



代码:https://github.com/Continual-Intelligence
脚本命令用法:knowledge-incorporation/README.md
生成self-edit数据
脚本:sbatch knowledge-incorporation/scripts/make_squad_data.sh
vllm serve启动Qwen2.5-7B模型的服务。
执行self-edit合成:
--k是指定每篇文章生成多少个self-edit
Squad数据(knowledge-incorporation/data/squad_train.json):
默认用的这个prompt:
(如果用的instruct model,只需要按照该model的标签和role来写即可:)
调用vllm api,生成一批self-edit:
(所有文章数n,每篇生成k个self-edit,一共是n*k个prompt,其中每个文章的k个prompt是相同的)(最后输出到文件)




对self-edit进行SFT, 在QA上评测正确率
sbatch knowledge-incorporation/scripts/TTT_server.sh
启动vllm加载模型:
启动ZMQ服务,
该ZMQ服务接受一组参数:
用train_sequences对model进行lora SFT训练,用训练前和训练后的模型分别评测eval_questions,得到2组正确率指标;
用peft.get_peft_model从base model拿到lora model:
使用transformers.Trainer,trainer.train()训练lora模型:
训练数据,就是[titile+笔记一条]*笔记条数+[title+原文],labels全部非-100,也就是都参与loss计算,没有不参与loss计算的前缀。
将训练完的模型存到文件里。加载文件至vllm(给vllm服务发送/v1/load_lora_adapter请求):
评测完毕后,再将vllm的lora模型给卸掉(卸掉后vllm上是base model):
评测时,只输入Q,不输入self-edit:
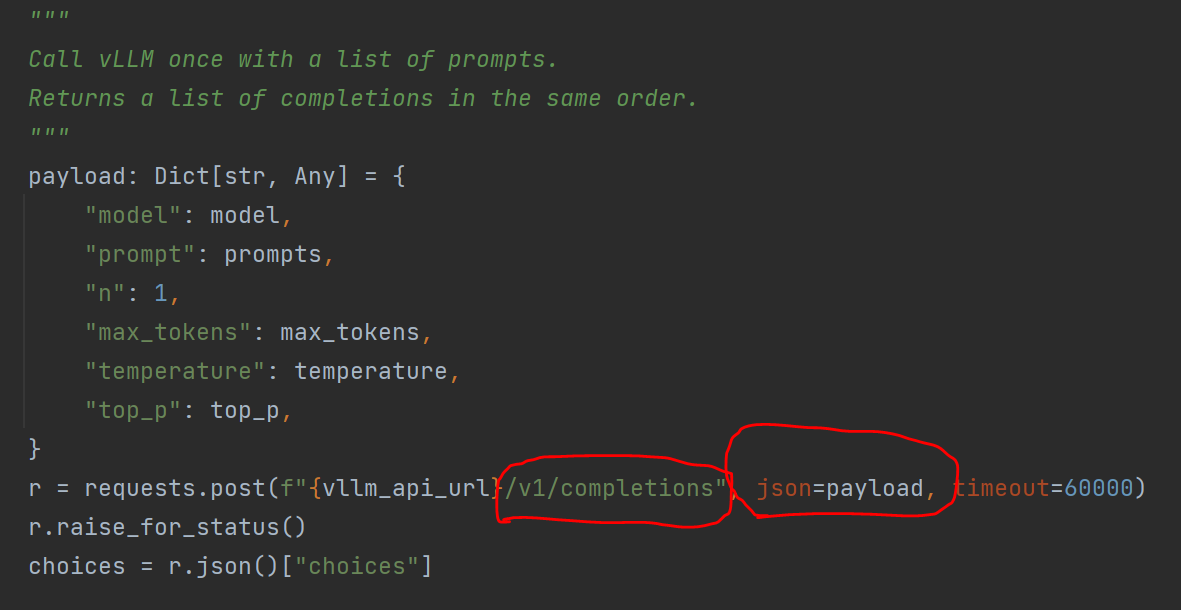
评测调用vllm的/v1/completions,吧model名称传入进去:
评测用的prompt,包含Q、A、模型生成的值:
用gpt-4.1做的评测:
可对比base模型和adaper模型在这批Q上的答对率,分出高下。
返回几个指标:
accuracy: 答对的题数/总题数
texts: 所有题目的推理结果
correct: 所有题目的对错(true/false)
adapter_gain: adapter相比base model的增益,即adapter_acc - base_acc
gains: 1/(-1)/0的数组,该题目adapter对了base错了,则为1;adapter错base对,则为-1;否则为0










将self-edit读入并整理,调用上面的SFT服务进行Fine tune和评测:
sbatch knowledge-incorporation/scripts/query_server.sh
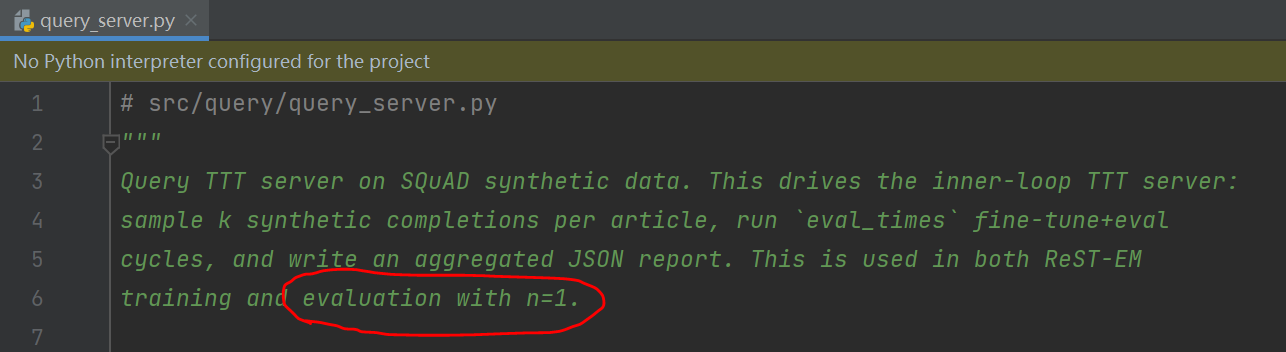
每个文章生成了多组self-edit:
每组edit,是1.2.3.4...这样一条一条的,每条用\n分隔:
选项SPLIT_NEWLINES控制是否将每组的1、2、3、4用\n分割后,当成1个batch来喂给SFT模型去训练;默认是true,当成1个batch。如果设为false,则这组的4条信息整个当成1条样本交给SFT模型去训练。
注意:除了self-edit,还要把原文(即context)也加入到SFT训练数据集里:
注释里也强调了这点:
EVAL_TIMES控制对每组self-edit,进行几次evalute。每次evalute包括了SFT train和QA评判。(这里SFT train有些浪费?我感觉每组self-edit只做1次SFT train,QA评判多次,就可以了?)




构造RL训练数据集:
python3 knowledge-incorporation/src/EM/build_SFT_dataset.py <path/to/result/of/run.json>
读取上一步存盘的结果文件。把prompt(指令+原始文章内容)及其在SFT评测中表现最好的k(默认k=1)个self-edit,存入文件。
跑训练
sbatch knowledge-incorporation/scripts/train_SFT.sh
上一步输出的结果是jsonl文件:
prompt是指令+原文;completion是self-edit(在多个self-edit里,SFT后评测得分最高的那个)。
使用了accelerate:
--deepspeed_config_file内容:
综上,用了:多卡,ZERO-3, offload,bf16,lora
上面的jsonl数据文件,可以被datasets.load_dataset直接加载至dataset:
用的trl.SFTTrainer:
(印证了论文里的"SFT on good self-edits";挑效果好的self-edits,拿做SFT训练)
(trl.SFTTrainer,只将completion的内容去更新loss,prompt的内容不会更新loss)
将lora参数和base model合并至一个model:
保存:






n=1时的评测,用的也是和train同样的pipeline,eval数据-->LLM-->self-edit-->临时SFT-->回答问题。代码里有注释可以佐证:
Continued Pretraining实验(即n=200):
knowledge-incorporation/scripts/CPT.sh
从eval数据集里,每个原文,生成5个self-edit,得到base_val.json数据:
使用这份val数据的self-edits, 去做Continued Pretraining:
读取base_val.json,把所有self-edits制作成训练数据train_sequences,把所有question制作成评测数据eval_questions:
执行一把SFT训练+评测:



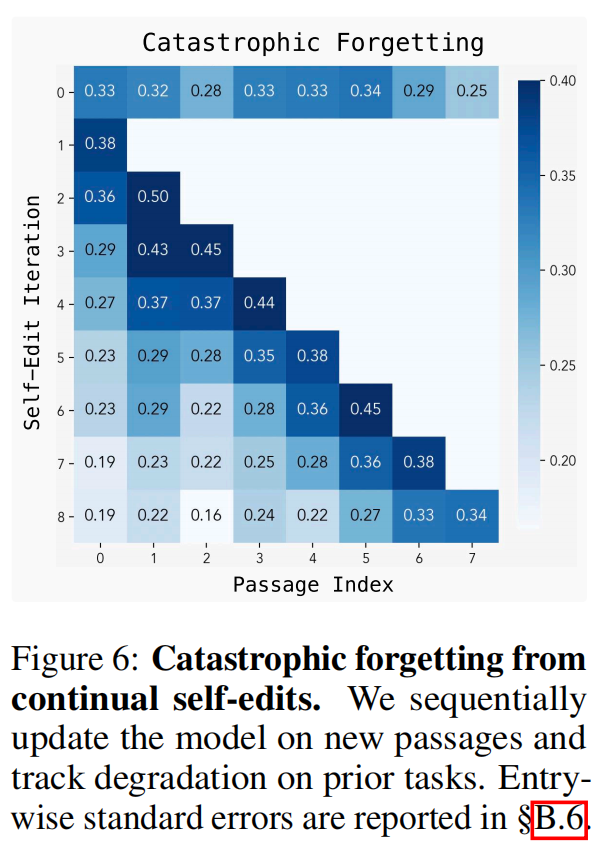
Continoual实验:(论文中第5部分,灾难性遗忘)
sbatch knowledge-incorporation/scripts/continual_self_edits.sh
最外面:多次实验(N_SEQUENCES=8),每次采样一批文章,从同一个模型ckpt开始做continue training,统计这N组实验的平均效果。
里面:每次实验,采样N_DATAPOINTS篇文章;每篇文章,生成self-edit,做SFT训练更新,统计训练过的文章所对应的QA在当前模型上的正确率。这篇文章SFT训练更新后的lora模型,被merge进当前model,生成新的model ckpt,作为下一篇文章的加载模型。


















 190
190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









