 VLA与世界模型融合新突破
VLA与世界模型融合新突破





VLA 与世界模型的再次强绑定
——是突破还是精致的技术缝合?
在机器人操控的技术体系里,VLA 模型和世界模型被视为两大核心支柱,但二者长期处于 “各自为战” 的状态。
VLA 的优势很直接,能精准对接人类语言指令和视觉环境,输出对应的机器人动作。但无法理解动作会给环境带来怎样的变化,也缺乏对物理规律的认知。
世界模型虽能弥补VLA的不足,但是没有直接生成动作的能力。
阿里达摩院团队正是看准了二者的互补性——

最新推出了 RynnVLA-002,在先前成果 WorldVLA 的基础上,进一步将VLA 与世界模型整合到同一框架中。
让 VLA 的动作生成能力为世界模型的环境预测提供依据,同时用世界模型的环境预判来优化 VLA 的动作决策。
一场“优雅的补位”,让两类模型在同一个系统里双向驱动。但优雅的背后,往往藏着更深的博弈——
当两套复杂系统被紧密耦合,它们的局限是否也会被叠加?
当决策依赖于预测,预测的偏差又将如何被放大?
补位之后,是否会有新的“陷阱”显露……
在系统介绍RynnVLA-002之前,先澄清它与此前发布的RynnVLA-001的区别:
RynnVLA-001专注于通过12M自我中心视频的两阶段预训练(视频生成+轨迹感知建模)来改善机器人操作的动作预测;
相关阅读:阿里达摩院用 1200 万第一视角视频打底,新成果 RynnVLA-001 大幅碾压主流模型!
而RynnVLA-002则将VLA模型和世界模型统一在一个框架中,让两者相互促进——世界模型学习环境物理规律来帮助动作生成,VLA模型增强视觉理解来支持图像生成。
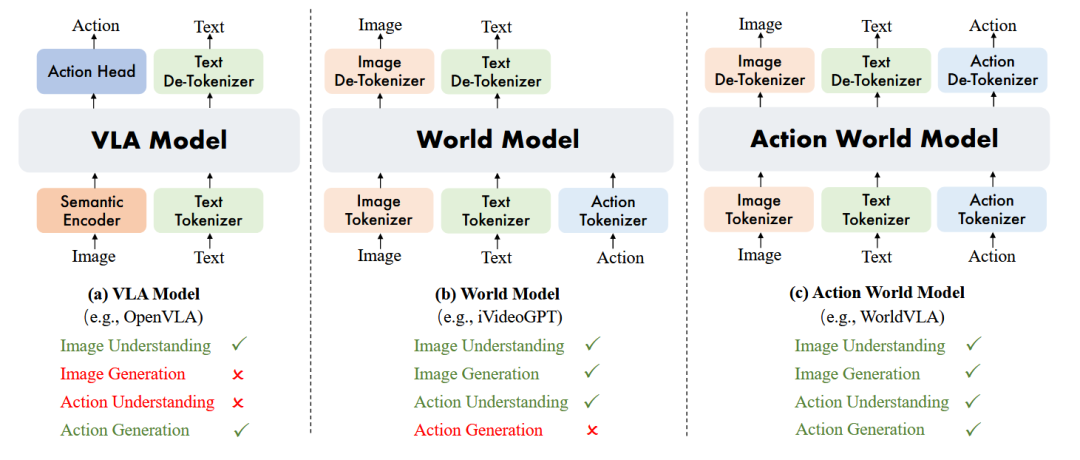
▲图1 | (a) VLA模型基于图像理解生成动作;(b) 世界模型基于图像和动作理解生成图像;(c) 动作世界模型统一了图像和动作的理解与生成。
RynnVLA-002 是基于先前 WorldVLA 进行改进的。
接下来我们看看这一改进的必要性。

长期以来,标准VLA架构存在三个根本性缺陷:
无法充分理解动作:动作仅存在于输出端,模型无法形成对动作动态的显式内部表示。
缺乏想象能力:模型不会预测给定候选动作后世界可能如何演变
没有显式的物理理解:模型难以内化物体交互、接触或稳定性等概念。
世界模型虽然直面这些局限性,但受限于无法直接生成动作输出,在需要显式动作规划的场景中存在功能缺口。

▲VLA模型结果
为此,研究团队先提出了WorldVLA——一个用于统一动作和图像理解与生成的自回归动作世界模型。
验证了VLA模型与世界模型可以相互增强这一核心假设,并提出了动作注意力掩码策略来解决自回归生成中的错误累积问题。
相关阅读:首个!阿里巴巴达摩院:世界模型+动作模型,给机器人装上「预言&执行」双引擎

▲世界模型结果
然而,WorldVLA在真实世界机器人实验中暴露出泛化能力有限、推理速度慢、轨迹不平滑等问题。
在此基础上,研究团队进一步提出了RynnVLA-002,通过引入连续Action Transformer来克服这些局限性。
以下是两者的详细对比:

▲WorldVLA与RynnVLA-002的对比。
因此,RynnVLA-002 在 WorldVLA 的基础上,通过引入连续Action Transformer ,解决了离散模型在真实世界中泛化差、推理慢、轨迹不平滑的问题,同时保留了离散动作建模来加速训练收敛。

如图2所示,RynnVLA-002使用三个独立的分词器分别编码图像、文本和动作。
来自不同模态的token被设置为共享同一词汇表,使得这些模态的理解和生成可以在单一LLM架构内统一。
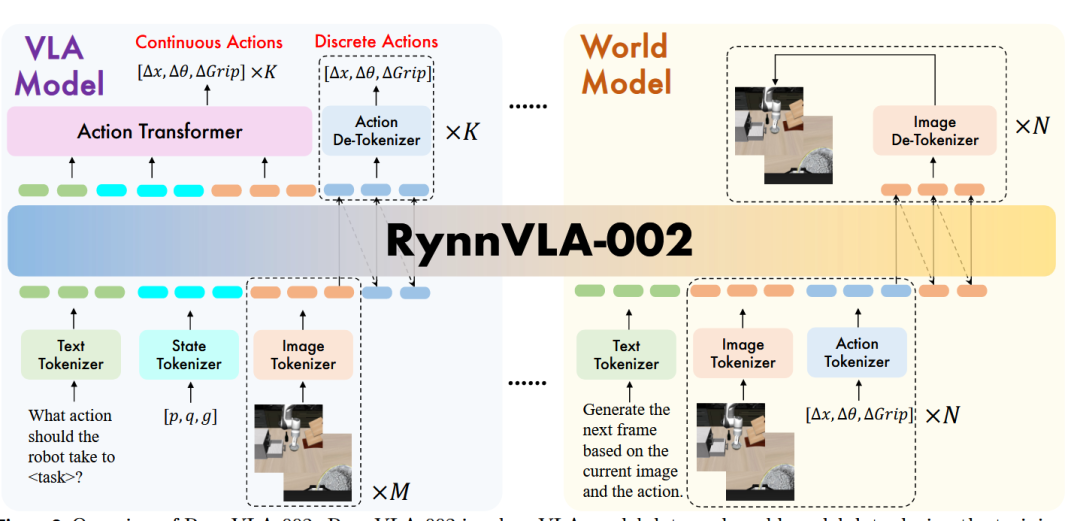
▲图2 | RynnVLA-002概览。RynnVLA-002在训练过程中涉及VLA模型数据和世界模型数据。
-
VLA模型部分的输入token序列结构为:
{text} {state} {image-front-wrist} ×M → {action} ×KVLA模型基于语言指令、本体感受状态和M个历史图像观察生成K个动作。
文本输入为"What action should the robot take to + <task> + ?"。
-
世界模型部分的输入token序列结构为:
{text} {images-front-wrist} {action} → {images-front-wrist}世界模型基于当前图像观察和动作生成下一帧图像。
所有训练实例共享相同的文本前缀"Generate the next frame based on the current image and the action."。
不需要其他任务指令,因为动作本身可以完全决定世界的下一个状态。
离散动作块的注意力掩码策略
研究团队引入了一种针对动作生成的替代注意力掩码,如下图(b)所示。

▲图3 | (a) 默认VLA模型、(b) 本文提出的VLA模型、(c) 世界模型的注意力掩码。
这种修改后的掩码确保当前动作仅依赖于文本和视觉输入,同时禁止访问先前的动作。
这种设计使自回归框架能够独立生成多个动作,减轻了错误累积问题。
连续动作的Action Transformer
虽然离散动作分块模型在仿真中表现良好,但在真实世界机器人实验中却很少成功。这种差异源于真实世界应用需要显著更高的泛化能力来应对光照和物体位置等动态变量——这些因素在仿真中无法完全捕获。
因此,研究团队提出增加一个专用的 Action Transformer 来生成连续动作序列。
该模块处理完整上下文(包括语言、图像和状态token),并利用可学习的动作查询并行输出整个动作块。
整体损失函数变为:

仿真基准测试
实验在LIBERO基准上进行评估,该基准包含四个不同的测试套件:
-
LIBERO-Spatial关注空间关系;
-
LIBERO-Object强调物体识别和操作;
-
LIBERO-Goal测试程序学习;
-
LIBERO-Long包含10个复杂的长时域操作任务。
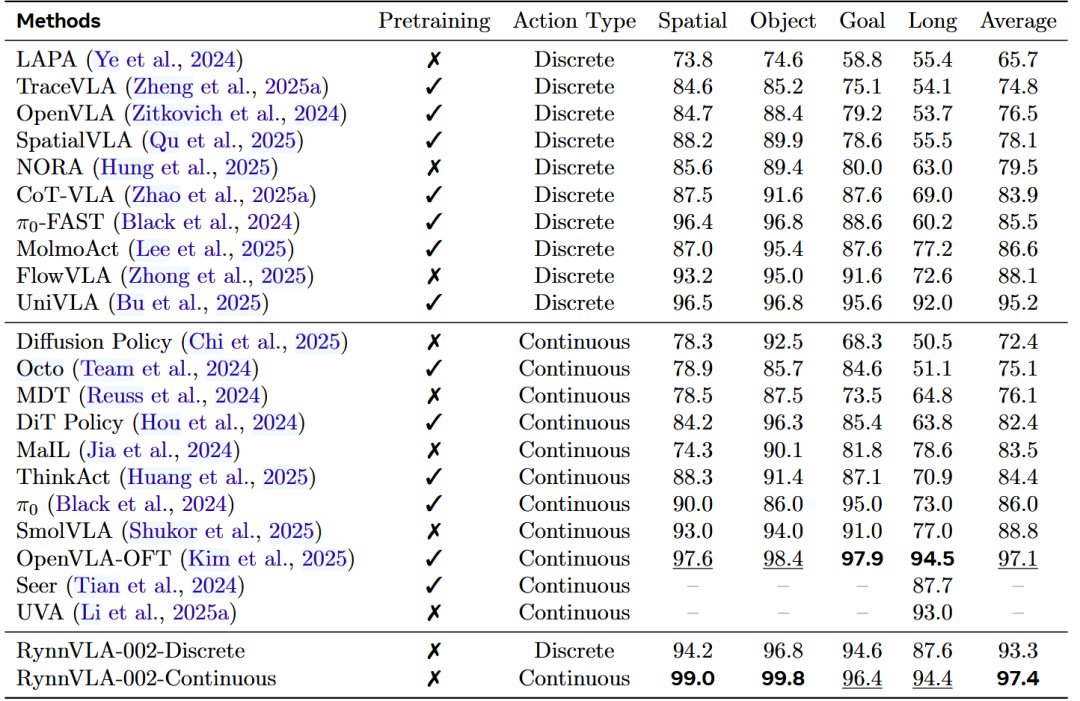
▲表1 | LIBERO基准上的评估结果。预训练指模型在大规模机器人操作数据上进行了预训练。
如上表所示,RynnVLA-002使用离散动作达到93.3%的成功率,使用连续动作达到97.4%的成功率。
而且,RynnVLA-002在没有任何预训练的情况下,仍与在LIBERO-90或大规模真实机器人数据集上预训练的强基线模型相当。
真实世界机器人实验
研究团队使用LeRobot SO100机械臂收集了一个新的真实世界操作数据集。定义了两个抓取放置任务进行评估:
-
将方块放入圆圈内(248个演示);
-
将草莓放入杯中(249个演示)。

▲图3 | 真实世界机器人设置。左:将方块放入圆圈内。中:将草莓放入杯中。右:带有干扰物的任务。
如下表所示,RynnVLA-002在没有预训练的情况下取得了与GR00T N1.5和π0相当的结果。
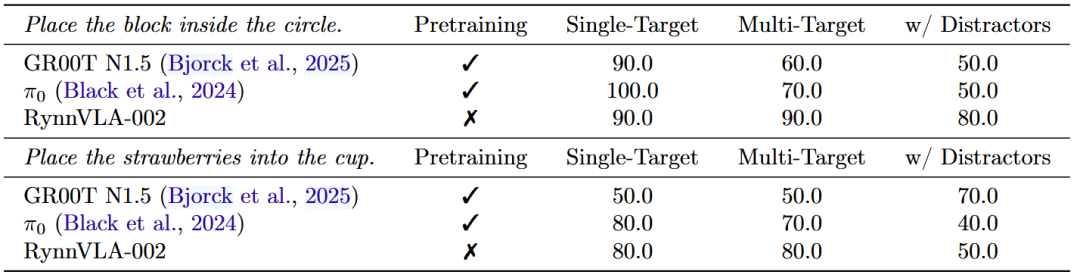
▲表2 | 真实世界SO100机器人上的评估结果。报告了成功率。
而且,RynnVLA-002在杂乱环境中表现更好。
例如,在"放置方块"任务的多目标任务和干扰物场景中,RynnVLA-002的成功率超过80%。

▲与基线的对比实验。
世界模型对VLA模型的增益
-
在LIBERO仿真基准上,训练时加入世界模型数据持续改善性能。
如下表所示,离散动作的成功率从62.8%提升到67.8%,从76.6%提升到78.1%。
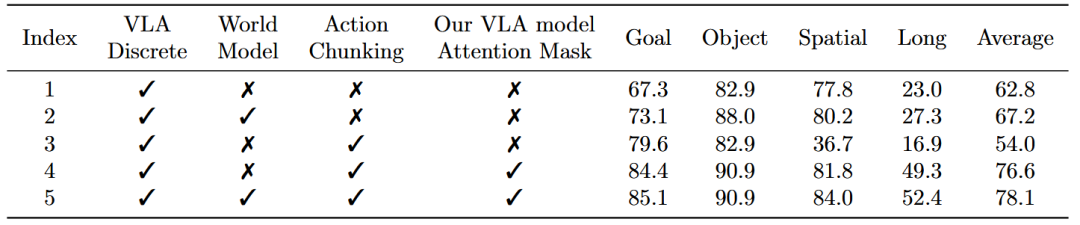
▲表3 | 在LIBERO基准上使用离散动作的VLA模型消融研究。
连续动作也观察到类似趋势,如下表所示,成功率从91.6%提升到94.6%。

▲表4 | 在LIBERO基准上使用连续动作的VLA模型消融研究。
-
在真实世界机器人实验中,世界模型数据的收益更加显著。

▲图4 | LIBERO上的VLA模型可视化。任务:将奶油奶酪放入碗中。上:无世界模型。下:有世界模型。
如图所示:
没有世界模型数据训练的模型直接移向目标位置而没有成功抓取奶酪或瓶子;
而与世界模型联合训练的模型在遇到失败时会不断重试抓取目标物体。
这表明世界模型数据帮助VLA模型更多地关注被操作的物体——
因为世界模型的训练目标需要准确预测物体运动,从而强化了对物体交互动态的注意力。
VLA模型对世界模型的增益
如表6所示,将 VLA 模型与世界模型数据混合训练的 RynnVLA-002,效果能达到、甚至优于纯世界模型。
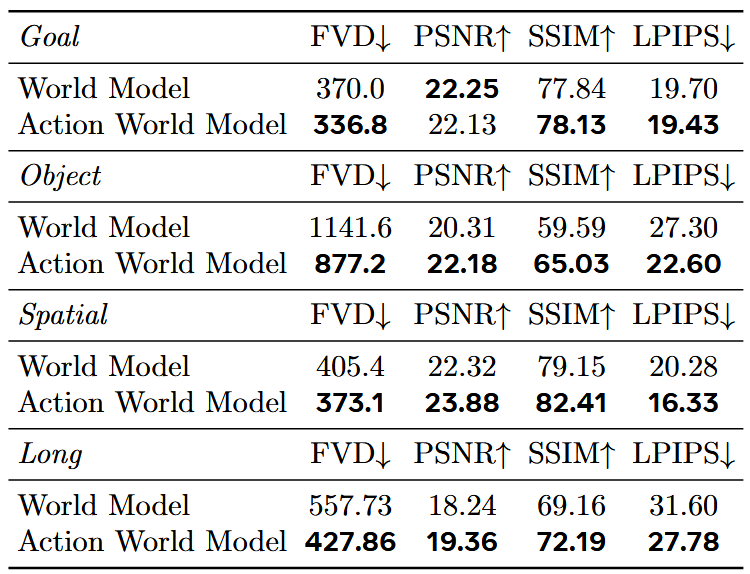
▲表6 | 在LIBERO验证集上的世界模型消融研究。

RynnVLA-002 用统一框架串联 VLA 与世界模型的思路,在此前成果的基础再一次精准 “补位”——
跳出两类模型 “各自为战” 的桎梏,看起来通过双向赋能实现了 1+1>2 的效果。
但,这一范式也直接暴露了当前的根本矛盾:其“思想”的深度与可靠性,依赖于数据、场景与模型三者的协同成熟度。
因此,虽然研究为我们指明了一条可行路径,但攀登的难度丝毫未减:如何突破这些瓶颈,仍是横亘在前方的硬核挑战。
路标已立,前路尚艰……
Ref
论文题目:RynnVLA-002: A Unified Vision-Language-Action and World Model
论文作者:Jun Cen, Siteng Huang, Yuqian Yuan, Kehan Li, Hangjie Yuan, Chaohui Yu, Yuming Jiang, Jiayan Guo, Xin Li, Hao Luo, Fan Wang, Deli Zhao, Hao Chen
论文地址:http://arxiv.org/abs/2511.17502
代码地址:https://github.com/alibaba-damo-academy/RynnVLA-002

















 1383
1383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









