






 论文提出FeatureSelectiveAnchor-Free(FSAF)模块,改进单次目标检测,通过在线学习选择不同大小实例的最佳特征层,提升RetinaNet等模型在COCO数据集上的表现,尤其改善小、窄物体的检测效果。
论文提出FeatureSelectiveAnchor-Free(FSAF)模块,改进单次目标检测,通过在线学习选择不同大小实例的最佳特征层,提升RetinaNet等模型在COCO数据集上的表现,尤其改善小、窄物体的检测效果。
论文《Feature Selective Anchor-Free Module for Single-Shot Object Detection》(CVPR2019)
论文的主要贡献在特征金字塔的基础上,提出Feature Selective Achor-Free Model ,通过学习的方式,对不同大小的实例,选择不同level的特征,来解决启发式特征选择的弊端。
本文主要记录论文的实验设计
1.数据集
论文的实验都是在coco数据集上进行的。
2.Ablation Studies(消融实验)
数据:training and test 图像都是 800pixels
1.评估Anchor-Free branches
整体思路是Anchor-based VS Anchor-free(又包括启发式特征选择vs在线特征选择)。最终比较结果是Mix好,也就是Anchor-based+Anchor-Free(在线特征选择)。
又通过图片结果,直观的展示了提出的FSAF比RetinaNet(Anchor-based)能更好的检测难检测的物体(如小,窄物体)。
2.评估在线特征选择
比较Anchor-Free的两种特征选择策略:启发式VS在线学习式,(Anchor-based+启发式)VS(Anchor-based+在线式)
结果是在线特征选择对于anchor-based+anchor-free有益
然后论文可视化地比较了Anchor-based提取的特征level和Anchor-Free提取的特征level
3.FSAF适用于现有的网络框架
在ResNet50,ResNet-101,ResNeXt-101上比较RetinaNet(Anchor-based)、FSAF、Anchor-based+FSAF
3.Comparison to State of the art(与现有方法比较)
比较工作分别在单尺度和多尺度两个方面进行。与现有的single-shot和multi-shot比较
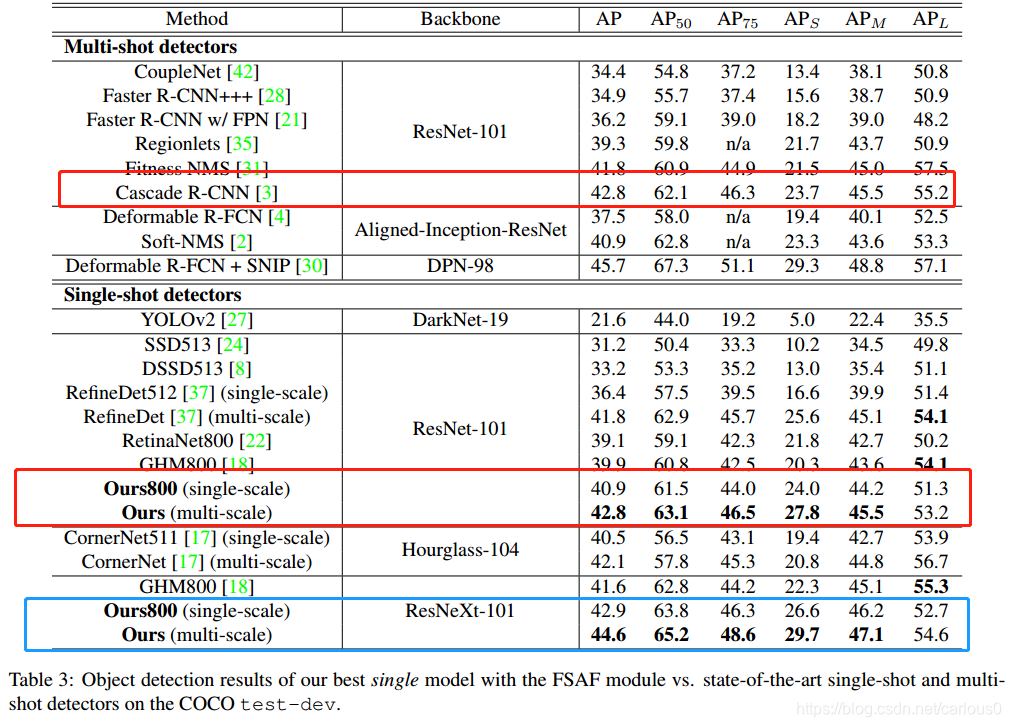
可以看出,在同样以resNet-101为backbone network时,论文在多尺度上的结果已经超过了Multi-shot。
最后呢,在ResNeXt-101上也超过了目前最好的GHM800

















 788
788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









