



本次爬虫目标是爬取名言网,爬取任意页数的名言
本次爬取工具:requtest、xpath、ua
依旧爬取的纯文本信息,这个网址也是静态网页
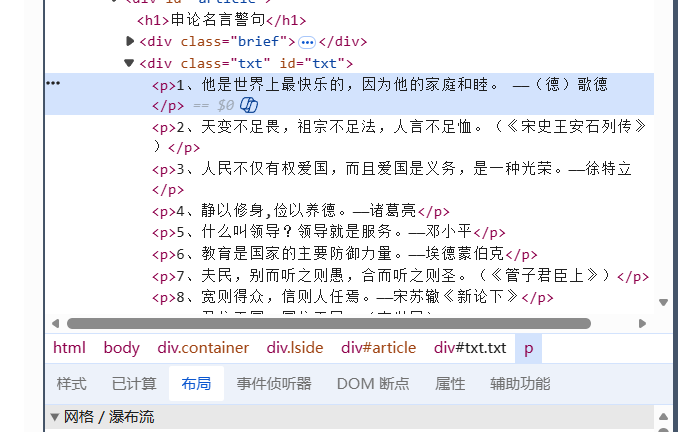
查看div节点,发现这堆要爬取的信息全在同一个节点内,直接复制

然后就是提取信息,经过简单清洗输出,结果如下:

 ‘
‘
然后把这些信息存一下,存到txt中去
’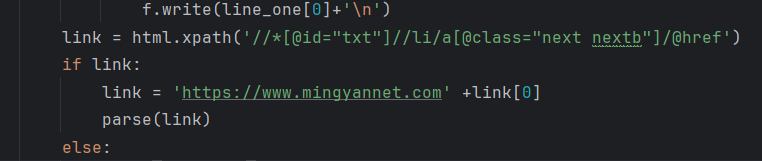
继续使用xpath提取链接,爬取下一页

我这边就设置爬取10页这样,也是很快就爬取了几万条信息,结果如下:
这样,一个简单的名人名句爬虫就完成。
完整代码如下:
import requests
from lxml import etree
from fake_useragent import UserAgent
ua = UserAgent()
user_agent = ua.edge
def parse(url):
headers = {
'user-agent': user_agent,
'referer':url
}
res = requests.get(url=url,headers=headers)
if res.status_code == 200:
res.encoding = 'utf-8'
# print(res.text)
parse_html(res.text)
def parse_html(html):
f = open('名人名言.txt','a+',encoding='utf-8')
html = etree.HTML(html)
lines = html.xpath('//*[@id="txt"]/p')
for line in lines:
line_one = line.xpath('./text()') +line.xpath('./a/text()')
if line_one:
print(line_one[0])
f.write(line_one[0]+'\n')
link = html.xpath('//*[@id="txt"]//li/a[@class="next nextb"]/@href')
if link:
link = 'https://www.mingyannet.com' +link[0]
parse(link)
else:
print('爬取结束')
if __name__ == '__main__':
url = 'https://www.mingyannet.com/mingyan/257311586'
for i in range(1,11):
parse(url)
print(f'开始爬取第{i}页')

















 921
921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









