



导读
在生成式 AI 的世界里,扩散模型几乎成了“图像质量保证书”。但一个看似简单的问题一直被忽略:
扩散模型真的在“去噪”吗?
如果让人来想象,去噪应该是:给我一张被污染的图,我把干净图像还给你。
但如今几乎所有扩散模型都不是这样工作的——它们训练网络去预测噪声、或者预测混合噪声的量。
听起来更像是在“学习噪声”,而不是“学习图像”。而MIT的何凯明团队在这篇论文中提出了一个非常强烈的观点:
去噪模型应该回归本质,让网络直接预测干净图片本身,而不是高维噪声。
他们把这种思想推到极致,提出了一套几乎“原教旨主义”的做法:
● 不用 latent 空间、不用 tokenizer、不用任何预训练、不用额外 loss
● 只用 Transformer 直接在原始像素 patch 上做扩散
他们把这套模型戏称为 JiT:Just image Transformers。而令人意外的是,这种“回到基础”的方式,在高维像素空间里反而表现得更强、更稳、更简单。
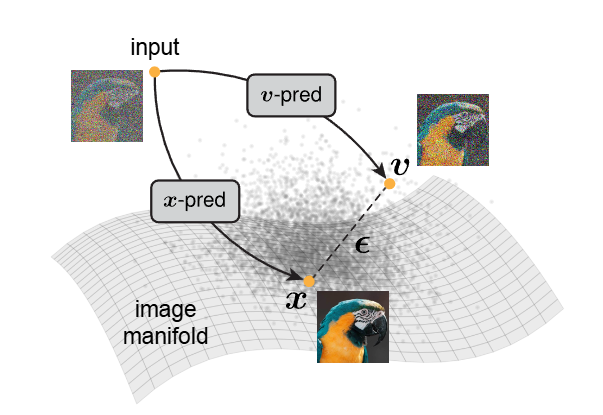
图1|这张图演示了图像生成的核心思想:自然图像通常位于一个低维流形上,而噪声或混合噪声(如图中所示的噪声项与“图像减噪声量”)则散落在高维空间。也正因为干净图像在低维结构中,而噪声是彻底的高维乱流,让模型去预测图像本身和去预测噪声,本质上是两类完全不同的任务
论文出处:arXiv
论文标题:Back to Basics: Let Denoising Generative Models Denoise
论文作者:Tianhong Li, Kaiming He
原文链接:https://arxiv.org/pdf/2511.13720

作者强调一个机器学习领域的经典假设:
自然图像位于一个低维的 manifold 上,几何结构连贯、有规律。但噪声呢?
噪声天生是全维度、无结构、乱飘的。预测噪声,本质上就是在高维空间里硬挤大量信息进网络。
所以当模型 patch 尺寸越大、维度越高时,预测噪声这件事迅速变得“不可做”。
论文给了一个非常直观的例子:
他们把二维数据随机投影到 512 维,让一个小 MLP 按三种方式训练:预测 x、预测 ϵ、预测 v,结果:
只有 x-prediction 能正常收敛,预测噪声的模型全线崩溃
换句话说:
网络容量有限时,预测噪声 = 做不出来
预测干净图 = 轻松搞定
基于这个启发,作者提出了极简框架:
整个模型就是一个 Vision Transformer,输入是像素 patch,输出也是像素 patch,不加花哨结构、不引入额外技巧。

真正“去噪”的扩散目标
核心思想:让网络预测干净数据,而不是噪声或混合噪声。
作者通过数学推导展示:三种预测方式在理论上可以互相转换,但网络直接输出 x 会让任务变得更简单。
在高维场景中尤其关键,比如 3072 维 patch(32×32×3):
只有 x-pred 不会崩溃。
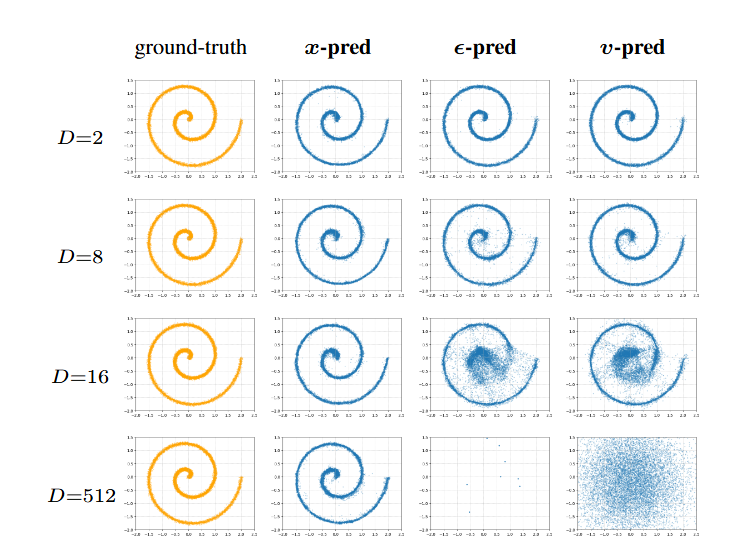
图2|这是一个二维数据被随机投影到高维空间的实验。作者在投影后的高维空间里训练了一个小型生成网络,并比较三种预测方式的表现。随着维度不断升高,只有“预测干净图像”的方式还能维持正常结果,而预测噪声或混合噪声的模型都会迅速崩溃
不用 latent、不用小 patch,也能做高分辨率扩散
传统 ViT 做扩散时需要各种“小 patch + 大模型”组合来避免维度爆炸。
但作者发现:
即便 patch 高达 3072 维,只要做 x-prediction 就能稳定训练。
更夸张的是:
他们甚至训练了 patch=64(也就是 12288 维 token)的模型,依然保持良好效果。
这意味着:
扩散 + Transformer 完全可以摆脱 latent space,自洽地在像素空间工作。
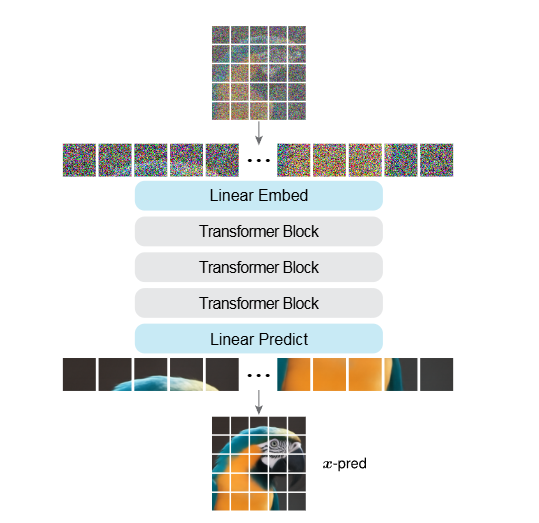
图3|JiT 的结构示意图。它本质上就是一个直接处理像素 patch 的 ViT,不依赖额外模块,模型的输出也是同样大小的像素 patch,用来做干净图像的预测
越“瘦”的模型,效果有时越好
在下图中,作者测试了一个非常反直觉的设计:
把 patch embedding 做成 bottleneck(比如把 768 维压到 128、64、32)
结果:没有任何灾难性退化,反而在某些范围(32~512)显著提升 FID,最小甚至只用 16 维 bottleneck 也没崩溃。
这与 manifold 假设完全一致:
干净图像本身是低维的,把 embedding 压缩后更贴近其几何结构,反而 “更好学”。
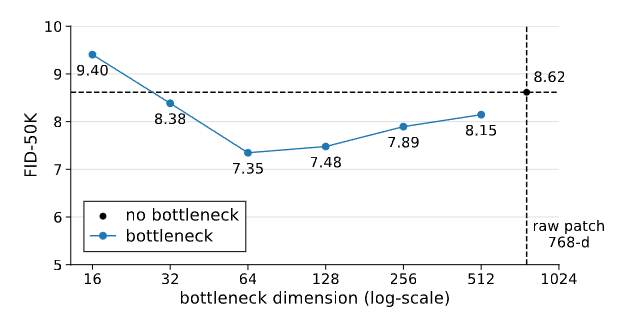
图4|即便把原始 patch(768 维)压缩到很小的维度,例如 32 维甚至 16 维,模型依然能稳定生成图像,而且往往效果更好。这说明图像本身的关键信息是低维的,合适的瓶颈反而能帮助模型更好地学习

在实验部分,作者将 JiT 这套“极简扩散 Transformer”在 ImageNet 的多个分辨率上全面检验。最令人惊讶的是,在完全不用 tokenizer、不做预训练、不引入额外损失的前提下,它依然能取得相当亮眼的表现。
以 256×256 分辨率为例,随着模型规模从 Base 到 Large、再到更大的 H 和 G,FID 指标不断下降:JiT-L/16 已能达到 2.36,而 H 与 G 级模型更是进入 1.x 区间,其中 JiT-G/16 达到 1.82,与当前依赖复杂 latent 空间或自监督特征的大型扩散模型处在同一水平。

图5|实验比较了不同规模模型在 256×256 与 512×512 上的可扩展性。由于序列长度固定,两种分辨率的计算量基本相同。随着模型规模扩大,512 分辨率的 FID 甚至能优于 256 分辨率,显示出 JiT 在高维像素空间的稳定性
当分辨率提升到 512×512,JiT 同样保持稳定。作者将 patch 尺寸同步扩大为 32×32,使序列长度仍旧维持在 16×16,不随分辨率攀升而变重。结果显示,H/32 模型达到 1.94 的 FID,而 G/32 模型更是达到 1.78,证明在超高维 patch(3072 维)下,x-prediction 仍能保证良好的可训练性。

图6|作者在 ImageNet 1024×1024 的高分辨率上评估了 JiT-B/64 模型。由于序列长度与低分辨率一致(仍是 16×16 patch),计算量几乎不随分辨率增加而上升,模型在千级分辨率下也能保持稳定表现
在更高分辨率的 ImageNet 1024×1024 上,JiT-B/64 同样能给出可用的结果(FID 4.82),并且计算成本几乎与 256 或 512 分辨率时无异,原因就在于序列长度恒定。这种“分辨率增长但计算不变”的性质,使得 JiT 特别适合原生像素空间的高分辨率生成任务。

这篇论文提出了一个颠覆直觉但又极其朴素的观点:
扩散模型应该预测干净图像,而不是噪声。
在高维像素空间里,这个选择会决定模型是“正常工作”,还是“彻底崩溃”。
JiT 框架展示了一种完全自洽、无需预训练、无需复杂结构的路径,让 Transformer 在原生像素空间也能高效扩散。对于具身智能、科学计算等需要处理原始高维数据的领域,这种“去掉中间件”的方式尤其重要:
不用 latent、不用 tokenizer 的扩散 + Transformer,有可能成为更通用的生成基础方式。

















 1430
1430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









