



本次爬虫主要目标是爬取豆瓣top250,爬取排行榜上的电影名称,导演、地区、简语等
本次爬虫选取的技术栈为request库,使用etree.HTML解析,xpath定位

导入所需库

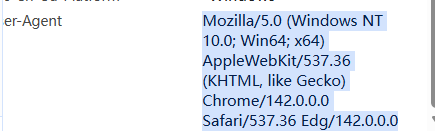
在网页检查中找到并且使用简单的请求头
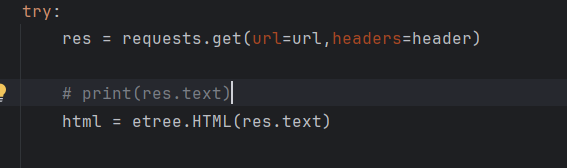
提取网页文本并且进行解析
![]()
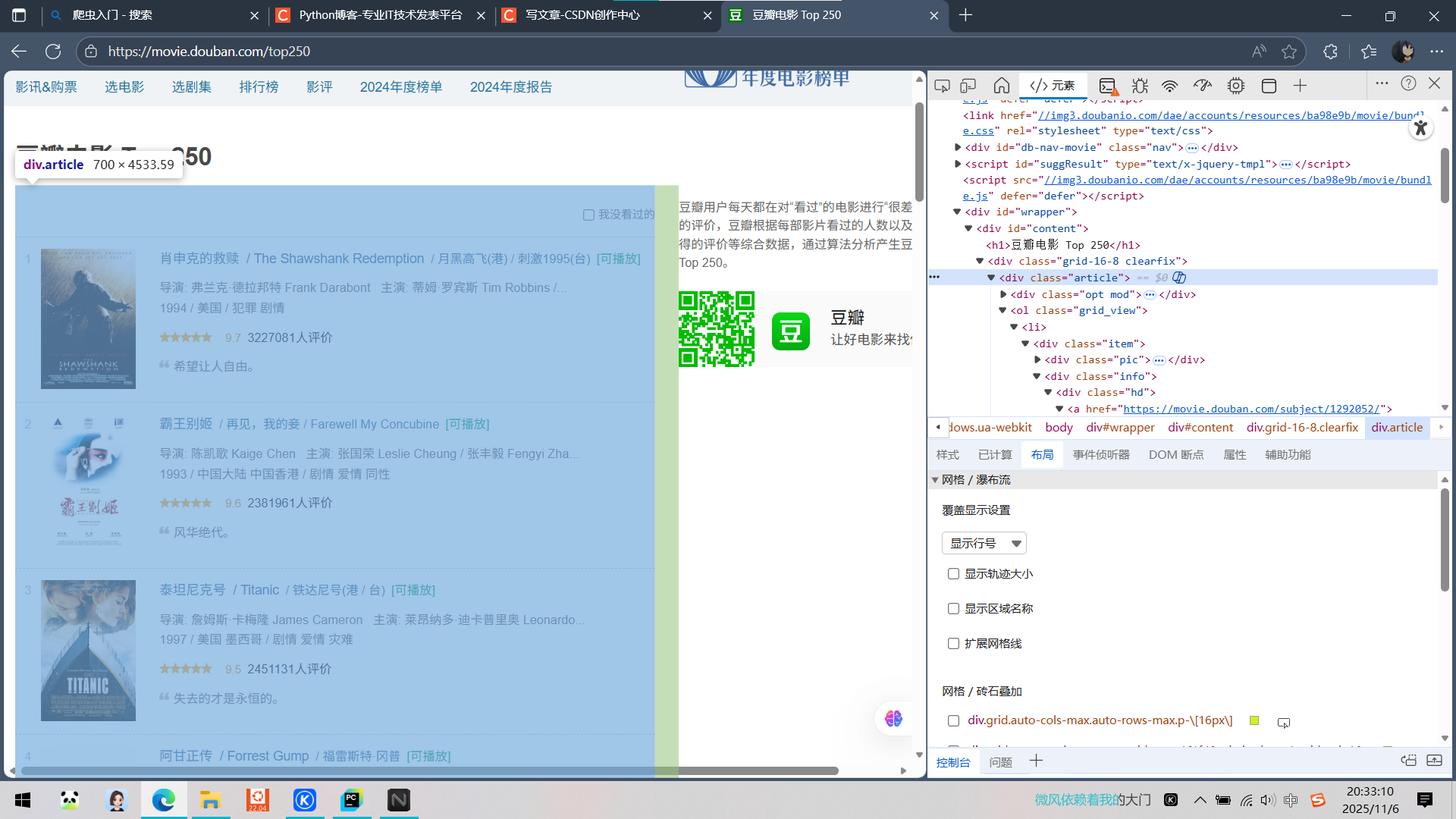
对要爬取的东西先来个总的定位,我要爬取的东西,所有的电影信息都在其中

依旧找到要爬取的信息位置,并且把相应的xpath复制下来,使用xpath定位,在所有的定位中使用
![]()
提取出需要爬取的题目信息
导演、地区等信息同理

但仅仅这样还不行,得到的信息有一些乱七八糟的东西,需要把这些换行符、乱码处理掉

结果简单清洗后就好很多了
我们不能只爬取一页,依旧使用xpath提取下一页的链接,方便继续爬取
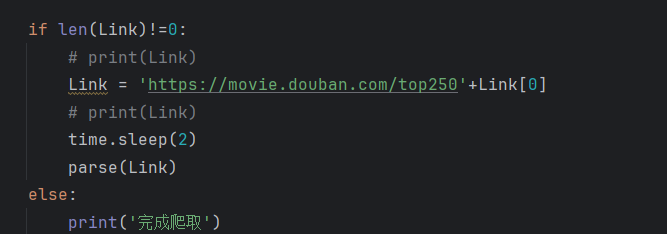
做一个简单判定,把链接拼接出来,继续爬取直至爬完10页豆瓣电影排行的信息
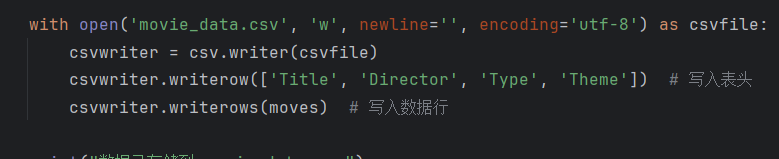
最后就是简单把数据存到csv文件中

最终结果如上
完整代码如下:
from itertools import zip_longest
import requests
from lxml import etree
import csv
import time
url = 'https://movie.douban.com/top250'
header = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0'
}
moves = []
def parse(url):
try:
res = requests.get(url=url,headers=header)
# print(res.text)
html = etree.HTML(res.text)
datas = html.xpath('//div[@class="article"]')
for data in datas:
title = data.xpath('.//div/a/span[@class="title"][1]/text()')
director = data.xpath('.//div[@class="bd"]/p[1]/text()[1]')
type = data.xpath('.//div[@class="bd"]/p[1]/text()[2]')
theme = data.xpath('.//div[@class="bd"]/p[2]/span/text()[1]')
# print(title)
# print(director)
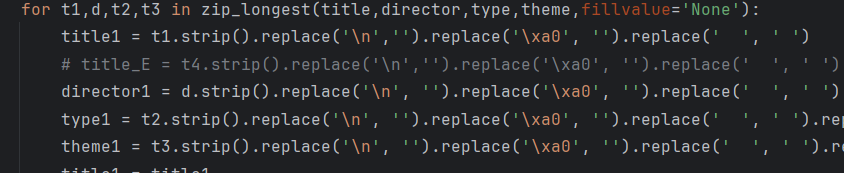
for t1,d,t2,t3 in zip_longest(title,director,type,theme,fillvalue='None'):
title1 = t1.strip().replace('\n','').replace('\xa0', '').replace(' ', ' ')
# title_E = t4.strip().replace('\n','').replace('\xa0', '').replace(' ', ' ')
director1 = d.strip().replace('\n', '').replace('\xa0', '').replace(' ', ' ').replace('...','').replace('/','')
type1 = t2.strip().replace('\n', '').replace('\xa0', '').replace(' ', ' ').replace('...','').replace('/','')
theme1 = t3.strip().replace('\n', '').replace('\xa0', '').replace(' ', ' ').replace('...','').replace('/','')
title1 = title1
print('名字:'+title1)
print('导演:'+director1)
print('地区\类型:'+type1)
print('简语:'+theme1)
moves.append([title1,director1,type1,theme1])
Link = html.xpath('//*[@id="content"]/div/div[1]/div[2]/span[3]/a/@href')
if len(Link)!=0:
# print(Link)
Link = 'https://movie.douban.com/top250'+Link[0]
# print(Link)
time.sleep(2)
parse(Link)
else:
print('完成爬取')
except Exception as e:
print(f'错误{e}')
if __name__ == '__main__':
parse(url)
with open('movie_data.csv', 'w', newline='', encoding='utf-8') as csvfile:
csvwriter = csv.writer(csvfile)
csvwriter.writerow(['Title', 'Director', 'Type', 'Theme']) # 写入表头
csvwriter.writerows(moves) # 写入数据行
print("数据已存储到 movie_data.csv")

















 368
368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









