






目录
1.程序功能描述
LSTM网络的性能高度依赖于超参数配置,其中隐含层个数是影响模型性能的关键超参数之一。传统的超参数优化方法如网格搜索、随机搜索存在效率低、易陷入局部最优等问题。鹈鹕优化是一种新型元启发式优化算法,其核心是用鹈鹕优化算法(Pelican Optimization Algorithm, POA)自适应搜索LSTM隐含层最优神经元数量,以最小化时间序列预测误差。
2.测试软件版本以及运行结果展示
MATLAB2022A/MATLAB2024B版本运行
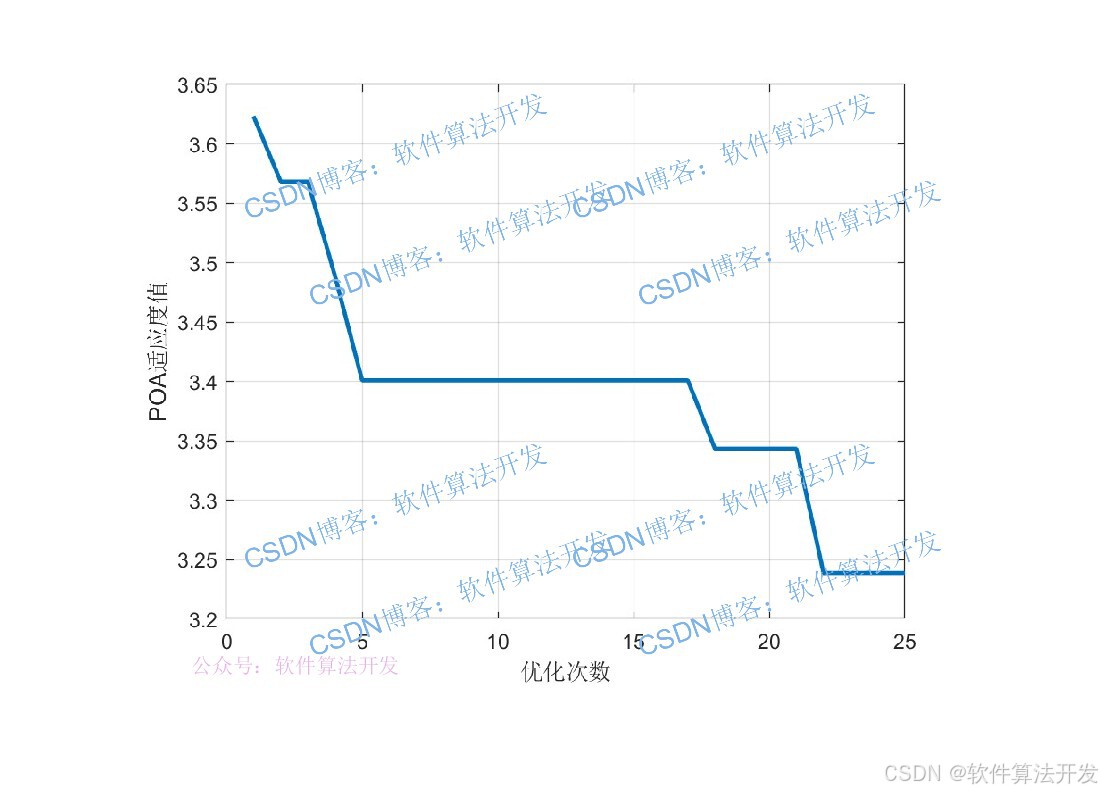
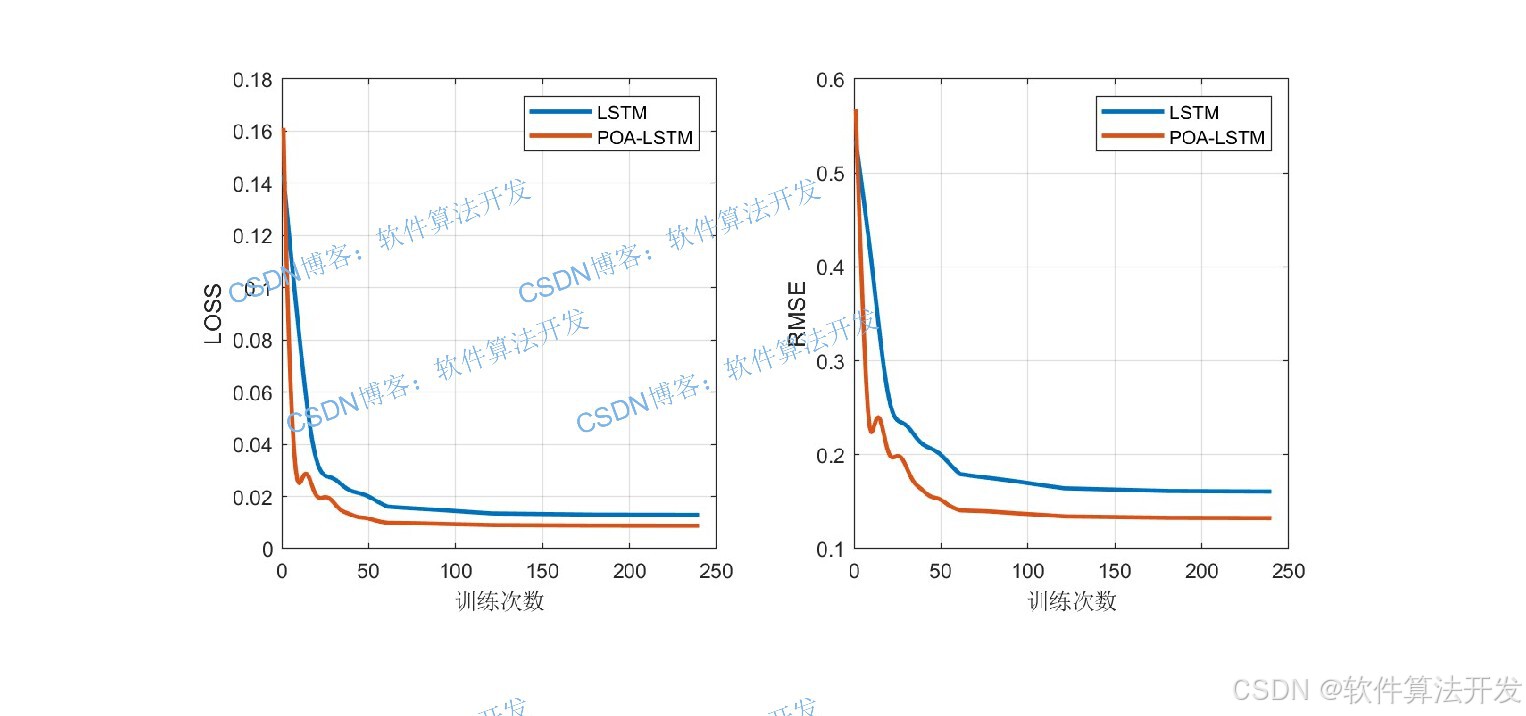
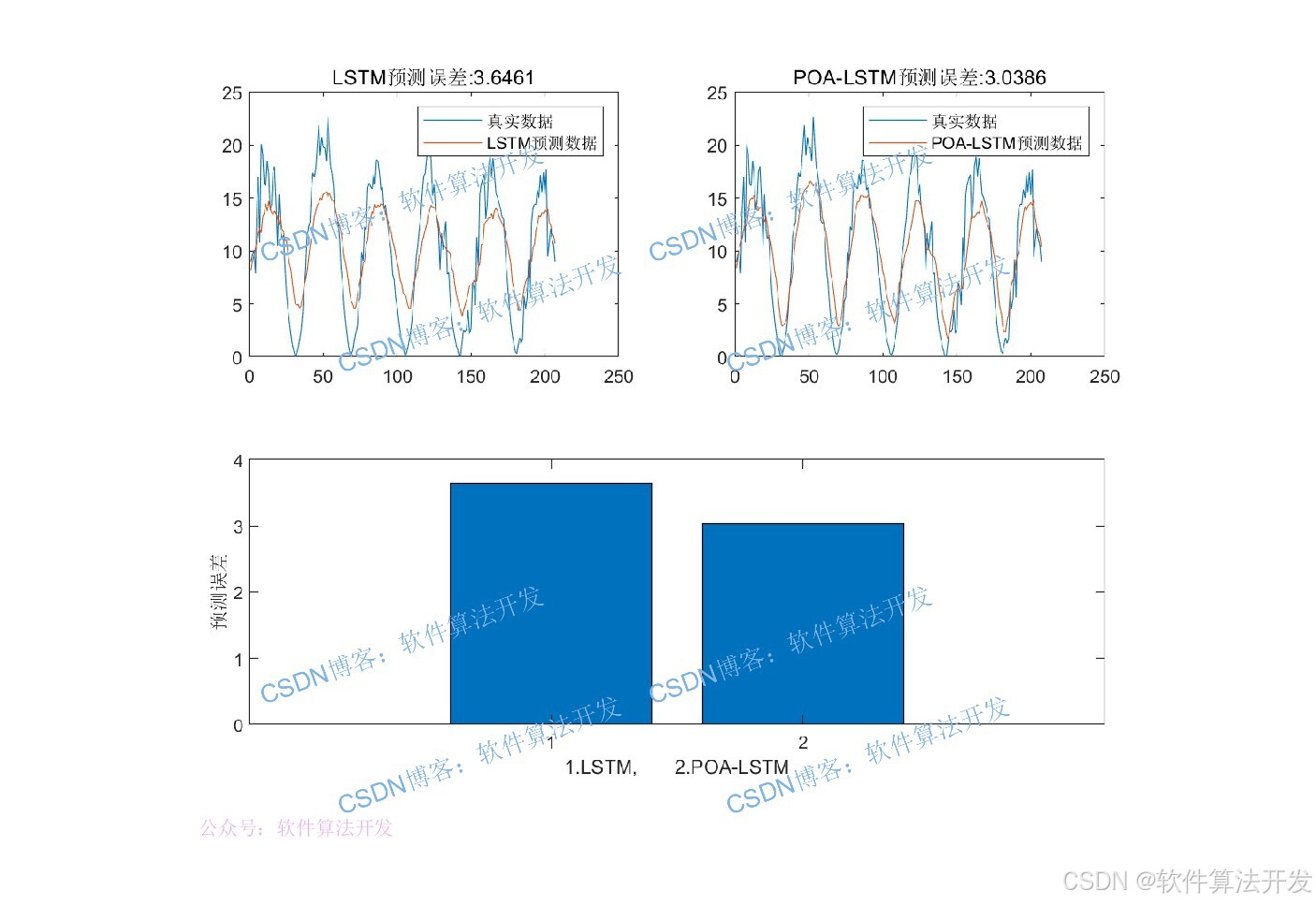
3.部分程序
...................................................................
Destination_position=BestSol.Position;
% 将优化得到的最佳参数转换为整数,作为LSTM隐藏层神经元数量
% 加1是为了确保至少有1个神经元
NN=floor(Destination_position)+1;
% 设置网络训练参数
options = trainingOptions('adam', ... % 使用Adam优化器,适合深度学习训练
'MaxEpochs', 240, ... % 最大训练轮数为240
'GradientThreshold', 1, ... % 梯度阈值为1,防止梯度爆炸
'InitialLearnRate', 0.004, ... % 初始学习率为0.004
'LearnRateSchedule', 'piecewise', ...% 学习率调度方式为分段衰减
'LearnRateDropPeriod', 60, ... % 每60轮衰减一次学习率
'LearnRateDropFactor',0.2, ... % 学习率衰减因子为0.2(变为原来的20%)
'L2Regularization', 0.01, ... % L2正则化系数为0.01,防止过拟合
'ExecutionEnvironment', 'gpu',... % 使用GPU加速训练(需配置GPU支持)
'Verbose', 0, ... % 不显示训练过程细节
'Plots', 'training-progress'); % 显示训练进度图表(损失变化等)
% 训练LSTM网络
[net,INFO] = trainNetwork(Pxtrain, Txtrain, layers, options);
% 使用训练好的网络进行预测
Dat_yc1 = predict(net, Pxtrain); % 对训练数据进行预测(归一化尺度)
Dat_yc2 = predict(net, Pxtest); % 对测试数据进行预测(归一化尺度)
% 将预测结果反归一化,恢复到原始数据范围
Datn_yc1 = mapminmax('reverse', Dat_yc1, Norm_O);
Datn_yc2 = mapminmax('reverse', Dat_yc2, Norm_O);
% 将细胞数组转换为矩阵(方便后续处理和分析)
Datn_yc1 = cell2mat(Datn_yc1);
Datn_yc2 = cell2mat(Datn_yc2);
% 保存训练信息、预测结果和收敛曲线到MAT文件,便于后续分析
save R2.mat INFO Datn_yc1 Datn_yc2 T_train T_test Convergence_curve
1264.算法理论概述
POA-LSTM的核心是用鹈鹕优化算法(Pelican Optimization Algorithm, POA)自适应搜索LSTM隐含层最优神经元数量,以最小化时间序列预测误差。
整体流程为:
数据预处理→POA优化LSTM超参数→训练优化后的LSTM→预测与结果反归一化
阶段1:全局+局部搜索(俯冲捕食)
1.搜索步长系数PK(随迭代衰减,平衡全局/局部搜索)
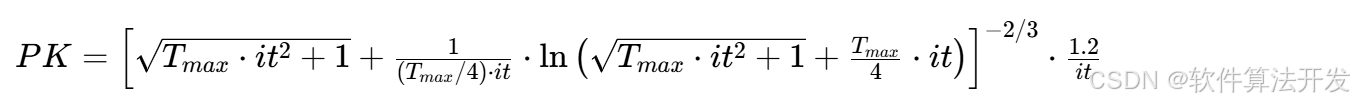
其中it为当前迭代次数,PK随it增大而递减(前期大步全局探索,后期小步局部细化)。
2.个体适应度比例Pei(区分优劣解)
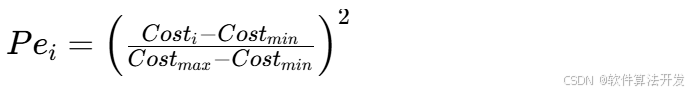
其中Costi为第i个个体的适应度(LSTM预测误差), Costmin/Costmax为当前种群的最小/最大误差。Pei越大,说明个体越差,越倾向全局搜索;反之越倾向局部搜索。
3.位置更新公式

4.边界约束

阶段2:弱解替换(群体协作)
1.替换概率Pt
![]()
Pt随迭代次数动态变化,控制弱解替换的概率。
2.弱解替换公式
若rand<Pt
将种群按适应度升序排序,删除最后Ne个最差解; 围绕全局最优解生成新解,公式为:
Xnew=X best+rand(1,D)⋅rand(LB,UB)
将新解加入种群,保持种群规模为N 。
3.适应度函数
优化目标是最小化LSTM测试集预测误差,核心公式为:

5.完整程序
VVV
关注后手机上输入程序码:129



















 154
154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











