






 本文介绍了一种名为FSAF的目标检测模块,该模块能够自动选择合适的尺度并进行无锚框检测,提高了长宽比悬殊的目标检测性能。通过引入在线特征选择机制,FSAF在训练过程中自动确定最佳特征层,并在推理阶段输出最有可能的结果。
本文介绍了一种名为FSAF的目标检测模块,该模块能够自动选择合适的尺度并进行无锚框检测,提高了长宽比悬殊的目标检测性能。通过引入在线特征选择机制,FSAF在训练过程中自动确定最佳特征层,并在推理阶段输出最有可能的结果。
《Feature Selective Anchor-Free Module for Single-Shot Object Detection》是由Carnegie Mellon大学Chenchen Zhu等提出的自动选择合适的尺度以及无anchor的目标检测方法。实验对比图如下

从上图可以看出,加了FSAF模块的RetinaNet,能把一些长宽比比较悬殊的目标检测出来。为什么加入了FSAF模块可以有这种效果?首先:
1、对比下加入FSAF模块前后的RetinaNet网络的结构:
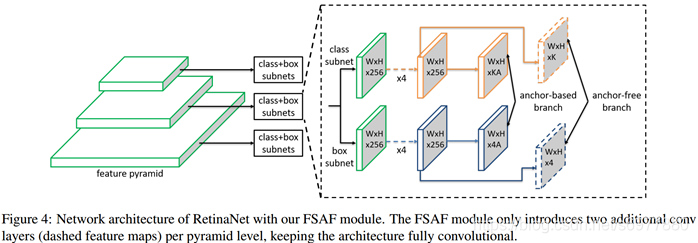
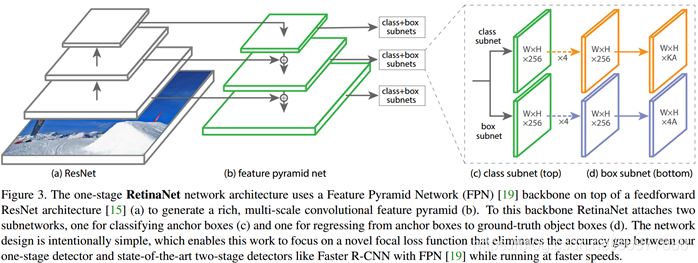
相对于原始的RetinaNet网络,FSAF模块只是两个卷积层,一个嵌入到分类支路中,另一个嵌入到回归支路中。
为什么在两个支路中分别嵌入一个卷积层就可以实现特征选择,从而达到良好的检测效果?
2、损失函数
作者首先定义了一些变量:
1)标签为kkk的实例的bounding box为b=[x,y,w,h]b=[x, y, w, h]b=[x,y,w,h]。(x,y)(x, y)(x,y)是矩形的中心,w,hw, hw,h分别是矩形的宽和高。
2)其在PlP_lPl特征层上的box坐标为bpl=[xpl,ypl,wpl,hpl]b_p^l = [x_p^l, y_p^l, w_p^l, h_p^l]bpl=[xpl,ypl,wpl,hpl],即其坐标可表示为bpl=b/2lb_p^l = b / 2^lbpl=b/2l。
3)有效box(effective box):bel=[xel,yel,wel,hel]b_e^l = [x_e^l, y_e^l, w_e^l, h_e^l]bel=[xel,yel,wel,hel];可忽略box(ignoring box):bil=[xil,yil,wil,hil]b_i^l = [x_i^l, y_i^l, w_i^l, h_i^l]bil=[xil,yil,wil,hil]。这两个box大小分别和bplb_p^lbpl成ϵe\epsilon_eϵe和ϵi\epsilon_iϵi倍的关系。即xel=xpl,yel=ypl,wel=ϵewpl,hel=ϵehplx_e^l=x_p^l, y_e^l=y_p^l, w_e^l=\epsilon_ew_p^l, h_e^l=\epsilon_eh_p^lxel=xpl,yel=ypl,wel=ϵewpl,hel=ϵehpl,xil=xpl,yil=ypl,wil=ϵiwpl,hil=ϵihplx_i^l=x_p^l, y_i^l=y_p^l, w_i^l=\epsilon_iw_p^l, h_i^l=\epsilon_ih_p^lxil=xpl,yil=ypl,wil=ϵiwpl,hil=ϵihpl
文章中的ϵe=0.2,ϵi=0.5\epsilon_e=0.2, \epsilon_i=0.5ϵe=0.2,ϵi=0.5。
定义完这些参数,就可计算分类和回归的输出:
1)分类输出
分类输出层输出KKK个maps,每个map对应一个类。一个样本以三种方式影响第kkk层特征。第一,有效box区域:belb_e^lbel,这是一个正样本区域;第二,除去有效box的可忽略box区域:(bil−bel)(b_i^l-b_e^l)(bil−bel),这部分区域的梯度不传回去;第三,相邻特征层的可忽略boxes(bil−1,bil+1)(b_i^{l-1}, b_i^{l+1})(bil−1,bil+1)也是可忽略的。其余的区域都是负样本区域。如果在一个特征层上,有两个相交的有效boxes,则较小的样本有较高的优先级。
loss计算采用α=0.25,γ=2.0\alpha=0.25, \gamma=2.0α=0.25,γ=2.0的Focal loss。
2)回归输出
回归支路只计算有效区域belb_e^lbel内的点。对于区域内的每个点(i,j)(i, j)(i,j),其对应的projected box是一个四维矢量di,jl=[dti,jl,dli,jl,dbi,jl,dri,jl]\bold{d}_{i,j}^l=[d_{t_{i,j}}^l,d_{l_{i,j}}^l,d_{b_{i,j}}^l,d_{r_{i,j}}^l]di,jl=[dti,jl,dli,jl,dbi,jl,dri,jl],其各分量表示当前点(i,j)(i, j)(i,j)和bplb_p^lbpl上、左、下、右边界的距离。用SSS对di,jl\bold{d}_{i,j}^ldi,jl进行归一化,即每个点(i,j)(i, j)(i,j)的矢量为di,jl/S\bold{d}_{i,j}^l / Sdi,jl/S。SSS取值为4。有效区域之外的区域都忽略。Loss采用IoU loss。
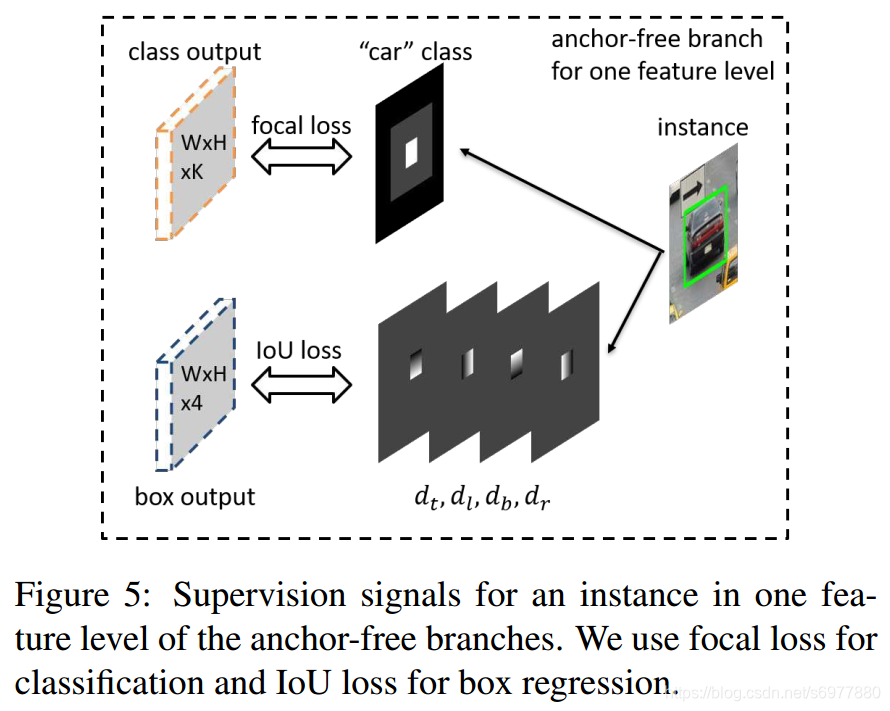
3)前向输出
对于点(i,j)(i, j)(i,j),其前向网络输出为[o^ti,j,o^li,j,o^bi,j,o^ri,j][\widehat{o}_{t_{i,j}}, \widehat{o}_{l_{i,j}}, \widehat{o}_{b_{i,j}}, \widehat{o}_{r_{i,j}}][oti,j,oli,j,obi,j,ori,j],则预测的距各边的距离为[So^ti,j,So^li,j,So^bi,j,So^ri,j][S\widehat{o}_{t_{i,j}}, S\widehat{o}_{l_{i,j}}, S\widehat{o}_{b_{i,j}}, S\widehat{o}_{r_{i,j}}][Soti,j,Soli,j,Sobi,j,Sori,j]。则输出的左上角和右下角分别为(i−So^ti,j,j−So^li,j)(i-S\widehat{o}_{t_{i,j}}, j-S\widehat{o}_{l_{i,j}})(i−Soti,j,j−Soli,j)、(i+So^bi,j,j+So^ri,j)(i+S\widehat{o}_{b_{i,j}}, j+S\widehat{o}_{r_{i,j}})(i+Sobi,j,j+Sori,j)。将得到的点放大2l2^l2l倍就可以得到输出box在原图像上的位置。
输出box的置信度和类别由最大score以及对应的类别决定。
那如何选择合适的输出层得到结果呢?
3、在线特征选择
自动选择合适的特征层得到结果。
在训练阶段:设有一个样本III,其在PlP_lPl层的分类损失和box回归损失分别为LFLI(l)L_{FL}^I(l)LFLI(l)和LIoUI(l)L_{IoU}^I(l)LIoUI(l)。选择最小损失的层为最优的层:
l∗=argminlLFLI(l)+LIoUI(l)l^* = arg \underset{l}{min} L_{FL}^I(l) + L_{IoU}^I(l)l∗=arglminLFLI(l)+LIoUI(l)
在训练时,将l∗l^*l∗层的损失传递回去,进行学习。
在推理时,无需选择哪个层,只需要将置信度最高的层的预测结果输出即可。
4、结合使用去推理和训练
在使用中,anchor-based和FSAF模块时同时使用的
推理阶段
在FSAF模块中,每一层选取置信度最高的1k个输出,得到输出,与anchor-based模块的输出合并,然后采用NMS得到最终的输出结果
训练优化
整个网络的损失是FSAF和anchor-based的加权和。设anchor-based的损失为LabL^{ab}Lab,anchor-free模块的分类和回归损失分别为LclsafL_{cls}^{af}Lclsaf、LregafL_{reg}^{af}Lregaf,则网络的总损失为L=Lab+λ(Lclsaf+Lregaf)L = L^{ab} + \lambda(L_{cls}^{af} + L_{reg}^{af})L=Lab+λ(Lclsaf+Lregaf),其中λ\lambdaλ是anchor-based分支的权重,本章中的设置为λ=0.5\lambda=0.5λ=0.5。
初始化
具体参照论文
从上面对FSAF模块分析可知,FSAF模块在目标检测时,没有像anchor-based方法那样对box长宽比有限制,从理论上看,任何长宽比都可以检测到,因此在第一张图上,加了FSAF模块的RetinaNet网络可以检测到细长的目标,并且FSAF能提升检测效果,单独的FSAF检测对比如下表

总结
这篇文章提出了FSAF的特征选择无anchor模块,应用于多尺度特征输出网络。在训练和推理阶段,同时使用anchor-based和anchor-free两个分支。FSAF模块其实一个卷积层,在训练中,这个模块学会选择合适的尺度,在推理阶段,可自动输出合理的结果。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









