



作者 | 深蓝学院 来源 | 深蓝AI
点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文
导读
斯坦福大学HAI研究院(Stanford Institute for Human-Centered AI, HAI)由李飞飞教授领衔,是全球人工智能基础研究与社会治理的重要引领力量。
李飞飞现任斯坦福大学首位红杉讲席教授,美国国家工程院、国家医学院及艺术与科学院三院院士,长期专注于计算机视觉、机器学习、认知神经科学与环境智能系统等方向。她创建的 ImageNet 数据集及相关研究奠定了深度学习在视觉理解领域的核心基础,并推动了“数据驱动 + 认知启发”的研究范式在全球范围的普及。
在研究思路上,李飞飞团队始终强调“从算法到系统”的全链路创新,致力于通过多模态融合、可解释学习与跨域感知,实现面向真实世界的智能体建模。近年来,团队的工作从视觉表征学习延伸至多模态生成、具身智能与社会责任计算等方向,形成了跨越感知、建模、推理与决策的系统性研究框架。
2025 年,团队在多个核心领域取得了代表性成果:在生成建模方面,探索了从二维视觉到三维世界重建的高效迁移机制,提出更具泛化性与可扩展性的生成式表示学习框架;在具身智能方向,融合可供性学习、动作约束与策略蒸馏,实现了跨场景、多任务的操作泛化;在语义推理与人机理解领域,强化了模型在长时序与动态环境中的推理一致性与视觉语言对齐能力;同时,团队也在人工智能治理与社会责任方面持续发声,推动前沿 AI 的政策评估与安全框架建设。
整体而言,李飞飞团队 2025 年的研究展示了人工智能从“感知世界”到“理解并重建世界”的跃迁,体现出以人为本、可解释、可扩展的智能体系构想,为下一阶段通用人工智能的发展奠定了重要基础。
接下来,小编为大家带来李飞飞团队 2025 年的研究成果大盘点!
值得说明的是,李飞飞教授近年来合作研究广泛,涵盖计算机视觉、具身智能、生成建模与 AI 治理等多个方向。本文所盘点的内容,仅聚焦于由李飞飞教授本人担任大通讯作者(corresponding author)的核心论文,代表其团队在 2025 年度的主要研究脉络与前沿突破。部分工作仍处于审稿或预印本阶段,因此暂未标注最终发表会议与期刊。
参考:
https://scholar.google.cz/citations?hl=zh-CN&user=rDfyQnIAAAAJ&view_op=list_works&sortby=pubdate
MOMAGEN: Generating Demonstrations under Soft and Hard Constraints for Multi-Step Bimanual Mobile Manipulation
地址:https://arxiv.org/pdf/2510.18316
主要内容:
这项研究针对多步双臂移动操作任务中演示数据难以高效采集的问题,提出了一种自动化演示生成框架 MOMAGEN。该方法将数据生成过程形式化为一个具备硬约束与软约束的优化问题:硬约束用于确保可达性(如机械臂能够实际完成操作),软约束则用于平衡可见性与导航过程中的相机视角。与以往仅能在固定场景生成静态数据的自动化扩展方法不同,MOMAGEN 能够在动态、复杂的移动操作场景下生成多样化、高质量的数据集。实验结果显示,该框架在四类双臂移动操作任务中显著提升了数据多样性与模仿学习策略的泛化能力,并可通过少量真实数据(约 40 条演示)完成快速微调与真实部署,为大规模机器人演示数据生成提供了统一而可扩展的解决方案。

图1|MOMAGEN 的核心思路演示:系统仅依赖一条人工采集的示范,即可通过“约束优化”生成大规模、多样化的机器人演示数据。上方展示了原始的人类清洗平底锅示例(左)及经过随机物体姿态与干扰物扰动后的多场景扩展(右);下方展示了不同的机器人底盘位置与双臂运动轨迹。可以看到,MOMAGEN 能在复杂、变化的场景中自主生成符合任务约束的多样化操作示范
Spatial Mental Modeling from Limited Views [ICCV]
地址:https://arxiv.org/pdf/2506.21458
主要内容:
该研究探讨了视觉语言模型(VLM)能否像人类一样,从有限视角中构建对完整场景的空间心智模型。作者提出了新的评测基准 MINDCUBE,包含 3,268 张图像与 21,154 个问题,用于测试模型在空间布局、视角转换与动态推理(如“假设性移动”)等方面的能力。实验表明,现有主流 VLM 在该任务上几乎呈随机表现,难以形成稳健的空间表征。为此,研究者设计了三种增强策略:中间视角补全、语言链式推理与认知地图生成,并提出联合训练的 “map-then-reason” 框架,使模型先生成认知地图,再在其基础上进行推理。该方法将准确率从 37.8% 提升至 60.8%,进一步结合强化学习后达到 70.7%。研究揭示了构建并利用内在空间结构表示的重要性,为具备类人空间想象能力的通用视觉语言模型提供了新方向。
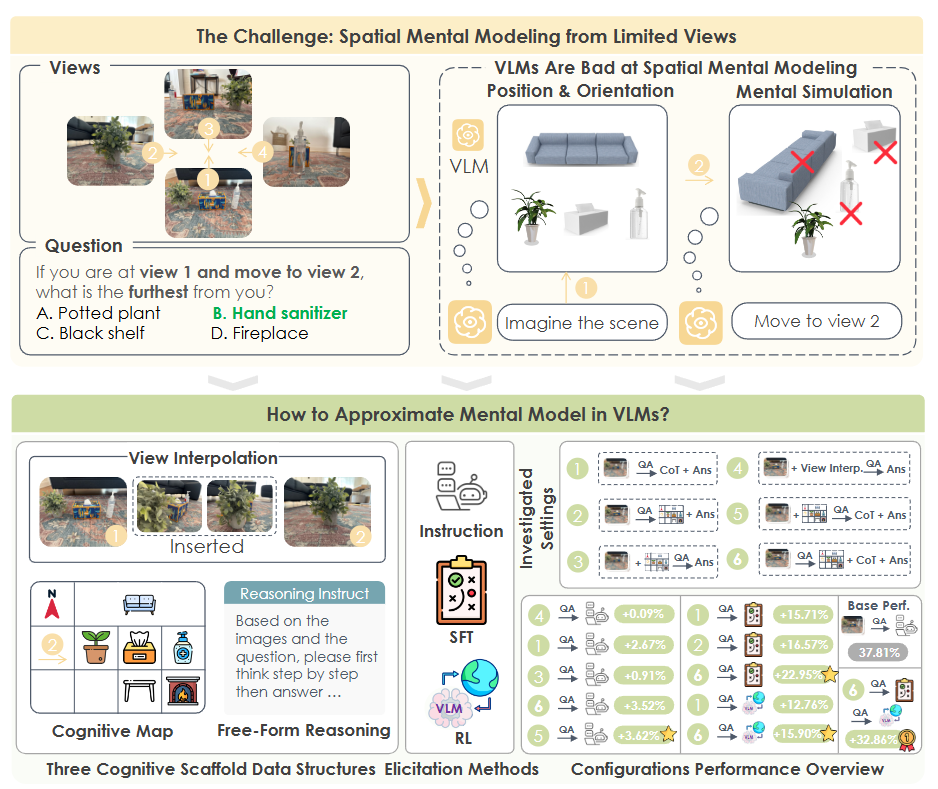
图2|上:现有视觉语言模型(VLM)在 MINDCUBE 基准上难以维持连贯的空间心智模型,面对遮挡与视角变化时表现近乎随机。下:研究者探索了帮助模型“想象空间”的两类策略——外部策略(扩展视角数量、引入认知地图)与内部策略(微调模型、激活内在地图生成)。结果显示,“生成认知地图再进行推理”的联合框架效果最佳,准确率提升达 +32.9%,显著增强了模型对不可见空间的理解与想象能力
UAD: Unsupervised Affordance Distillation for Generalization in Robotic Manipulation [CoRL]
地址:https://arxiv.org/pdf/2506.09284
主要内容:
该研究提出 UAD(Unsupervised Affordance Distillation) 框架,用于在无人工标注的情况下,从大规模视觉与视觉语言模型中提取并蒸馏可供性知识,以提升机器人在开放环境下的操作泛化能力。传统方法通常依赖人工标注或预定义任务,而 UAD 通过结合大模型的视觉理解与语言指令解析能力,自动生成包含 <指令, 可供性> 的配对数据。研究者在此基础上训练了轻量级的任务条件解码器,可直接预测细粒度可供性分布,并支持开放世界场景与多样化任务指令的泛化。实验显示,利用 UAD 提供的可供性作为状态输入,模仿学习策略仅需少量演示(约10条)即可泛化至未见的物体实例、类别与任务变体。该工作为零标注可供性学习与开放任务机器人操控提供了新的技术路径。

图3|UAD 框架示意:系统从大型预训练模型中自动提取可供性标注,并将其蒸馏至任务条件可供性模型中。该模型能够在开放世界场景下、面对开放式自然语言指令时,预测细粒度的物体可供性区域,从而为下游策略学习提供具备多样化泛化能力的高层语义输入
Exploring Diffusion Transformer Designs via Grafting
地址:https://arxiv.org/pdf/2506.05340
主要内容:
该研究提出一种名为 Grafting 的新方法,用于在不重新预训练的情况下探索扩散 Transformer(Diffusion Transformer, DiT)的结构设计。研究者受到“在现有代码基础上构建新软件”的启发,尝试直接在已预训练模型上进行结构 graft(嫁接),从而在极低计算成本下实现新架构的快速原型化与性能评估。具体而言,论文系统分析了激活分布与注意力局部性特征,并在 DiT-XL/2 框架上测试了多种混合结构设计,包括用门控卷积、局部注意力、线性注意力替换传统 softmax 模块,以及改进 MLP 扩展比例和卷积变体。实验表明,多种 graft 设计在仅使用 2% 预训练计算量的条件下即可达到接近原模型的生成质量(FID≈2.4),并在文本生成图像任务上实现 1.43× 的推理加速。该工作展示了利用预训练模型进行结构级重组的可行性,为高效探索扩散模型架构提供了一种通用范式。

图4|Grafting 方法概览:该研究提出在无需重新预训练的前提下,通过直接修改已训练扩散 Transformer 的计算图,实现新架构的快速“嫁接”与验证。(a,b) 展示了通过 grafting 编辑预训练模型以探索新结构设计的思路;(c,d) 展示了基于混合架构生成的类别条件图像与高分辨率文本生成样例(2048×2048);(e) 展示了模型深度从 28 层缩减至 14 层后的效果对比。研究核心在于探讨如何在有限计算预算下安全地替换算子(如将多头注意力或 MLP 模块替换为卷积单元),并控制累积误差,从而以最小代价高效探索扩散模型的结构潜力
NeuHMR: Neural Rendering-Guided Human Motion Reconstruction [3DV]
地址:https://openreview.net/pdf?id=yiQHBPK6Ba
主要内容:
该研究提出 NeuHMR 框架,一种基于神经渲染的三维人体运动重建方法,旨在提升现有 HMR(Human Mesh Recovery)模型在自然场景视频中的泛化与精度表现。传统人体网格重建方法通常依赖二维关键点检测进行优化,但此类检测在复杂姿态或遮挡情况下易产生误差。NeuHMR 则重新思考这种依赖关系,引入 Human Neural Radiance Fields(HuNeRF),通过可动画化的神经渲染图像实现对三维人体网格的连续优化与细节恢复。该方法在不依赖伪标注关键点的条件下,直接利用可渲染的视觉反馈修正姿态与形状估计。实验结果表明,NeuHMR 在多项标准基准上均取得显著提升,验证了神经渲染在提升人体运动重建鲁棒性与泛化能力方面的潜力。
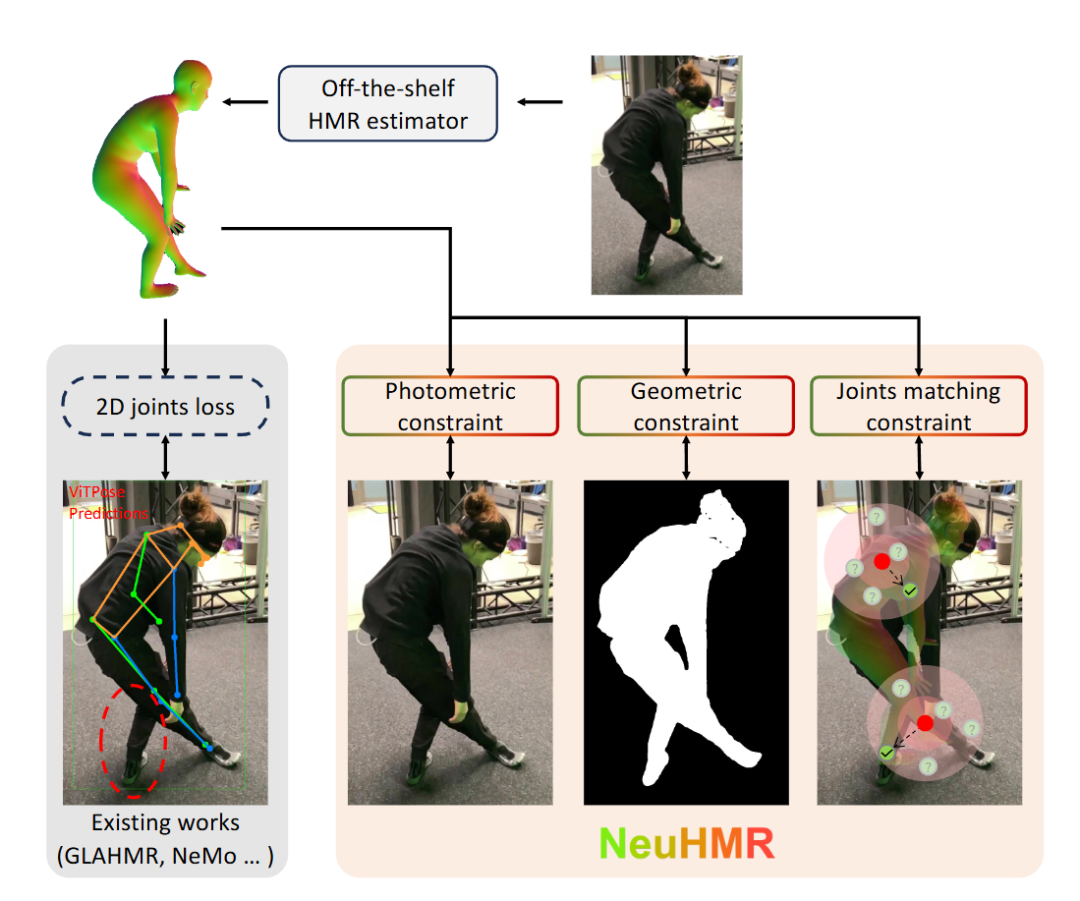
图5|以往的人体网格重建方法通常依赖外部关键点检测器提供的二维伪标注进行优化,但这些检测在复杂姿态下容易出错(如图左)。NeuHMR 摒弃了这种依赖,转而利用基于神经渲染的低层视觉约束来直接优化人体姿态与网格形状,实现了更精细、更稳定的姿态重建效果
BEHAVIOR ROBOT SUITE:Streamlining Real-World Whole-Body Manipulation for Everyday Household Activities [RSS]
地址:https://arxiv.org/pdf/2503.05652?
主要内容:
该研究提出 BEHAVIOR ROBOT SUITE(BRS),一个面向现实家庭环境的全身操控研究框架,旨在推动移动操作机器人在日常任务中的可行性与通用性。研究指出,成功完成复杂家庭任务的关键在于三种能力:双臂协同、稳定精确的移动导航、以及广泛的末端执行器可达性。BRS 基于具备双臂与四自由度躯干的轮式移动平台设计,集成了低成本的全身远程操作接口用于数据采集,并提出了新型的全身视觉运动策略学习算法。系统在五项典型家务任务上进行了验证,涵盖长距离导航、与可变形或铰接物体交互、狭小空间操控等挑战。结果表明,BRS 能有效简化从数据采集到策略学习的全过程,为具身机器人实现真实世界的全身操作提供了统一平台与研究基准。

图6|BEHAVIOR ROBOT SUITE(BRS)在多种日常家庭任务中的应用示例。系统展现出三项核心能力:双臂协同(B) 实现复杂物体交互,稳定精确的导航(N) 支撑长距离移动与姿态保持,广泛的可达性(R) 使机器人能够在受限空间完成精细操作
Towards Fine-Grained Video Question Answering [CoRR]
地址:https://arxiv.org/pdf/2503.06820
主要内容:
该研究面向视频理解领域的核心问题——视频问答(VideoQA),提出了全新数据集 MOMA-QA 以及对应的视觉语言模型 SGVLM,以突破现有方法在时间与空间粒度上的局限。MOMA-QA 强调时间定位、空间关系推理与多实体交互,提供精确的场景图与时间区间标注,为细粒度视频理解提供系统化基准。SGVLM 模型在此基础上引入场景图预测模块、帧级检索机制与预训练大语言模型,以联合实现时间对齐与关系推理能力。实验结果显示,该方法在 MOMA-QA 及多个公开数据集上均显著优于现有方法,推动视频问答从粗粒度语义理解迈向更高层次的时空推理与多主体认知。

图7|MOMA-QA 数据集示例:展示了三类不同类型的视频问答样例,分别对应空间关系、动作动态与实体识别等细粒度理解任务。所有问题均基于人工标注的时空场景图生成,右侧为对应的场景图结构,其中红色节点表示当前问题关注的目标实体或动作要素。通过这种结构化标注,模型能够在时间与空间维度上进行更精确的语义推理
Repurposing 2D Diffusion Models with Gaussian Atlas for 3D Generation
地址:https://arxiv.org/pdf/2503.15877?
主要内容:
该研究提出 Gaussian Atlas框架,用于将预训练的二维扩散模型高效迁移至三维生成任务。当前 3D 扩散模型发展受限于高质量三维数据稀缺,导致性能远不及 2D 模型。为解决这一问题,作者创新性地引入基于二维稠密网格的三维高斯表示,使 2D 扩散模型能够在“展平”的二维流形上学习并生成三维结构,从而实现跨维度的知识迁移。论文同时构建了 GaussianVerse 数据集,包含 20.5 万个高质量 3D 高斯拟合样本,为训练与评估提供了大规模支持。实验结果表明,该方法能够有效继承文本到图像扩散模型的生成能力,并在 3D 对象生成中取得高保真度与几何一致性,成功搭建起 2D 与 3D 生成建模之间的桥梁。
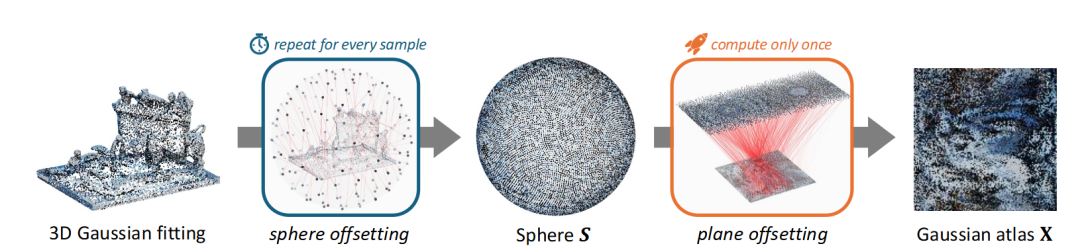
图8|Gaussian Atlas 表示示意:首先将三维高斯分布通过最优传输映射至标准球面上(S),再利用等距投影将球面分布展平至二维平面。最终,研究者将展平后的坐标重新组织为 √N×√N 尺寸的稠密二维方格像素,从而构建出可供扩散模型直接处理的 Gaussian Atlas 表示,使二维模型能够高效学习三维结构特征
总结
2025 年,李飞飞团队的研究体系展现出从视觉理解到具身智能、从模型结构到生成世界的纵深演进。无论是 MOMAGEN 对机器人示范生成机制的重塑,还是 UAD 在无监督可供性蒸馏中的创新,抑或 BEHAVIOR ROBOT SUITE 在真实场景下的全身操控突破,都体现了团队在“从感知到行动”的闭环思维。
与此同时,Spatial Mental Modeling、Fine-Grained VideoQA 与 Gaussian Atlas 等工作,则从认知层面拓展了人工智能的空间建模与多模态生成边界。Grafting 与 NeuHMR 等方法则在模型结构优化与三维重建方向上探索了更高效、更通用的技术路径。整体来看,这些研究形成了一个跨越数据、认知、生成与具身实践的系统化智能图景,既深化了人工智能的理论基础,也推动了其向开放世界与人本导向的真实应用迈进。
2025 年关键词:认知、生成、具身、迁移、可解释
自动驾驶之心
论文辅导来啦

自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 1943
1943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









