



本次爬虫目标:爬取b站上的某个短视频视频或番剧。
本次爬虫使用工具/方法:requests、正则
本文仅用于学习
猛地看到b站的限免番剧,或许我们可以把这个试着把这一集爬下来慢慢欣赏
因为b站的视频资源也是放在静态资源的节点里边的,我们直接对该番剧链接发起请求
在此之前的先登录b站,复制一下cookie,如下图:
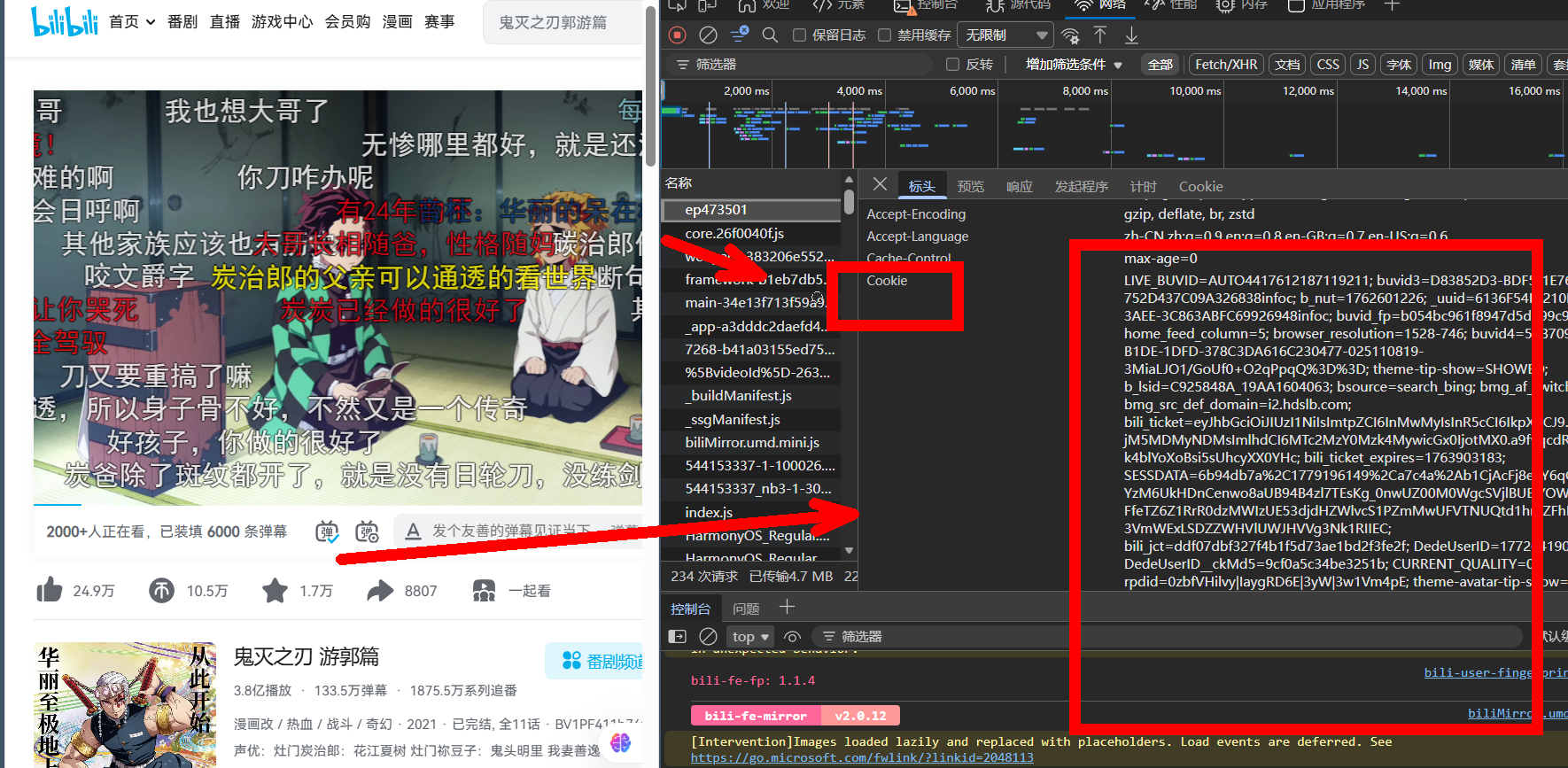
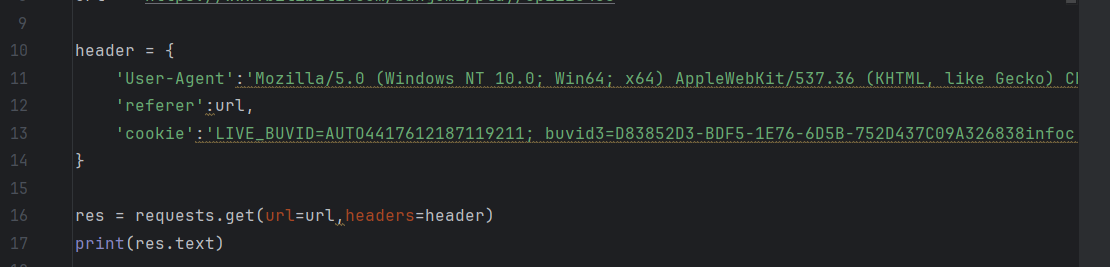
然后就是携带cookie发起请求
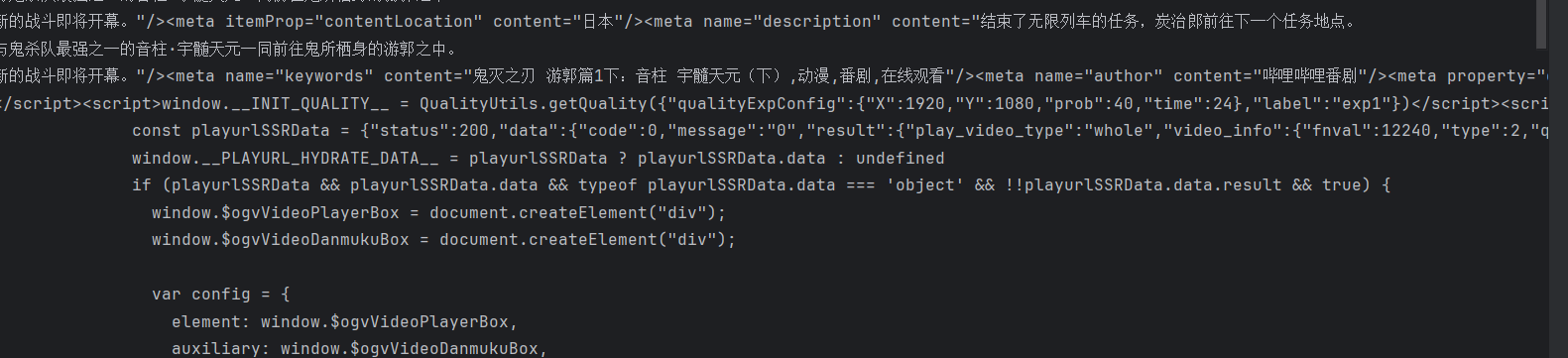
在分析返回的html中,我们可以发现,我们要爬取的视频资源内容全在一个playurlSSRData的字典里边,并且里边有视频信息这样的关键字,如下图:
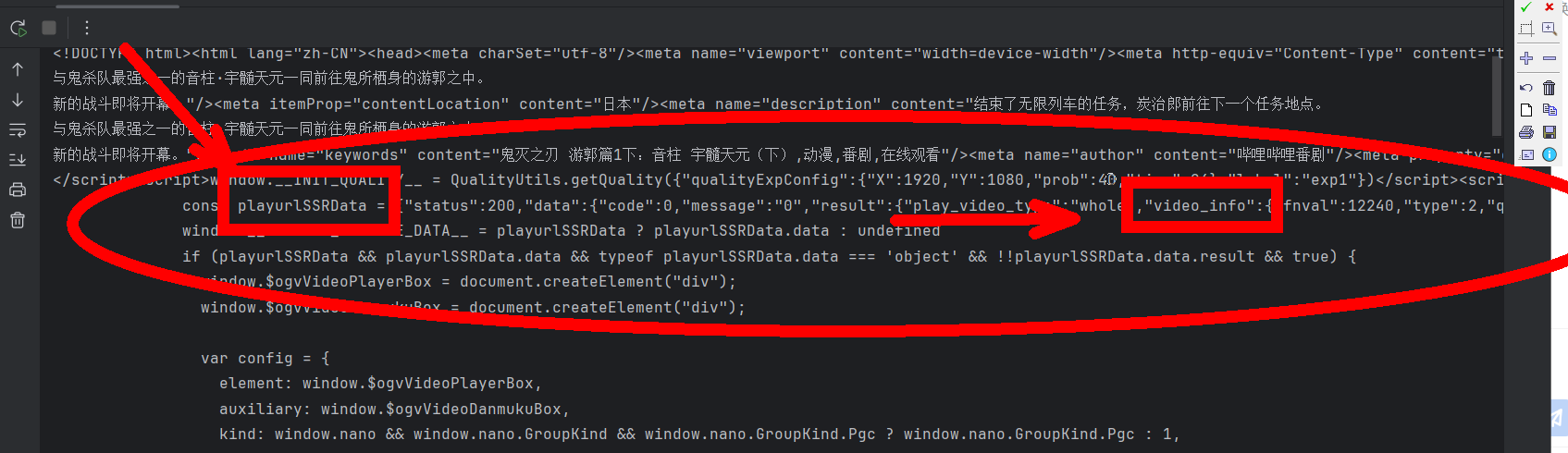
我们可以使用正则把这些东西提取出来
data_all = re.findall('playurlSSRData = (.*?)}}}}', html)[0] + '}}}}'
print(data_all)结果如下:
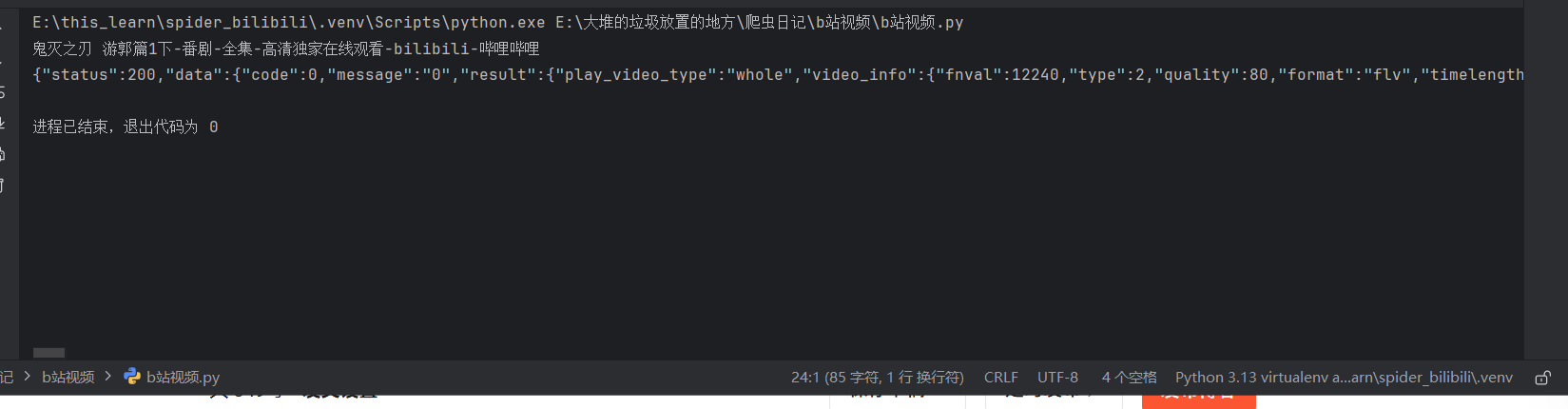
这时候再根据字典的规则去把视频链接提取出来,需要注意的是,b站的视频资源爬取的音频和画面分离的,需要分别爬取画面和音频,所以这里我们也需要分别提取视频的画面链接和音频链接
video_urls = data_all['data']['result']['video_info']['dash']['video'][0]['base_url'] # 视频
audio_urls =data_all['data']['result']['video_info']['dash']['audio'][0]['base_url'] # 音频
print(video_urls)
print(audio_urls)输出结果:

现在分别对这两个,一个画面一个音频发送请求,然后存储成相应的文件
video_content = requests.get(video_urls,headers=header).content
audio_content =requests.get(audio_urls,headers=header).content
# print(video_content.status_code)
with open(f'./视频/{title}.mp4','wb') as v:
v.write(video_content)
with open(f'./视频/{title}.mp3','wb') as a:
a.write(audio_content)结果如下图:
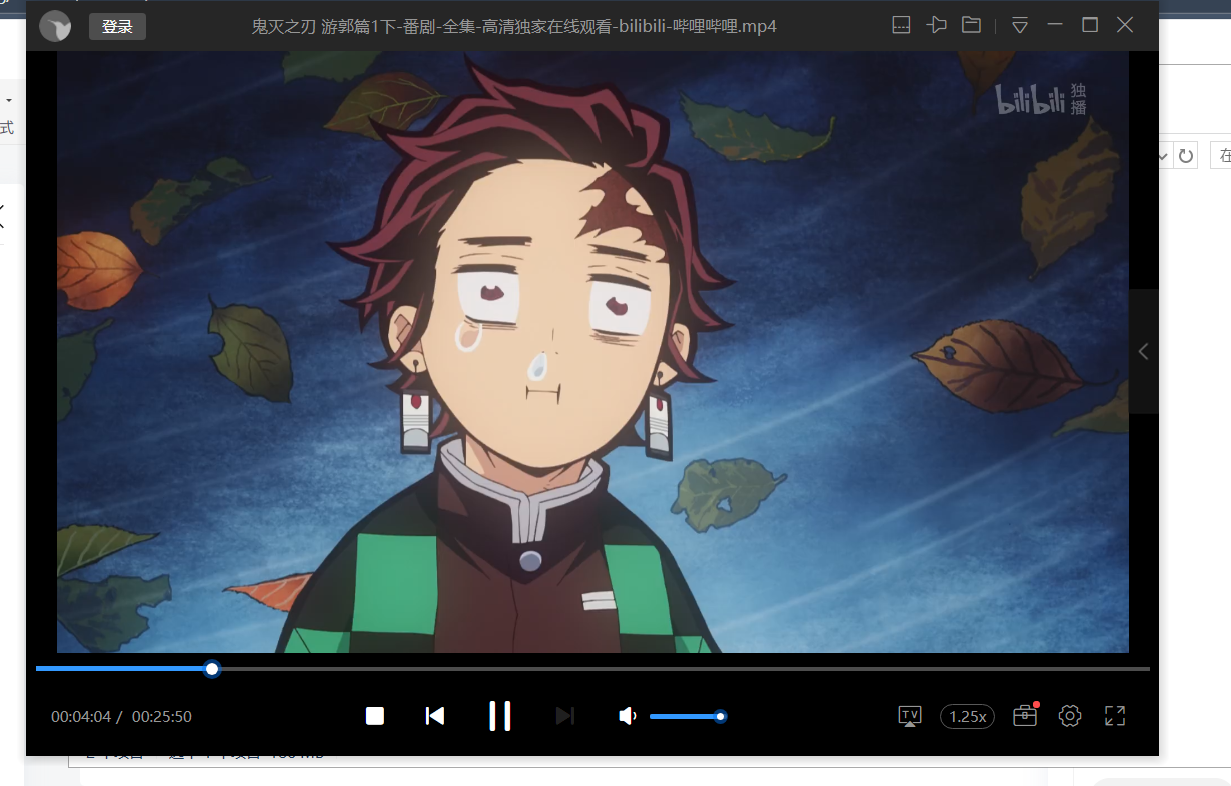
也是成功爬取下来了,但是没有声音,现在还需要把视频和音频合并起来
我们需要下载 FFmpeg - FFmpeg 多媒体框架,然后进行相应的文件路径配置后,在python中也要下载相应的库进行调用
pip install subprocess
经过合成后,视频也是有声音了,音画同步
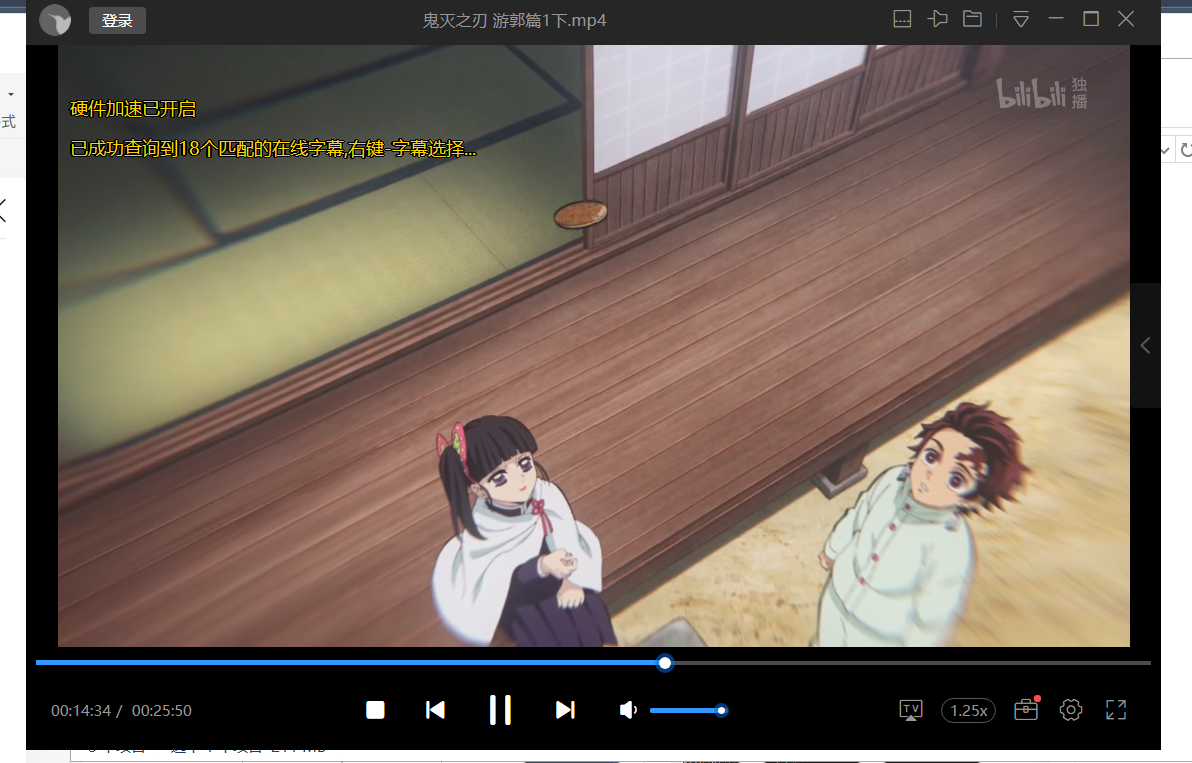
本次爬虫就到此结束了,颇为麻烦的就是要知道视频的地址以什么形式藏在静态的资源节点中,而且是音画不同步,而且爬取的时候需要记得携带cookie
完整代码如下:
# b站
# 视频和音频是分开的 分别爬取
import requests
import re
import json
import logging
import os # 用于删除文件
import subprocess # 用于调用ffmpeg
url = 'https://www.bilibili.com/bangumi/play/ep473501'
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36 Edg/135.0.0.0',
'referer':url,
'cookie':'放cookie'
}
def parse():
res = requests.get(url=url,headers=header)
# print(res.text)
html = res.text
title = re.findall('<title>(.*?)</title>',html)[0]
print(title) # 视频标题
data_all = re.findall('playurlSSRData = (.*?)}}}}}', html)[0] + '}}}}}'
print(data_all)
data_all = json.loads(data_all)
video_urls = data_all['data']['result']['video_info']['dash']['video'][0]['base_url'] # 视频
audio_urls =data_all['data']['result']['video_info']['dash']['audio'][0]['base_url'] # 音频
print(video_urls)
print(audio_urls)
# 爬取视频需要把下面注释解开
# video_content = requests.get(video_urls,headers=header).content
# audio_content =requests.get(audio_urls,headers=header).content
# print(video_content.status_code)
# with open(f'./视频/{title}.mp4','wb') as v:
# v.write(video_content)
# with open(f'./视频/{title}.mp3','wb') as a:
# a.write(audio_content)
return title
def mergeVideoAudio(video_path, audio_path, output_path):
try:
logging.info(f"正在合并视频和音频为 {output_path}...")
ffmpeg_path = r'D:\All_Script\ffmpeg-7.0.2-essentials_build (1)\ffmpeg-7.0.2-essentials_build\bin\ffmpeg.exe' #
command = [ffmpeg_path, '-i', video_path, '-i', audio_path, '-c:v', 'copy', '-c:a', 'aac', '-strict',
'experimental', output_path]
subprocess.run(command, check=True)
logging.info(f"视频和音频合并完成: {output_path}")
# 删除原始的音频和视频文件
if os.path.exists(video_path):
os.remove(video_path)
logging.info(f"已删除视频文件: {video_path}")
if os.path.exists(audio_path):
os.remove(audio_path)
logging.info(f"已删除音频文件: {audio_path}")
except subprocess.CalledProcessError as e:
logging.error(f"合并视频和音频时出错: {e}")
if __name__ == '__main__':
title = parse()
video_path = f'./视频/{title}.mp4'
audio_path = f'./视频/{title}.mp3'
title_ = title.replace('-番剧-全集-高清独家在线观看-bilibili-哔哩哔哩','')
output_path = f'./视频/{title_}.mp4'
mergeVideoAudio(video_path, audio_path, output_path)

















 967
967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









