



本次爬虫目标网站为:2345天气预报,链接:天气,天气预报查询,24小时,今天,明天,未来一周7天,10天,15天,40天查询_2345天气预报
本次爬虫目标:爬取佛山市南海区的天气,包括日期,温度,天气,温度等信息
本次爬虫选取的工具:requests、正则、UA,XHR接口
反爬措施:使用了ua浏览器指纹、使用了浏览器路径、携带正确的请求参数
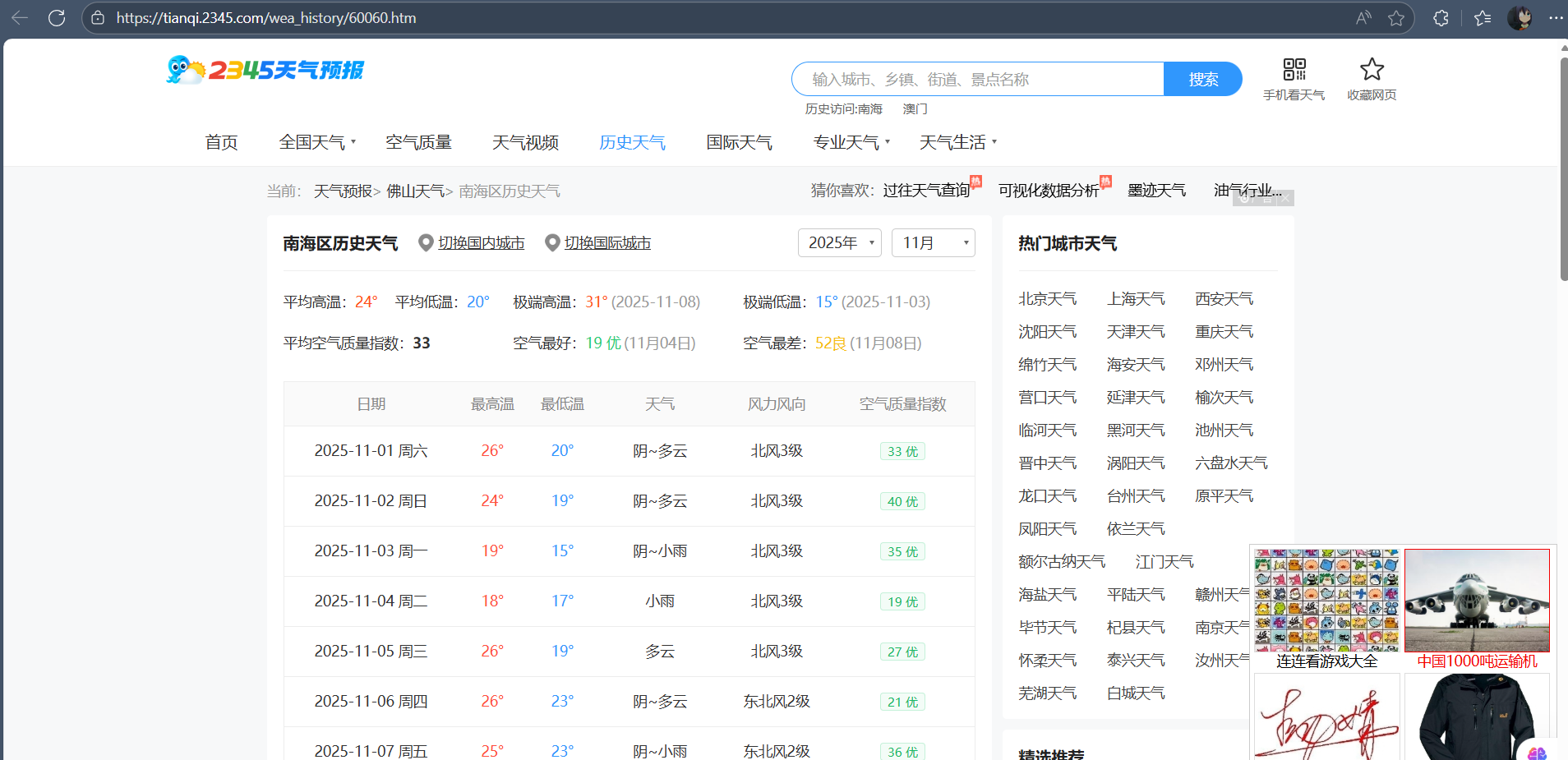
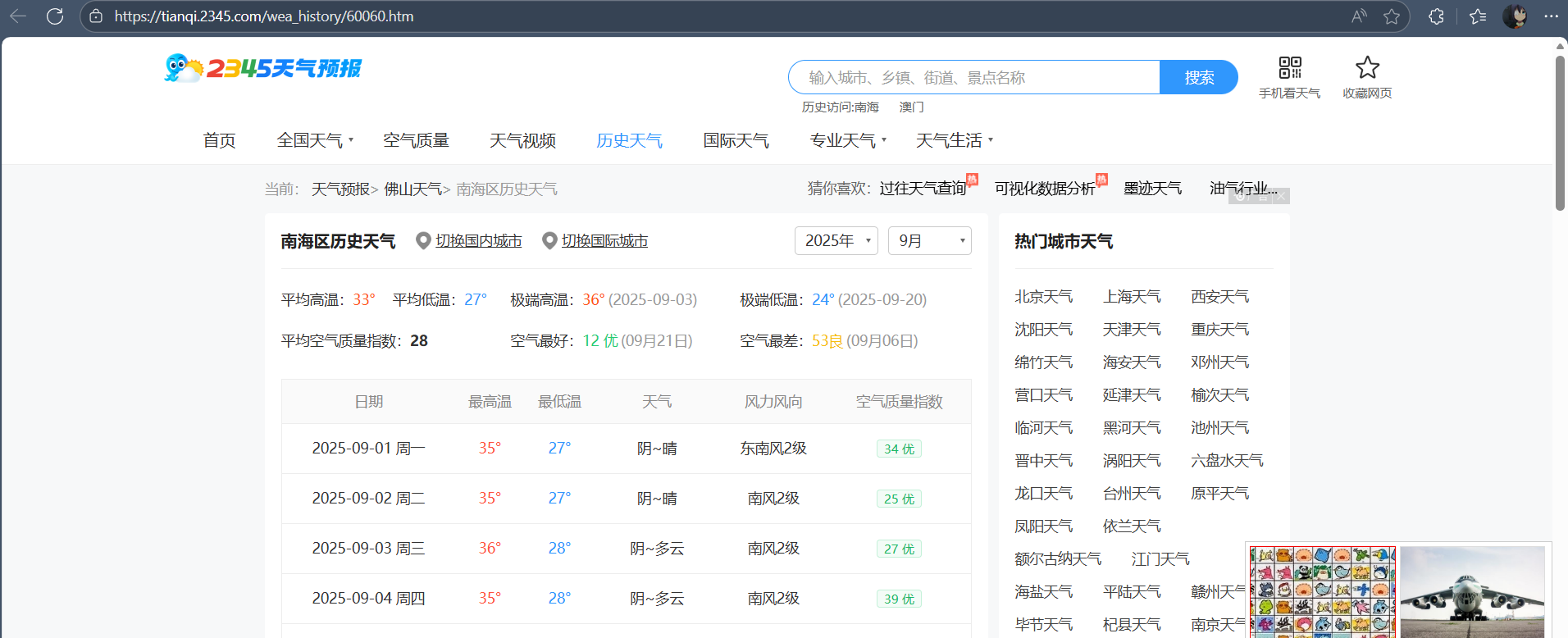
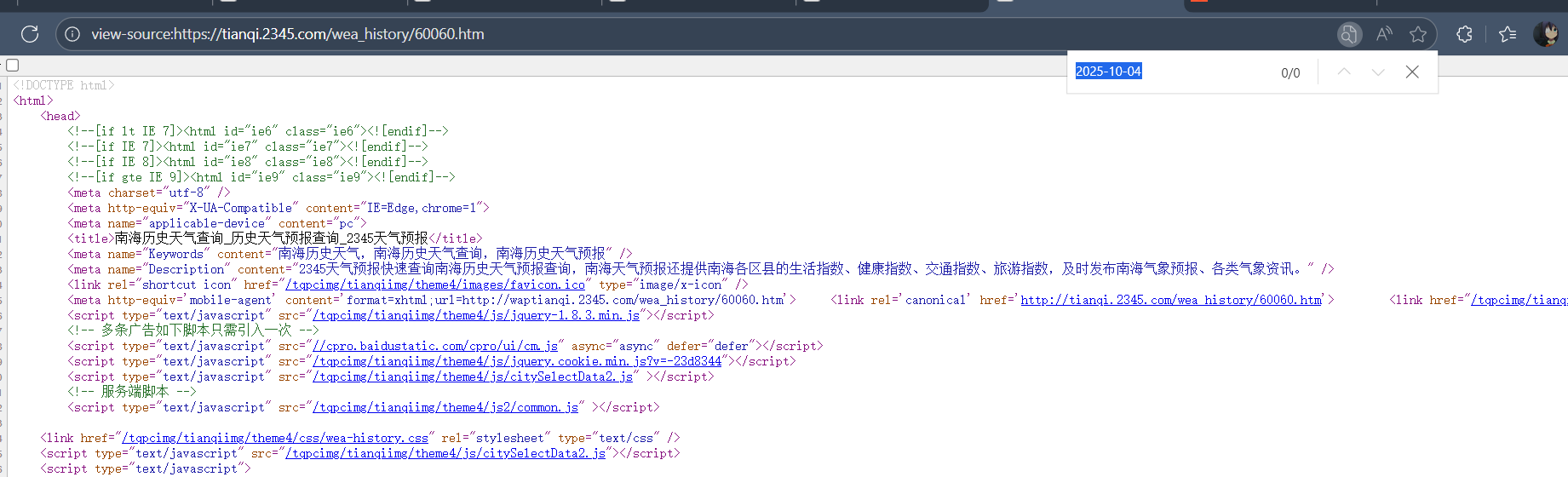
通过以上三图张图我们可以发现,在历史天气中,不一样的天气和日期都在同一个网址显示,但日期又在html中找不到,说明这个网页不是静态的,是动态Ajax的
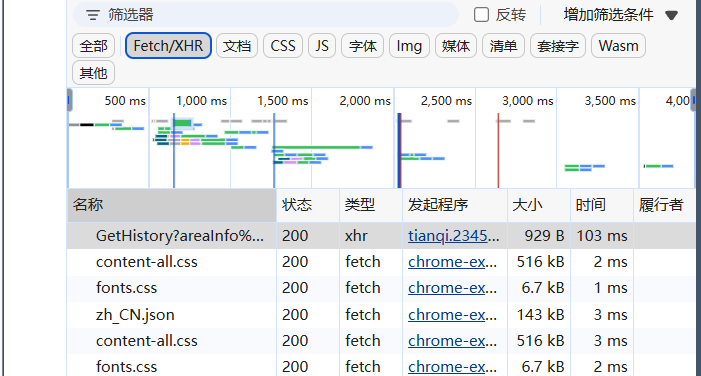
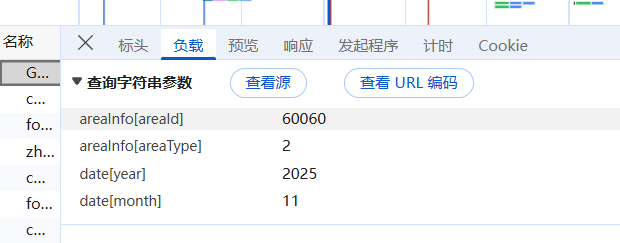
所以可以通过使用网页检查,找到他的XHR接口,并且复制他的负载信息和相关的网址
data = {
'areaInfo[areaId]': '60060',
'areaInfo[areaType]': '2',
'date[year]': '2025',
'date[month]': 9
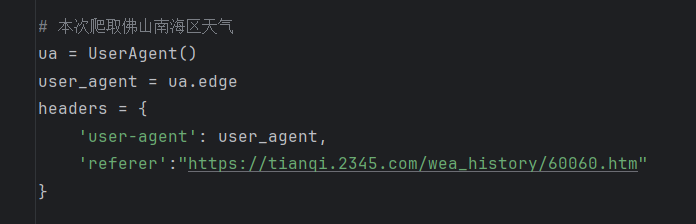
}url = 'https://tianqi.2345.com/Pc/GetHistory'发起请求的时候就携带上这个请求参数(负载),而且要注意做好反爬措施,比如我就在请求头中加入了网址路径,然后使用ua池的浏览器指纹来避免反爬,如下图
res = requests.get(url=url,headers=headers,params=data)可以返回一个json格式的数据,如下图:

按照字典的处理方法,把data给提取出来,会得到以下内容:
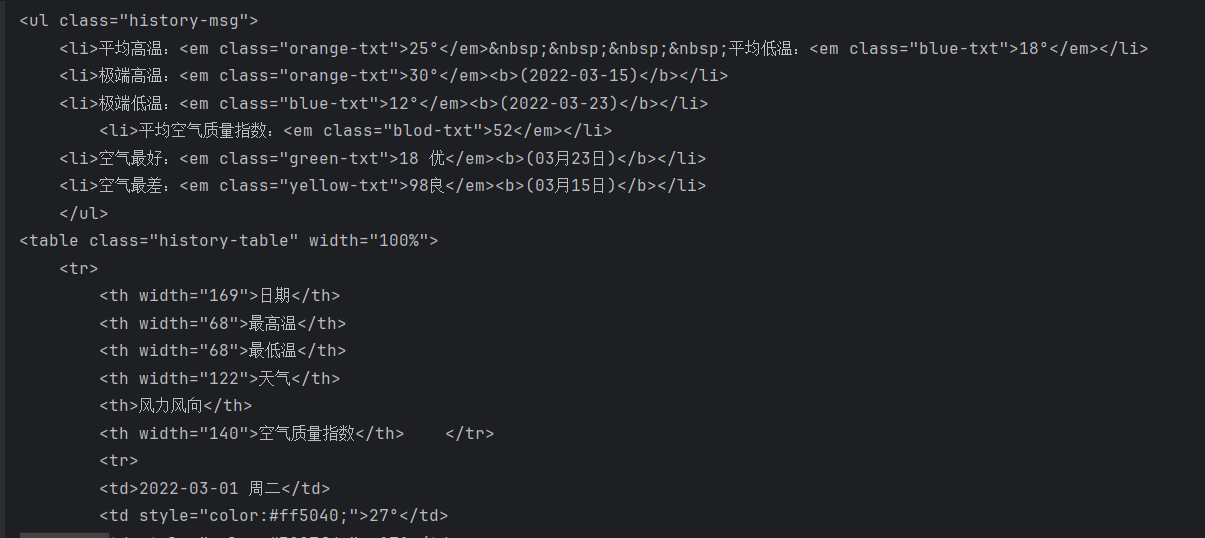
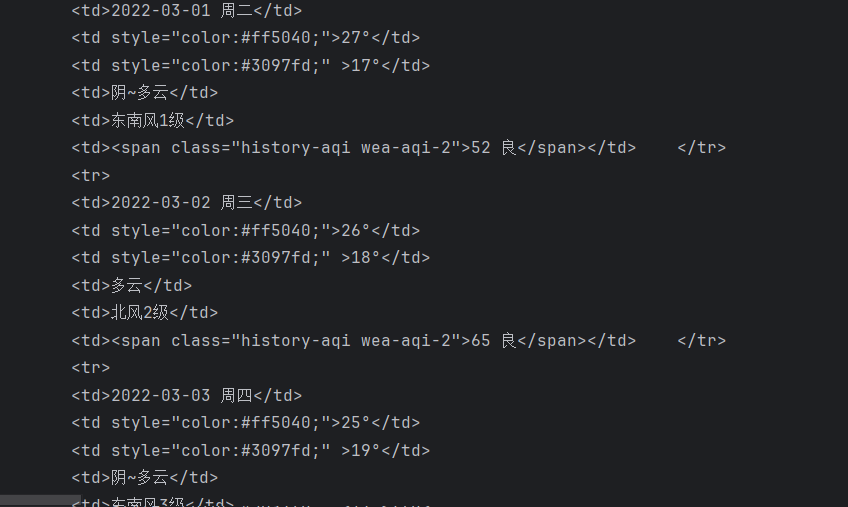
我们会发现所要爬取的天气内容都在<td></td>这个节点里边,这就很好办了,直接用正则把这些内容提取出来,结果如下:

一下子几乎就清洗完成了,除了空气质量这一条信息
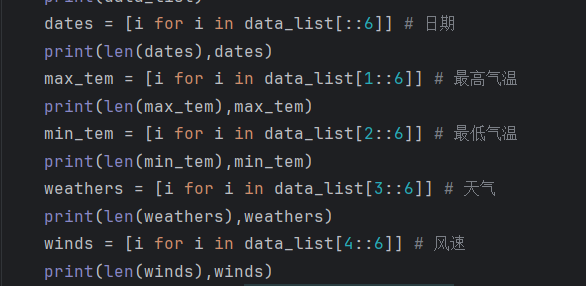
把日期、天气等数据提取一下,得到一下结果

同理,把没清洗干净的空气质量这条数据可以结合一下正则清洗一下

结果如下:

也是很成功!
接下来就是建一个字典,把这些数据存起来,并且存入csv
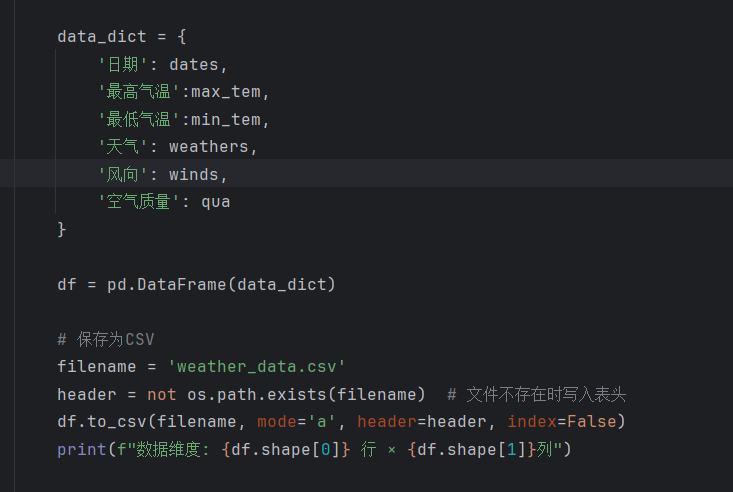
存储结果,如下图:
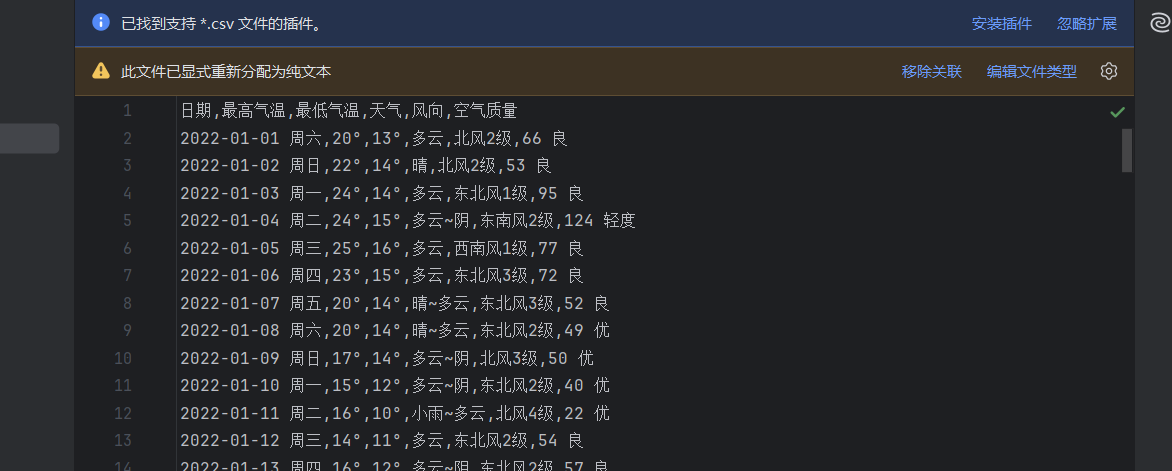
现在,天气数据的爬取与存储就完成了!
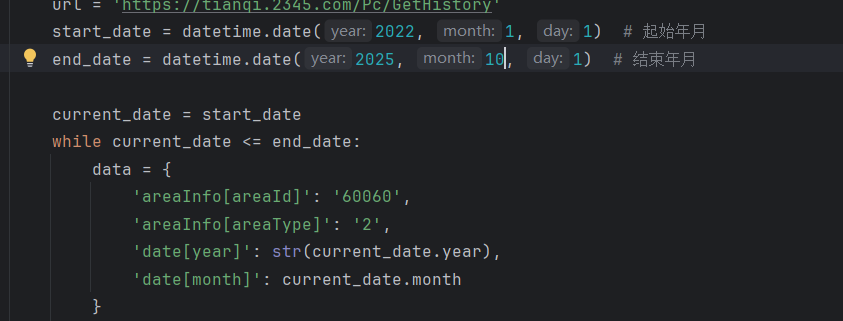
然后可以在润色一下,可以选择爬取多少年到多少年几月的数据,我这里就选择爬取了22年1月到目前25年10月的所选地区的历史天气,如下图:
完整代码如下:
import requests
from fake_useragent import UserAgent
import json
import re
import pandas as pd
import os
import datetime
# 本次爬取佛山南海区天气
ua = UserAgent()
user_agent = ua.edge
headers = {
'user-agent': user_agent,
'referer':"https://tianqi.2345.com/wea_history/60060.htm"
}
def parse(url,data):
res = requests.get(url=url,headers=headers,params=data)
if res.status_code == 200:
return res.json()
else:
print(f'当前状态码为{res.status_code},网页访问不了')
# print(res.status_code)
# print(res.json())
# with open('tqi.json','w',encoding='utf-8') as f:
# json.dump(res.json(), f, ensure_ascii=False, indent=5)
def parse_down(data_json):
# with open('tqi.json','r',encoding='utf-8') as f:
# data = json.load(f)
# print(data['data'])
data_w = data_json
weather_data = data_w['data']
# print(weather_data)
exp = re.compile('<td.*?>(.*?)</td>', re.S)
data_list = exp.findall(weather_data) # 包含天气数据的信息
print(data_list)
dates = [i for i in data_list[::6]] # 日期
print(len(dates),dates)
max_tem = [i for i in data_list[1::6]] # 最高气温
print(len(max_tem),max_tem)
min_tem = [i for i in data_list[2::6]] # 最低气温
print(len(min_tem),min_tem)
weathers = [i for i in data_list[3::6]] # 天气
print(len(weathers),weathers)
winds = [i for i in data_list[4::6]] # 风速
print(len(winds),winds)
exp_t = re.compile('<span.*?">(.*?)</span')
# qua = exp_t.findall(data_list)
qua = [exp_t.findall(i)[0] for i in data_list[5::6]] # 空气质量
print(len(qua),qua)
data_dict = {
'日期': dates,
'最高气温':max_tem,
'最低气温':min_tem,
'天气': weathers,
'风向': winds,
'空气质量': qua
}
df = pd.DataFrame(data_dict)
# 保存为CSV
filename = 'weather_data.csv'
header = not os.path.exists(filename) # 文件不存在时写入表头
df.to_csv(filename, mode='a', header=header, index=False)
print(f"数据维度: {df.shape[0]} 行 × {df.shape[1]}列")
if __name__ == '__main__':
url = 'https://tianqi.2345.com/Pc/GetHistory'
start_date = datetime.date(2022, 1, 1) # 起始年月
end_date = datetime.date(2025, 10, 1) # 结束年月
current_date = start_date
while current_date <= end_date:
data = {
'areaInfo[areaId]': '60060',
'areaInfo[areaType]': '2',
'date[year]': str(current_date.year),
'date[month]': current_date.month
}
data_json = parse(url, data)
parse_down(data_json)
current_date += datetime.timedelta(days=32) # 跳到下个月

















 3369
3369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









