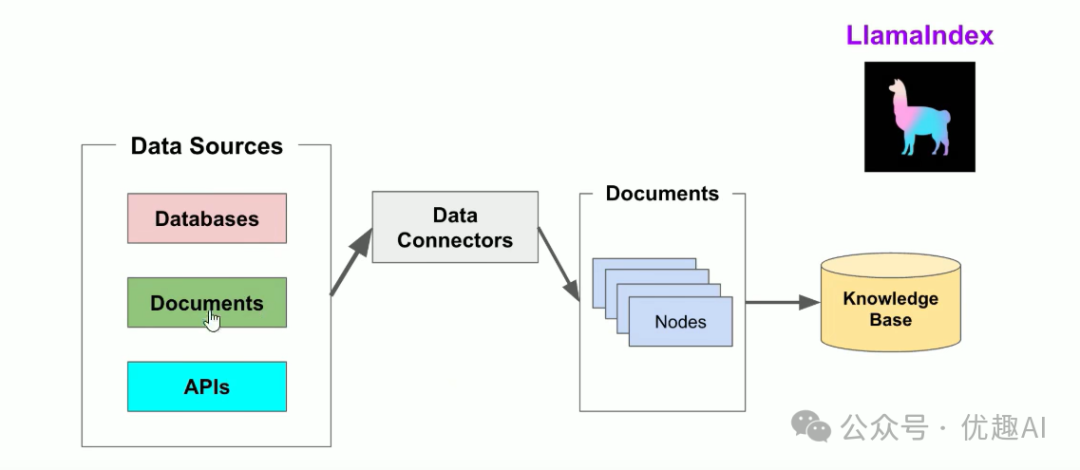
查询阶段:当用户提出查询时,RAG管道会根据查询搜索最相关的信息,然后将此信息与查询一起提供给LLM,以创建准确的响应。这个过程使LLM能够访问其初始训练中可能未包含的当前和更新信息。
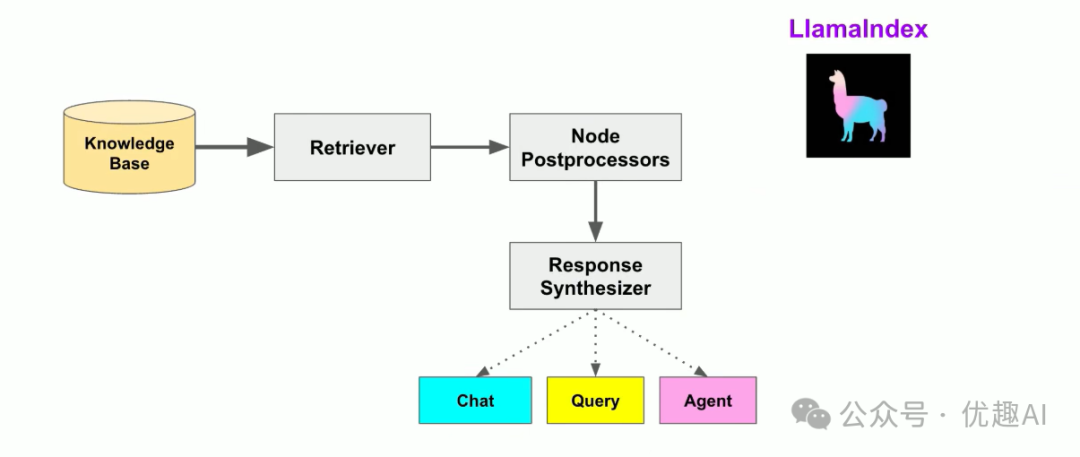
三、核心概念解析
理解LlamaIndex需要掌握以下几个关键概念:
1. 节点(Node)
在LlamaIndex中,一旦数据被摄取并表示为文档,就可以选择将这些文档进一步处理为节点。节点代表文档中的一段文本,是索引和检索的基本单位。
2. 索引(Index)
索引是LlamaIndex的核心,它能结构化数据,便于LLM使用。LlamaIndex提供多种索引方式:
| 索引类型 | 适用场景 | 技术特性 |
|---|---|---|
| VectorStoreIndex | 语义检索(默认) | 基于向量相似度搜索 |
| ListIndex | 顺序文档处理 | 线性遍历文档节点 |
| TreeIndex | 层次化数据 | 树状遍历结构 |
| KeywordTableIndex | 关键词精确匹配 | 基于关键词的检索 |
3. 检索器(Retriever)
检索器负责根据查询找到最相关的节点,它使用相似性算法来匹配查询与索引中的节点。
4. 查询引擎(Query Engine)
查询引擎是检索器和LLM的组合,它接收用户的自然语言查询,检索相关节点,然后将这些节点和查询一起发送给LLM生成最终答案。
四、实战:构建个人知识库助手
接下来,我们通过一个实际例子,展示如何使用LlamaIndex和LLM构建一个能够理解个人文档的智能助手。话不多说,直接上代码(show me code)!
环境准备
首先,安装必要的依赖包:
pip install llama_index -i https://mirrors.aliyun.com/pypi/simple/
pip install llama-index-embeddings-openai -i https://mirrors.aliyun.com/pypi/simple/
pip install llama-index-llms-custom -i https://mirrors.aliyun.com/pypi/simple/
pip install pypdf2
pip install requests完整代码实现
from typing import List, Any, Optional
import requests
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex, Settings
from llama_index.core.base.llms.types import LLMMetadata, CompletionResponse
from llama_index.core.llms import CustomLLM
from llama_index.core.embeddings import BaseEmbedding
from llama_index.core import StorageContext, load_index_from_storage
# ==================== 全局配置 ====================
# 聚合平台 http://www.ufunai.cn 配置
BASE_URL = "https://api.ufunai.cn/v1"
API_KEY = "sk-xxxxx" # 替换为你的API密钥
MODEL_NAME = "gpt-4" # 指定要测试的模型名称
EMBEDDING_MODEL = "text-embedding-ada-002" # 嵌入模型名称
# 1. 自定义HTTP模型类(用于聊天)
class HTTPChatModel:
def __init__(self, base_url: str, api_key: str, model: str = "gpt-4"):
self.base_url = base_url
self.api_key = api_key
self.model = model
def invoke(self, messages: list) -> str:
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {self.api_key}"
}
payload = {
"model": self.model,
"messages": messages,
"temperature": 0.1,
"max_tokens": 800
}
try:
response = requests.post(
f"{self.base_url}/chat/completions",
headers=headers,
json=payload,
timeout=60
)
response.raise_for_status()
result = response.json()
return result["choices"][0]["message"]["content"]
except requests.exceptions.RequestException as e:
print(f"HTTP请求错误: {e}")
if hasattr(e, 'response') and e.response is not None:
print(f"响应内容: {e.response.text}")
raise
# 2. 自定义嵌入模型类
class CustomHTTPLLM(CustomLLM):
# Declare as a field so pydantic/BaseModel won't discard it during validation
_http_model: Optional[HTTPChatModel] = None
def __init__(self, http_model: Optional[HTTPChatModel] = None, **kwargs):
# Initialize parent first (pydantic/BaseModel may perform validation that
# would overwrite instance attributes), then set the http_model explicitly.
super().__init__(**kwargs)
self._http_model = http_model
@property
def metadata(self) -> LLMMetadata:
"""返回LLM元数据"""
return LLMMetadata(
num_output=800,
model_name=self._http_model.model if getattr(self, "_http_model", None) else MODEL_NAME,
)
def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:
"""处理完成请求"""
if not getattr(self, "_http_model", None):
raise ValueError("HTTP模型未初始化")
messages = [{"role": "user", "content": prompt}]
response_text = self._http_model.invoke(messages)
return CompletionResponse(text=response_text)
def stream_complete(self, prompt: str, **kwargs: Any):
"""处理流式完成请求"""
response = self.complete(prompt, **kwargs)
yield CompletionResponse(text=response.text)
@classmethod
def class_name(cls) -> str:
return "CustomHTTPLLM"
# 3. 自定义嵌入模型
class CustomOpenAIEmbedding(BaseEmbedding):
# Declare attributes so Pydantic / BaseEmbedding recognizes them as fields.
# Allow None defaults so LlamaIndex can construct the class without passing fields.
base_url: Optional[str] = None
api_key: Optional[str] = None
model: str = EMBEDDING_MODEL
_dimension: Optional[int] = None
def __init__(self, base_url: Optional[str] = None, api_key: Optional[str] = None, model: str = EMBEDDING_MODEL, **kwargs):
# Initialize BaseEmbedding without forcing base_url/api_key into pydantic validation,
# so instantiation with an empty dict (input_value={}) won't fail.
super().__init__(**kwargs)
# Use provided values or fall back to module-level defaults
self.base_url = base_url or BASE_URL
self.api_key = api_key or API_KEY
self.model = model
# 设置其他可能需要的默认属性
self._dimension = None
@property
def dimension(self) -> int:
"""返回嵌入向量的维度"""
if self._dimension is None:
# 对于未知模型,返回一个常见维度,或者通过API探测
if "text-embedding-3-large" in self.model:
self._dimension = 3072
elif "text-embedding-3-small" in self.model:
self._dimension = 1536
else: # 默认为text-embedding-ada-002的维度
self._dimension = 1536
return self._dimension
def _get_text_embedding(self, text: str) -> List[float]:
"""获取单个文本的嵌入向量"""
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {self.api_key}"
}
payload = {
"model": self.model,
"input": text
}
try:
# 使用实例的base_url属性
response = requests.post(
f"{self.base_url}/embeddings",
headers=headers,
json=payload,
timeout=60
)
response.raise_for_status()
result = response.json()
# 保存实际维度信息
embedding_data = result["data"][0]["embedding"]
if self._dimension is None:
self._dimension = len(embedding_data)
return embedding_data
except requests.exceptions.RequestException as e:
print(f"嵌入模型请求错误: {e}")
if hasattr(e, 'response') and e.response is not None:
print(f"响应状态码: {e.response.status_code}")
print(f"响应内容: {e.response.text}")
raise
def _get_text_embeddings(self, texts: List[str]) -> List[List[float]]:
"""批量获取文本嵌入向量"""
return [self._get_text_embedding(text) for text in texts]
def _get_query_embedding(self, query: str) -> List[float]:
"""获取查询嵌入"""
return self._get_text_embedding(query)
async def _aget_query_embedding(self, query: str) -> List[float]:
"""异步获取查询嵌入"""
return self._get_query_embedding(query)
async def _aget_text_embedding(self, text: str) -> List[float]:
"""异步获取文本嵌入"""
return self._get_text_embedding(text)
@classmethod
def class_name(cls) -> str:
return "CustomOpenAIEmbedding"
# 4. 初始化配置
def setup_llamaindex():
"""设置LlamaIndex配置"""
# 初始化聊天模型
http_model = HTTPChatModel(BASE_URL, API_KEY, MODEL_NAME)
custom_llm = CustomHTTPLLM(http_model=http_model)
# 初始化嵌入模型
custom_embed_model = CustomOpenAIEmbedding(
base_url=BASE_URL,
api_key=API_KEY,
model=EMBEDDING_MODEL
)
# 设置全局配置
Settings.llm = custom_llm
Settings.embed_model = custom_embed_model
print("LlamaIndex配置完成")
return custom_llm, custom_embed_model
def create_document_reader():
"""创建文档阅读器"""
print("开始加载文档...")
# 加载数据
try:
documents = SimpleDirectoryReader(input_dir="../files").load_data()
print(f"成功加载 {len(documents)} 个文档")
except Exception as e:
print(f"文档加载失败: {e}, 当前路径下没有找到文档!")
# 创建索引
print("正在创建索引...")
index = VectorStoreIndex.from_documents(documents)
# 持久化索引
index.storage_context.persist(persist_dir="./storage")
print("索引创建并持久化完成")
return index
def initialize_chat_engine():
"""初始化聊天引擎"""
try:
storage_context = StorageContext.from_defaults(persist_dir="./storage")
index = load_index_from_storage(storage_context)
print("从存储加载索引成功")
except Exception as e:
print(f"加载索引失败,重新创建索引... 错误: {e}")
index = create_document_reader()
# 创建聊天引擎
chat_engine = index.as_chat_engine(chat_mode="condense_question", verbose=True)
return chat_engine
# 5. 主程序
if __name__ == "__main__":
print("正在初始化知识库助手...")
# 设置LlamaIndex
custom_llm, custom_embed_model = setup_llamaindex()
# 初始化聊天引擎
chat_engine = initialize_chat_engine()
print("\n" + "=" * 50)
print("知识库助手初始化完成!")
print("请输入你的问题(输入'退出'结束对话):")
print("=" * 50)
# 对话循环
while True:
user_input = input("\n你: ").strip()
if user_input.lower() in ['退出', 'quit', 'exit']:
print("助手: 再见!期待下次为您服务。")
break
if not user_input:
continue
try:
response = chat_engine.chat(user_input)
print(f"助手: {response}")
except Exception as e:
print(f"助手: 处理问题时出现错误 - {str(e)}")
代码解读
1. 自定义HTTP模型类
class HTTPChatModel:
def __init__(self, base_url: str, api_key: str, model: str = "gpt-4"):
self.base_url = base_url
self.api_key = api_key
self.model = model这个类封装了与聚合平台API的通信逻辑,支持任何OpenAI兼容的API端点。
2. LlamaIndex兼容的LLM包装器
class CustomHTTPLLM(CustomLLM):
def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:
"""处理完成请求"""
if not getattr(self, "_http_model", None):
raise ValueError("HTTP模型未初始化")
messages = [{"role": "user", "content": prompt}]
response_text = self._http_model.invoke(messages)
return CompletionResponse(text=response_text)这个类将自定义HTTP模型适配到LlamaIndex的LLM接口,使得LlamaIndex能够使用聚合平台API。
3. 配置初始化
def setup_llamaindex():
"""设置LlamaIndex配置"""
# 初始化聊天模型
http_model = HTTPChatModel(BASE_URL, API_KEY, MODEL_NAME)
custom_llm = CustomHTTPLLM(http_model=http_model)
# 初始化嵌入模型
custom_embed_model = CustomOpenAIEmbedding(
base_url=BASE_URL,
api_key=API_KEY,
model=EMBEDDING_MODEL
)
# 设置全局配置
Settings.llm = custom_llm
Settings.embed_model = custom_embed_model
print("LlamaIndex配置完成")
return custom_llm, custom_embed_model这个函数初始化整个系统,将自定义LLM设置到LlamaIndex的全局配置中。
4. 索引创建和持久化
def create_document_reader():
"""创建文档阅读器"""
print("开始加载文档...")
# 加载数据
try:
documents = SimpleDirectoryReader(input_dir="../files").load_data()
print(f"成功加载 {len(documents)} 个文档")
except Exception as e:
print(f"文档加载失败: {e}, 当前路径下没有找到文档!")
# 创建索引
print("正在创建索引...")
index = VectorStoreIndex.from_documents(documents)
# 持久化索引
index.storage_context.persist(persist_dir="./storage")
print("索引创建并持久化完成")
return indexLlamaIndex会自动处理文档的分块和向量化,创建可搜索的索引,并持久化保存以避免重复处理。
五、程序运行效果
启动系统
正在初始化知识库助手...
LlamaIndex配置完成
加载索引失败,重新创建索引... 错误: [Errno 2] No such file or directory: 'E:/Py-Spaces/PythonProject/ai_project/llamaIndex/storage/docstore.json'
开始加载文档...
成功加载 1 个文档
正在创建索引...
索引创建并持久化完成
==================================================
知识库助手初始化完成!
请输入你的问题(输入'退出'结束对话):
==================================================
交互示例
你: 我前段时间参加了什么大会
Querying with: 我前段时间参加了什么大会
助手: 根据提供的信息,您前段时间参加了“2025人工智能技术大会”。
你: 帮我用100字总结下
Querying with: 请帮我用100字总结一下我前段时间参加的2025人工智能技术大会。
助手: 2025人工智能技术大会给我留下了深刻印象。大会汇聚了全球领先的AI专家,展示了最新的技术进展和应用场景。讨论的主题包括人工智能在各行业的创新应用、未来发展趋势以及伦理挑战。通过与业内人士的交流,我对AI的未来前景和技术发展有了更深入的理解,也激发了我在AI领域进一步研究的兴趣。总体来说,这是一次非常有启发性的大会。
你: 退出
助手: 再见!期待下次为您服务。六、高级功能:优化检索效果
为了获得更好的检索效果,我们可以对代码进行一些优化(提供思路哈):
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core import ServiceContext
def create_optimized_index():
"""创建优化后的索引"""
# 加载文档
documents = SimpleDirectoryReader("./Private-Data").load_data()
# 配置节点解析器
node_parser = SentenceSplitter(
chunk_size=512,
chunk_overlap=50,
separator="\n"
)
# 创建服务上下文
service_context = ServiceContext.from_defaults(
llm=Settings.llm,
node_parser=node_parser
)
# 创建优化索引
index = VectorStoreIndex.from_documents(
documents,
service_context=service_context
)
return index七、使用场景与技巧
1. 文档问答系统
你可以上传产品手册、技术文档,构建一个智能问答系统,快速查找相关信息。
2. 个人知识管理
将你的学习笔记、研究资料归档,打造属于你个人的第二大脑。
3. 邮件智能处理
分析你的邮件历史,快速找到特定主题的往来邮件或附件。
当然不仅仅局限于这些场景哈!~~
优化技巧
-
分块策略:技术文档适合较小的块(256-512字符),文学内容可以适当增大
-
重叠设置:设置适当的块重叠(chunk_overlap)保持上下文连贯
-
元数据增强:为文档添加创建时间、类型等元数据
八、总结
通过学习LlamaIndex,我们可以:
-
激活数据价值:让沉睡的私人数据变成有价值的智能资源
-
保持数据安全:私有数据始终掌握在自己手中
-
享受个性化服务:获得真正贴合个人需求的智能助手
-
灵活选择模型:不受特定厂商限制,选择最适合的模型服务
无论是个人用户想要高效管理自己的信息,还是企业希望构建内部知识库系统,LlamaIndex配合LangChain提供了一个可靠且灵活的解决方案。它降低了使用大型语言模型处理私人数据的门槛,让我们每个人都能打造属于自己的智能知识库助手。
本文完,接下来给大家说MCP!(*∩_∩*)
另:需要源码的同学,请关注微信公众号(优趣AI)在留言区点赞留言评论!!!
AI应用开发入门到精通宝藏地图,理论+实战往期精彩文章
2、一文看懂Embedding:用代码给大家讲清这个核心概念
3、告别接力!Transformer的「圆桌会议」才是AI的高效沟通术
7、函数调用:让AI学会使用工具,从“思考者”变身“行动派”
8、LangChain实战入门(一):告别“裸调”API,从Model I/O开始优雅构建AI应用
9、LangChain实战入门(二):RAG实战——赋予大模型你的私有知识库
10、LangChain实战入门(三):Agents实战——让AI成为能思考、会行动的数字员工
11、LangChain实战入门(四):融合篇——打造有记忆、能协作的AI应用
12、LangChain实战入门(五):项目篇——构建企业级AI应用系统
创作不易,码字更不易,如果觉得这篇文章对你有帮助,记得点个关注、在看或收藏,给作者一点鼓励吧~~


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











