



导读
想象一下,让一个移动双臂机器人去做家务:擦平底锅、叠餐盘、拿杯子、清理桌面。这些任务看似简单,却要机器人同时控制底座、两只手臂、相机,每一步都要又稳又准。问题在于——要让它学会这些技能,通常需要海量的人类遥操作示范,既费时又费力。
而李飞飞团队的新作 MoMaGen 给出了一条新路:
只需一条人类示范,它就能在仿真中“举一反三”,自动生成上千条可执行、多样化、带视觉约束的机器人操作演示。更关键的是——这些虚拟演示并非“空想”,而是经过物理与可视性约束的严格筛选,能真正转化为可部署的行动数据,让机器人从“看懂”走向“能做”。

▲图1|MoMaGen数据生成展示:通过一条人类的操作采集,即可生成多条可供训练的高质量仿真数据,动作丝滑,视角稳定,能够合理的规划并执行任务

以往的机器人模仿学习主要靠人类操作采集数据——特别是移动双臂任务,人要同时操作底座、两条机械臂和视觉相机,即使是专家,也常常手忙脚乱。研究者于是换了个思路:既然人工演示太贵,为什么不让算法来“生成”呢?MoMaGen 的关键洞察在于:
把数据生成看作一个带约束的优化问题。
它定义了两类约束——
● 硬约束(Hard Constraints):必须满足,如机械臂可达、任务成功、物体始终在视野中;
● 软约束(Soft Constraints):尽量优化,如导航时保持目标可见、操作后自动收臂。
在此框架下,系统会自动为每个子任务采样机器人底座和相机姿态,通过运动规划与逆运动学(IK)生成新的演示轨迹。哪怕只从一条人类演示出发,MoMaGen 也能扩展出成百上千条“合理且多样”的数据,为模仿学习提供丰富的训练样本。

▲图2|MoMaGen 的核心思想是:只用一条人类演示,就能生成成百上千条新的机器人示范。上方左图展示了原始的人工遥操作——机器人用海绵清洗平底锅;右图则是系统自动生成的多种场景:锅的位置被随机打乱,还加入了障碍物与干扰物。下方展示了 MoMaGen 生成的多种底座位置和双臂轨迹,说明算法不仅能重现人类动作,还能在复杂环境中“自由发挥”

统一的约束优化框架:让“数据生成”变成可推理的问题
MoMaGen 的核心在于把“从示范生成新数据”重新定义为一个带硬约束与软约束的优化问题。
硬约束保证生成的演示可真正执行(如任务成功、机械臂可达、避免碰撞、操作时物体始终在视野中);软约束则引导生成过程更自然高效(如导航时尽量保持目标可见、操作后自动收臂以便下一步移动)。这种数学化的统一表达不仅让 MoMaGen 能复现已有方法(如 MimicGen、SkillMimicGen),还为今后的自动化演示生成提供了可扩展的基础框架。
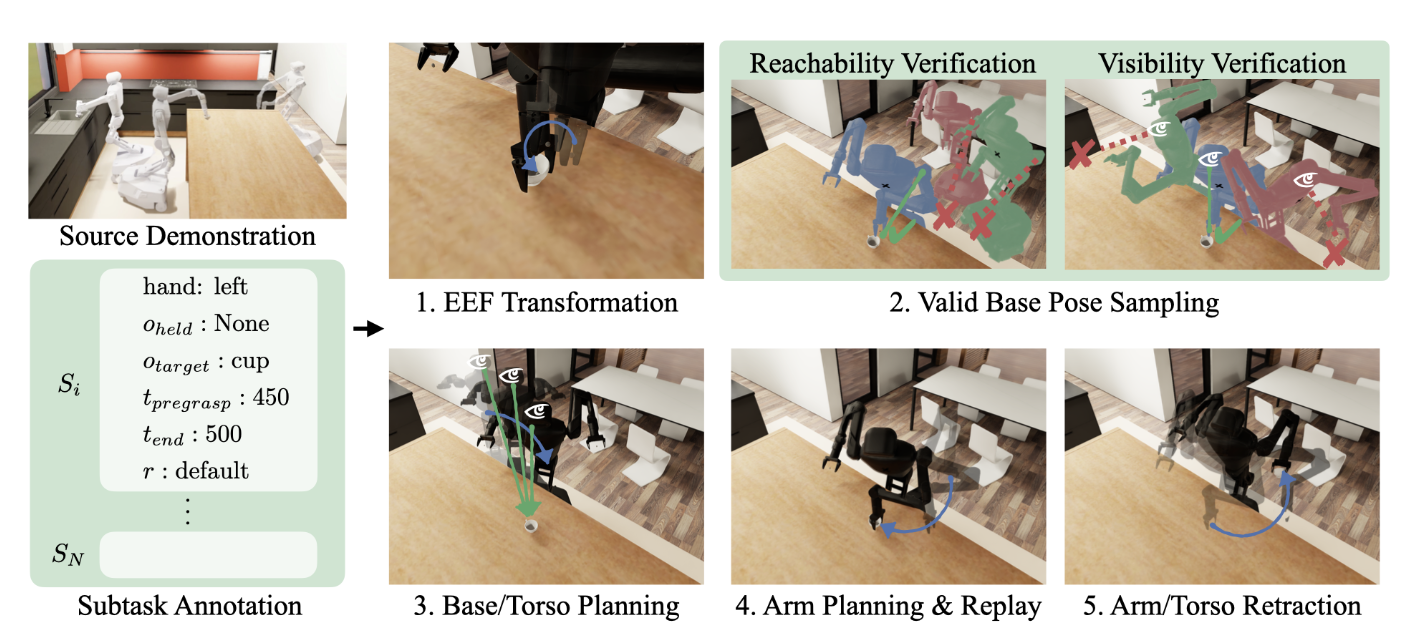
▲图3|MoMaGen 从一条示范出发,为每个子任务随机生成新的场景与物体位置。系统会自动采样机器人底座与相机姿态,确保既能够到目标,又能“看得到目标”。找到合适位置后,机器人先规划移动路径,再执行手臂动作完成操作,最后自动收臂回到安全姿态,实现了完整的“看—动—收”循环
引入“可见性约束”的双层机制:保证机器人始终“看得见目标”
在移动双臂任务中,机器人相机的视角会不断变化,导致目标物体容易“走出画面”。MoMaGen 首次将“可见性”纳入优化约束体系,提出了硬可见性约束(操作阶段目标必须保持在视野内)与软可见性约束(导航阶段相机倾向于对准目标)。实验表明,这一机制显著提升了生成数据的图像一致性与可学习性:在多任务对比中,MoMaGen 的任务相关物体可见率超过 75%,是基线方法的两倍,为视觉模仿策略的稳定学习提供了关键数据保障。
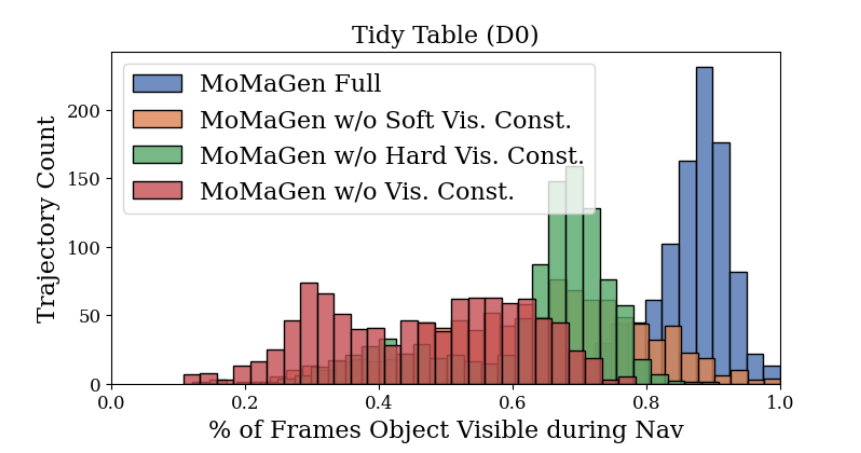
▲图4|MoMaGen 从一条示范出发,为每个子任务随机生成新的场景与物体位置。系统会自动采样机器人底座与相机姿态,确保既能够到目标,又能“看得到目标”。找到合适位置后,机器人先规划移动路径,再执行手臂动作完成操作,最后自动收臂回到安全姿态,实现了完整的“看—动—收”循环
基于约束采样的高质量生成机制:一条示范生成上千条可执行演示
与以往依赖随机扰动或单臂规划的生成方法不同,MoMaGen 在生成过程中同时优化底座、相机和双臂的运动,并通过逆运动学与运动规划确保每个动作都满足物理与几何约束。在具体实现上,算法会从原始演示中提取任务阶段(如抓取、移动、清洁等),对每一阶段进行场景随机化与约束采样,逐步生成多样而合理的全身动作。结果是:MoMaGen 能从仅一条人类示范中生成成百上千条可执行、可感知、可学习的演示数据,并在四个家务级任务上显著提升 imitation policy 的性能与多样性。

团队在四个家庭级任务中测试了 MoMaGen:
● Pick Cup(拿杯子)
● Tidy Table(清理桌面)
● Clean Frying Pan(擦平底锅)
● Put Dishes Away(收拾餐盘)
结果令人惊喜:
● 在数据生成阶段,MoMaGen 的成功率最高、数据最丰富、可见性最强。
● 在训练阶段,使用 MoMaGen 生成数据的 WB-VIMA 与 π₀ 模型表现均优于其他生成方法。
● 当模型迁移到真实机器人,仅用 40 条真实示范微调,就能完成实际抓取任务。
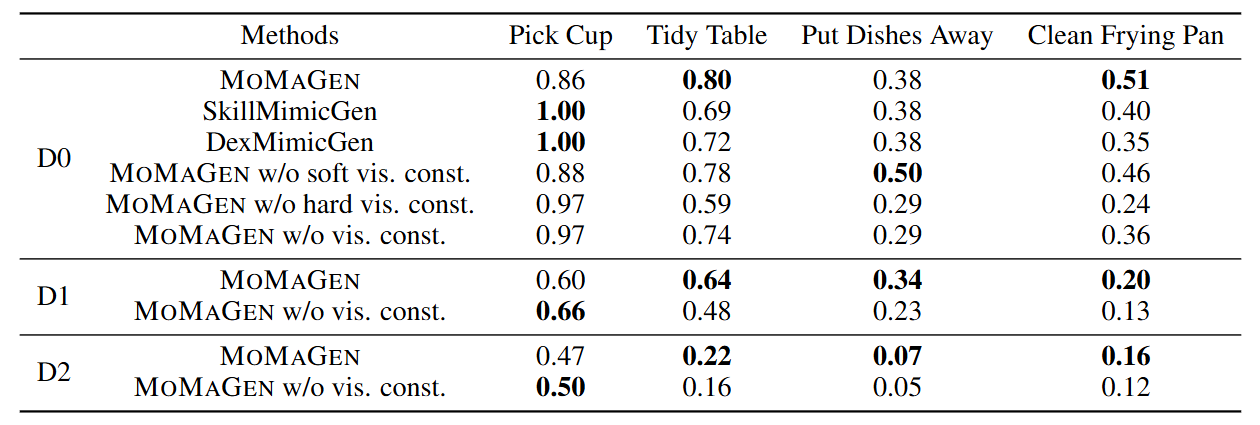
▲图5|数据生成成功率对比:在简单任务如“拿杯子”中,所有方法的成功率都较高;但在复杂任务如“清理平底锅”或“收拾餐具”中,MoMaGen 的优势明显。特别是加入硬可见性约束后,机器人能自动调整躯干姿态,使后续操作更稳定。而传统基线在高随机化条件下几乎无法生成可用演示,成功率为零
📊 实验显示:
基于 MoMaGen 数据训练的 π₀ 模型在现实任务中成功率达 60%,而没有预训练的模型几乎“寸步难行”。这意味着——高质量仿真数据,的确能让机器人少走弯路。
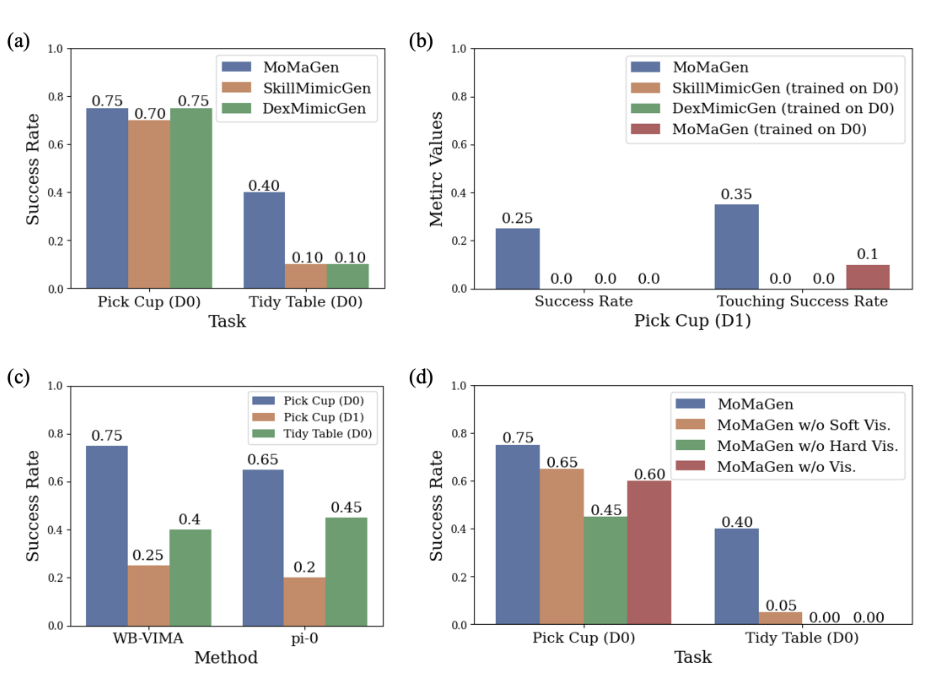
▲图6|MoMaGen 数据让模仿学习更聪明:这一组实验对比了不同数据生成方法在模仿学习中的效果。无论是自训练的 WB-VIMA,还是经过微调的 π₀ 模型,使用 MoMaGen 数据训练的策略都显著优于其他方法。右侧消融实验进一步证明:若去掉可见性约束,模型性能明显下降,说明**“看得见目标”对于智能决策至关重要

MoMaGen 的意义,远不止是生成数据。它更像是一种“数据行为建模”的思维方式:不再仅靠采样或扰动,而是通过“约束推理”去合成真实、可执行的机器人行为。在具身智能的大背景下,这类方法让机器人在仿真中获得“物理常识”与“视觉意识”,能学会在环境中举一反三、在限制中自我优化。当未来的机器人能用这样的机制不断生成、验证、改进自己的经验,或许我们离“自我成长的智能体”又近了一步。

















 293
293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









