




 本文解读了CVPR2019论文,探讨了针对目标检测中Anchor的问题,提出Feature Selective Anchor-Free (FSAF) 模块。FSAF通过在线特征选择和联合优化避免了传统Anchor的不足,提升了检测效果,特别是在处理小目标时表现优越。
本文解读了CVPR2019论文,探讨了针对目标检测中Anchor的问题,提出Feature Selective Anchor-Free (FSAF) 模块。FSAF通过在线特征选择和联合优化避免了传统Anchor的不足,提升了检测效果,特别是在处理小目标时表现优越。
文章目录
最近部分cvpr2019的论文出来了,为了能对目标检测方向的前沿算法有更多理解,笔者趁着周末,仔细阅读了CMU的这篇文章。之所以选择这一篇,一是因为标题中有"Anchor-Free",立即引起了笔者的兴趣,毕竟大部分的目标检测算法还是基于Anchor的,二是论文的第二作者是Yihui He,他在模型剪枝方向做的非常不错,大家感兴趣可以参见“AMC: AutoML for Model Compression and Acceleration on Mobile Devices”这篇文章,好吧,说的有点远了,现在直奔具体的文章内容吧?。
1 背景知识
目标检测任务包含了两个子任务,分类和定位。通常的one-stage算法是直接进行多分类,比如背景、前景1和前景2的三分类任务,这中思路会带来“样本极不均衡”问题,毕竟大部分的box都是背景类别。two-stage的算法采用了另外一种思路,它在第一阶段做二分类任务,将“样本极不均衡”问题转换成了“样本较不均衡”问题,第二阶段的前景多分类由于样本均衡,所以任务就变得很简单了,存在的缺点就是算法太耗时。
为了解决one-stage算法面临的“样本极不均衡”问题,在Retinanet论文中,作者提出了focal loss,从损失函数的角度解决该问题。具体来说,作者基于先验知识,proposal的预测置信度越高,说明该proposal对应的gnd box属于简单样本,那么在每一次参数更新的时候,让网络尽量从hard gnd box中学习,从而可以过滤掉背景中的很多简单box,缓解了样本不均衡问题。
2 动机
对于目标检测任务,待检测目标通常存在“尺度差异性”,为了解决这个问题,可以有2种思路,图像金字塔和特征金字塔。基于anchor的检测算法正是采用了特征金字塔的思想,即使用anchor boxes将所有的目标离散化成不同尺寸、长宽比的有限个boxes。在做离散化的过程中, 基于经验知识,浅层的特征对应小尺度的目标,深层的特征对应大尺度的目标,因此将小的anchor boxes对应到浅层特征,大的anchor对应到深层特征,ground truth boxes基于IoU匹配到不同的anchor boxes,如下图所示,显然,这是一种“分而治之”的思想。
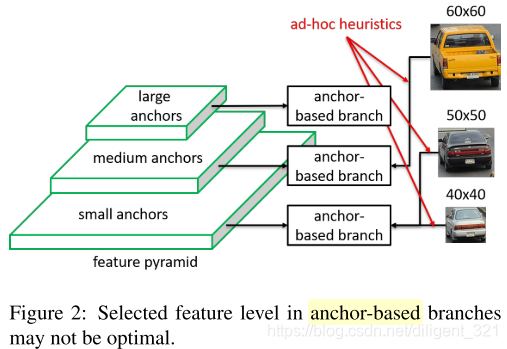
上面这种做法的缺点是,基于人工经验规则,将anchor boxes离散化到不同的特征层,显然这本身就是sub-optimal的,因此将ground truth box匹配到最接近的anchor boxes,也就不是最优的做法了。换句话说,可能anchor box被分配到第n层才是最好的,结果被人工分配到了第n+1个特征层,那么让ground truth boxes去做回归就有点不合适了。
这里引用ssd原论文中的一段话,
“Feature maps from different levels within a network are known to have different (empirical) receptive field sizes [13]. Fortunately, within the SSD framework, the default boxes do not necessary need to correspond to the actual receptive fields of each layer. We design the tiling of default boxes so that specific feature maps learn to be responsive to particular scales of the objects. In practice, one can also design a distribution of default boxes to best fit a specific dataset. How to design the optimal tiling is an open question as well.”
显然,ssd作者已经提到Wei Liu早早就提到了,如何将anchor boxes按照最优的方式分配到不同层,需要进一步研究。坑都挖好了,有的学者沿着优化anchors尺寸的思路填坑,比如“Anchor Box Optimization for Object Detection”。而本文换了一种思路,既然anchor boxes的尺寸设计和分配方式都不是最优的,那么可不可以不使用anchor呢,想法确实很新颖。
3 Feature Selective Anchor-Free Module
为了使得每一个ground truth box匹配到最佳的特征层,作者提出了feature select anchor-free module,简称为FSAF,那么大家可能会想,为什么不使用anchor 了呢?因为在anchor分配到不同特征层的过程是启发式的做法,如果这样做就不是最优的了,所以只能不适用anchor,从而避开anchor分配带来的问题,FSAF模块的图形化表示如下,
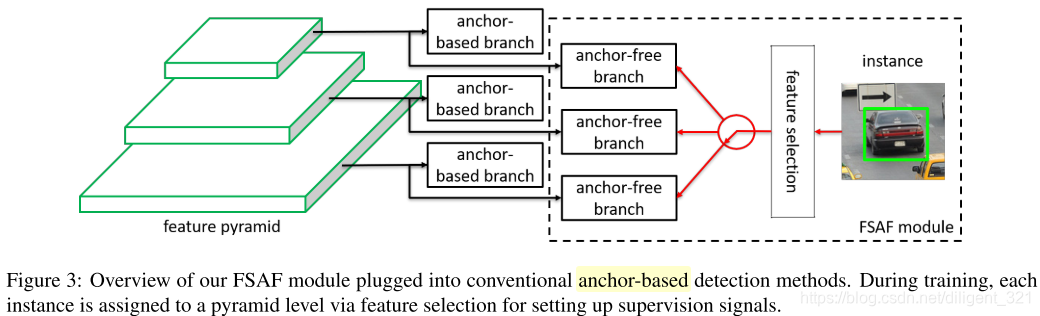
显然,该模块适用于特征金字塔型的网络结构,且和anchor-based 分支相互独立,从后面的实验结果中也可以看出,组合这两者能显著提升检测模型的效果。
那么问题来了,(1)怎么设计anchor-free分支的网络结构呢?(2)在优化anchor-free分支时,监督信号是什么呢?(3)怎么把目标分配到不同的特征层呢?(4)怎么联合优化anchor-free分支和anchor-based分支呢?作者分别给出了回答。
3.1 网络结构
FSAF模块与Retinanet组合的网络结构如下图,显然,anchor-free分支引入的计算量很小。
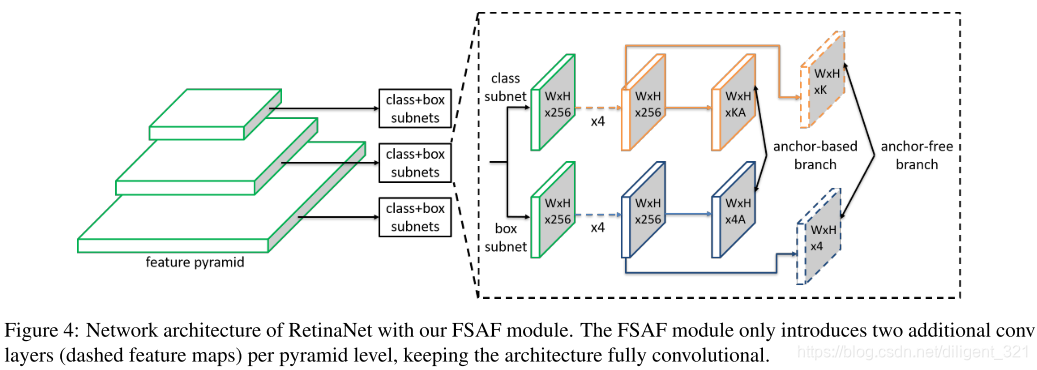
3.2 anchor-free分支的监督信号
定义监督信号,也就是要定义好groundtruth box和loss函数在介绍这一部分之前,需要先定义几个概念,
(1)ground truth box的类别: k k k;
(2)ground truth box的坐标: b = [ x , y , w , h ] b=[x, y, w, h] b=[x,y,w,h],其中, ( x , y ) (x, y) (x,y)表示box的center坐标;
(3)ground truth box在第 l l l个特征层上的投影: b p l = [ x p l , y p l , w p l , h p l ] b^{l}_{p} = [x^{l}_{p}, y^{l}_{p}, w^{l}_{p}, h^{l}_{p}] bpl=[x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









