




论文:
https://arxiv.org/html/2401.09670v1
博客:
https://hao-ai-lab.github.io/blogs/distserve/
中文翻译:
Goodput: 满足用户时延要求的request/秒;有可能小于throughtput;
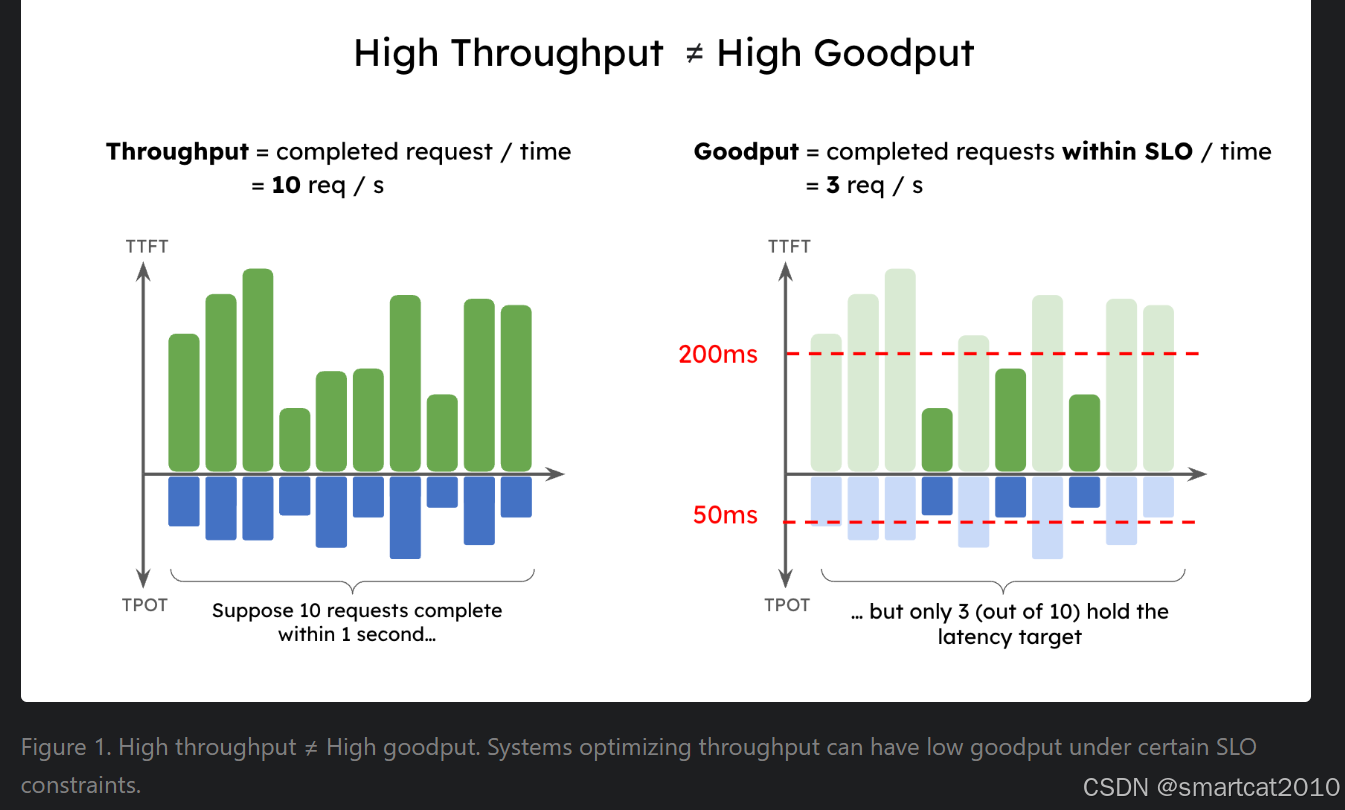
Continue batching, 新的request的prefilling耗时太长,使得同batch的老request延迟明显增大:
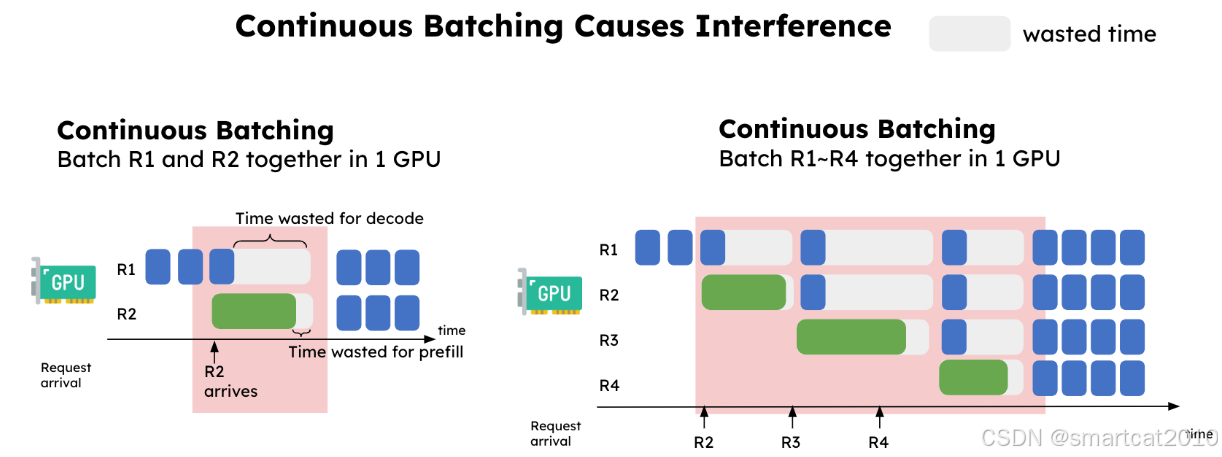
解决方案:
干Prefilling的GPU,和干Decoding的GPU,分开,各
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 574
574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









