



本次爬虫主要目标是爬取电影天堂网站里的,一些电影的信息页信息,例如片名、译名、类别等
本次使用的工具为:request库、正则
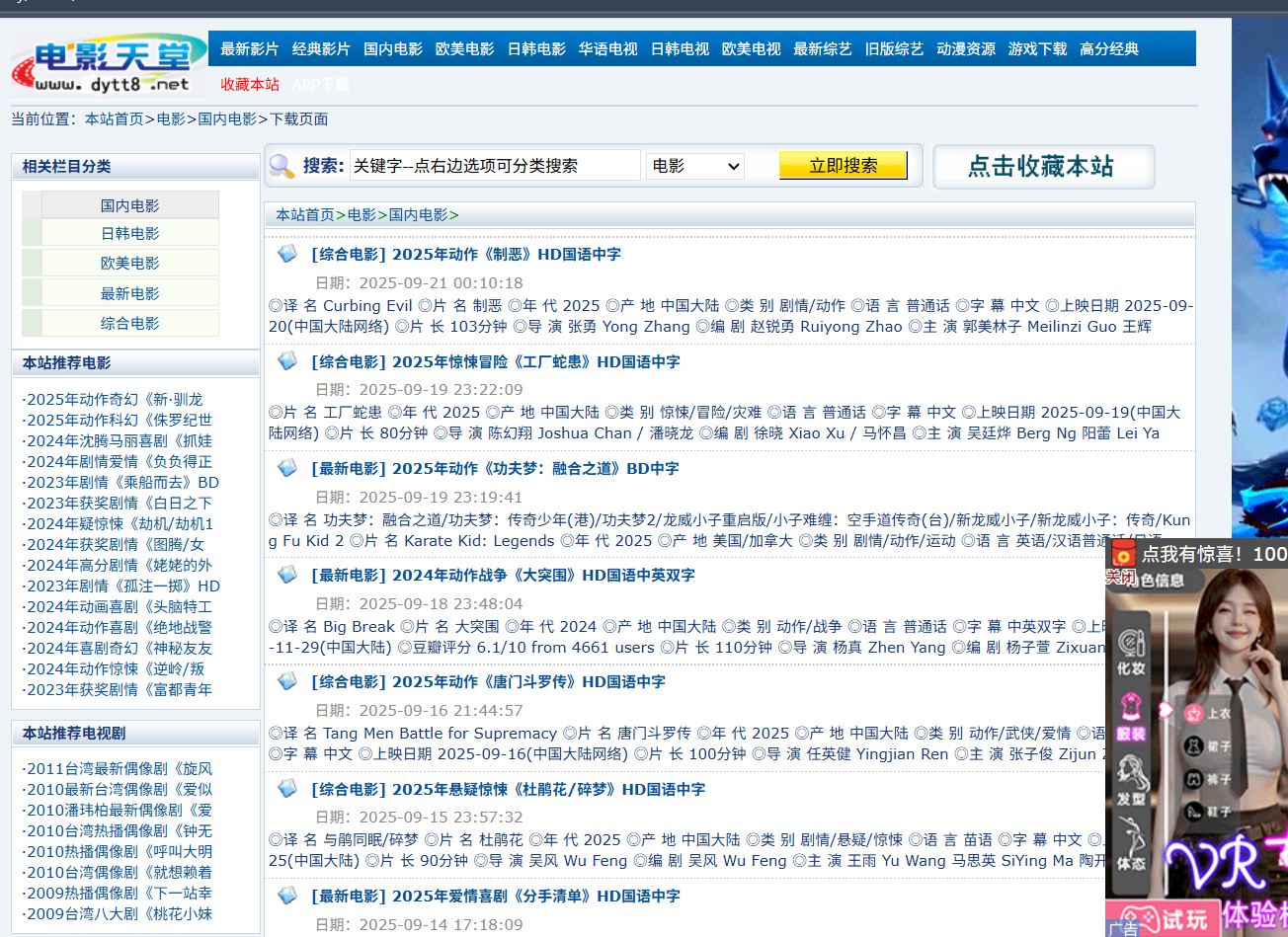

爬取的是国内电影这个分区,如图所示,点击进入爬取详细页信息

导入库

在网页使用Ctrl+u查看可以发现网页编码是gb2312

那我也手动设置一下

通过观察html,我们会发现里面的网址位置都是固定的,所以可以直接使用正则把网址提取出来
,如下图

这样一来我们就获得了详细页的网址链接,并且也拼接完整
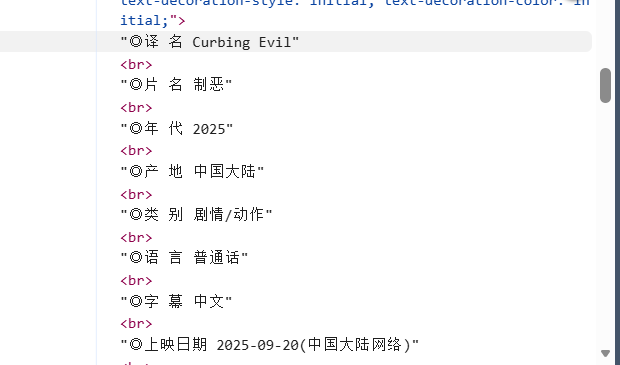
然后我们也发现详细页的div节点的信息也是很容易看到,有着很明显的标志,就是两个套一起的圈圈

所以直接制定使用正则,在请求得到的详细页html中把这些要爬取的信息给提取出来

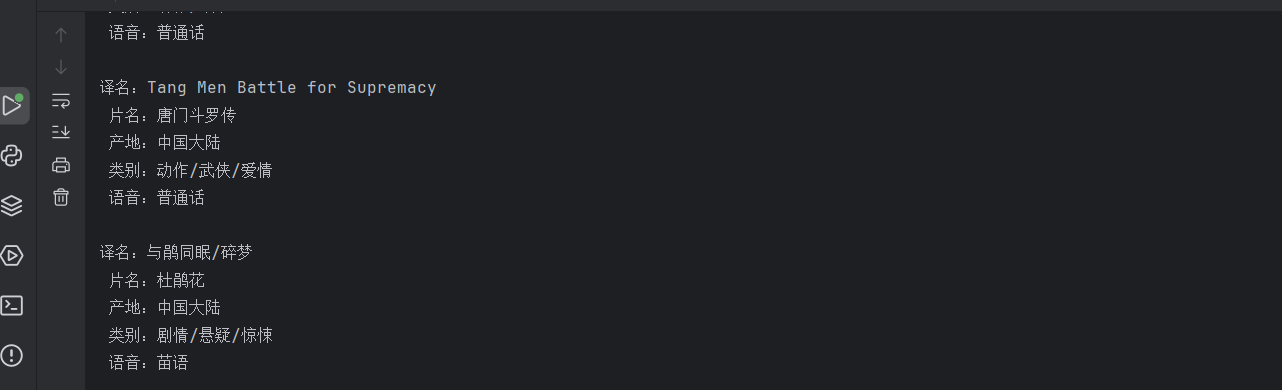
最后输出结果如下图
但是只爬一页肯定是不行的

直接提取下一页的链接,然后继续循环爬取
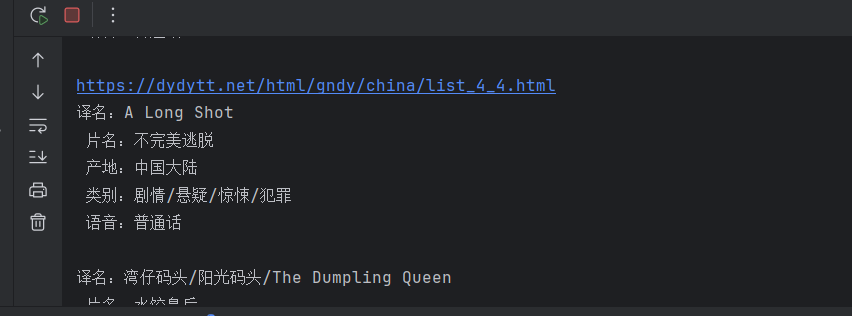
每爬完就输出当前网址,这也是成功了。
本次爬虫所要爬取的信息已成功完成。
完整代码如下:
import requests
import re
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0'
}
def parse(url): # 分页
res = requests.get(url,headers=headers)
res.encoding = 'gb2312'
# print(res.text)
exp = re.compile('<td height="26">.*?href="(.*?)".*?>(.*?)<',re.S) # 获取列表中的电影详细页的网址
# print(exp.findall(res.text))
for Link,j in exp.findall(res.text):
Link = 'https://dydytt.net' + Link
# print(Link, j)
parse_details(Link) # 引用详细页的函数
exp1 = re.compile("<a href='(.*?)'>下一页")
link_ = url.rsplit('/', 1)[0] + '/'
if len(exp1.findall(res.text)) != 0: #如果没有下一页,等于0后就不会执行parse了
Link_next = link_ + exp1.findall(res.text)[0]
print(Link_next)
parse(Link_next)
def parse_details(url): # 详细页
res_sunjion = requests.get(url, headers=headers)
res_sunjion.encoding = 'gb2312'
# print(res_sunjion.text)
exp = re.compile(
'◎译 名\u3000(.*?)<br />.*?◎片 名\u3000(.*?)<br />.*?◎产 地\u3000(.*?)<br />.*?◎类 别\u3000(.*?)<br />◎语 言\u3000(.*?)<',
re.S)
# print(exp.findall(res_sunjion.text))
for title, name, country, classily, language in exp.findall(res_sunjion.text):
print('译名:' + title + '\n', '片名:' + name + '\n', '产地:' + country + '\n', '类别:' + classily + '\n',
'语音:' + language + '\n')
if __name__ == '__main__':
url = "https://dydytt.net/html/gndy/china/index.html"
parse(url)

















 944
944

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









