






感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、项目介绍
随着电商技术的广泛应用,网上购书已经变得极为方便。但是,随着网上书籍的种类和数量的不断增加,购书者如何快速方便地找到所需的书籍,成为了网上书店系统必须面对的问题,尤其是在个性化服务、搜索速度和定向推送等方面。因此,本论文研究了协同过滤推荐等相关技术,并使用了PyCharm作为开发工具,MySQL作为数据库,Django作为Web服务器,Vue.js作为前端开发框架。本系统采用了B/S结构,用户可以直接在网页上使用,非常方便简洁可靠。经过系统测试,毕业设计完成的网上书店系统能够根据客户的需求,较好地实现书籍的推荐功能,从而节省购书者的搜索时间。
[关键词] 图书推荐;协同过滤算法;Django框架; Vue框架
本文是基于协同过滤算法的图书推荐系统设计,通过对这个系统研究,我发现传统的网上书店系统具有一些缺点使用起来并没有那么智能。通过引入推荐算法可以提高用户体验、促进用户购买决策、优化产品布局、实现自动化运营、提高市场竞争力等。
对于本系统的实现,我首先是从需求开始分析需要画整个系统的流程图还有系统的功能结构图,对于数据库表进行分析画出实体图,E-R关系图。
本系统使用的是B/S的结构对于这个结构我们考虑到用户以及管理员的操作是移动的,我认为使用浏览器比起安装程序更加适合这个系统。使用的是MySQL数据库,这个数据库历史悠久,网上的一些问题解决和教程都比较多比较全。但是对于这个系统来说也有很多地方不够完善。比如对于这个支付的模块,因为个人的能力有限,这个功能还没有实现完全。
2、项目界面
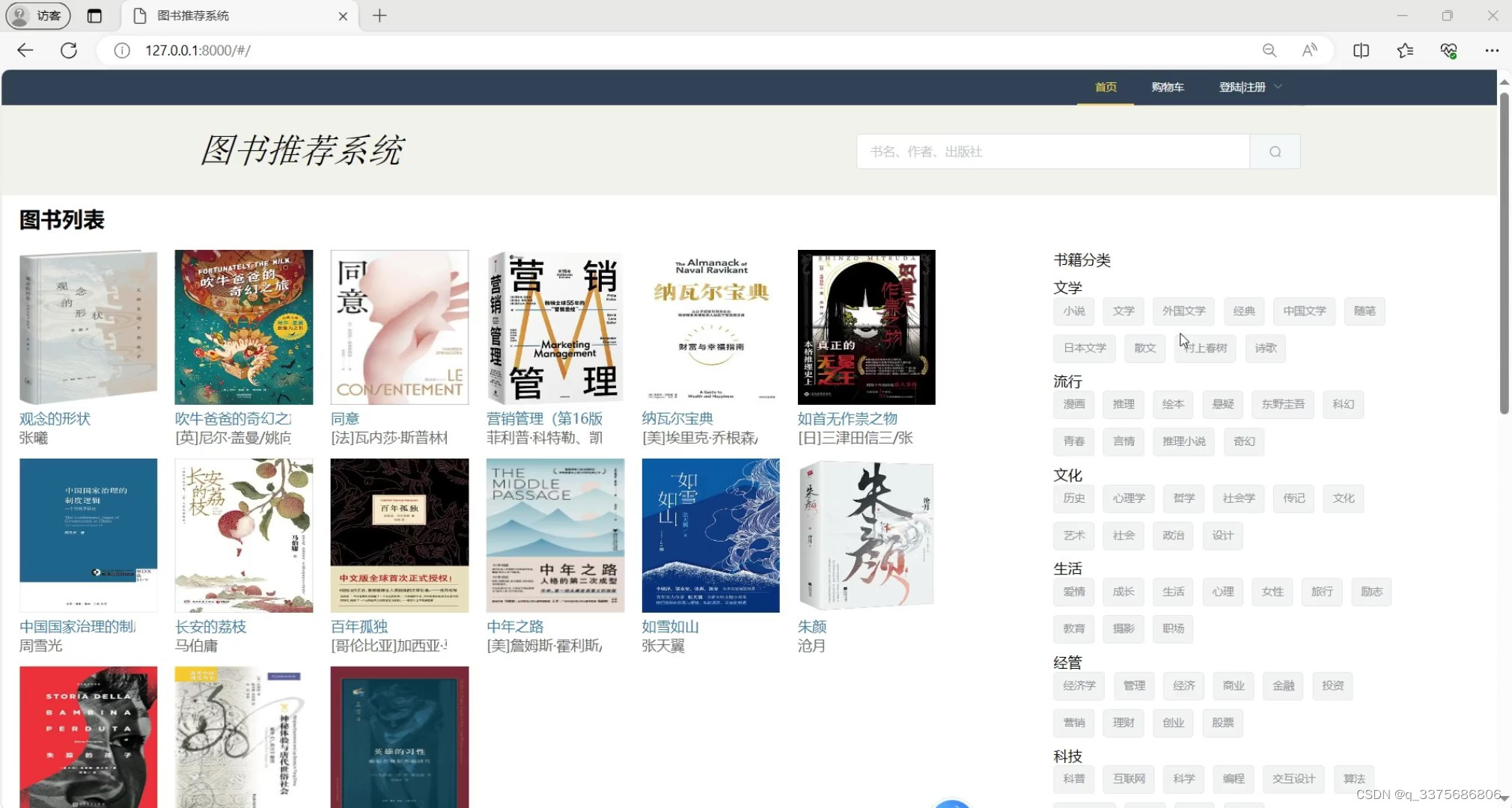
首页
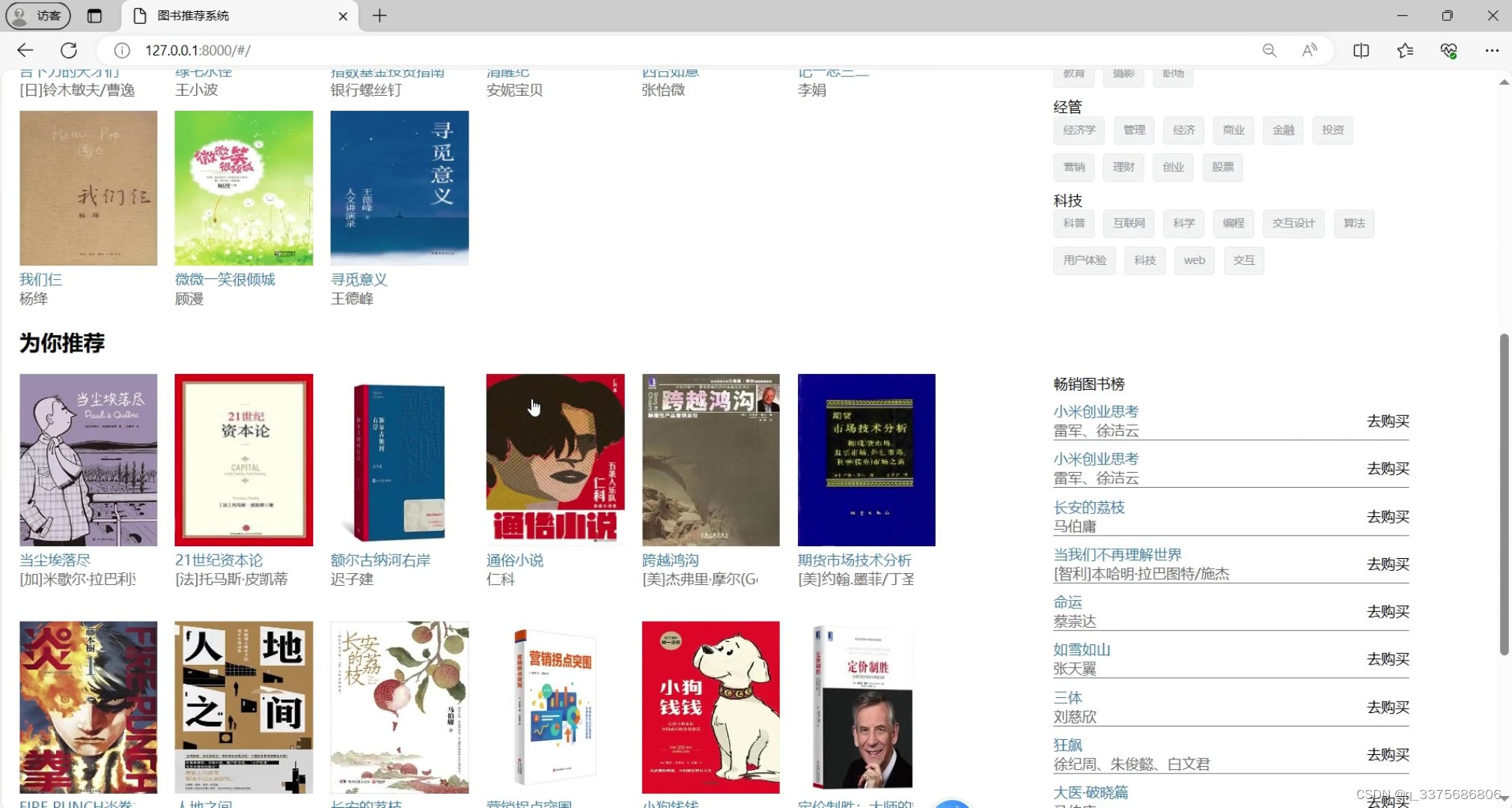
(2)个性化图书推荐-----基于用户协同过滤推荐算法
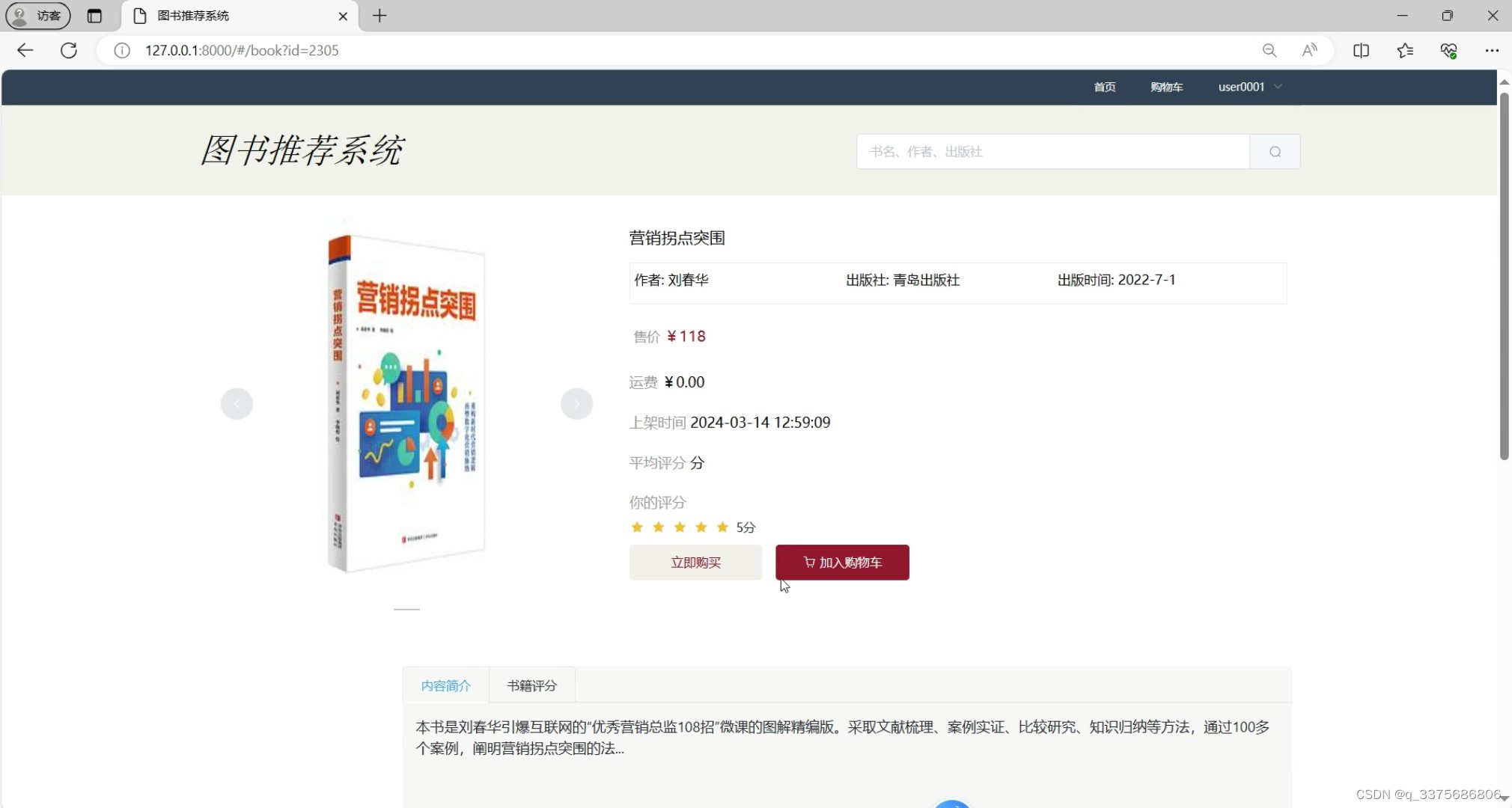
(3)图书详情页面
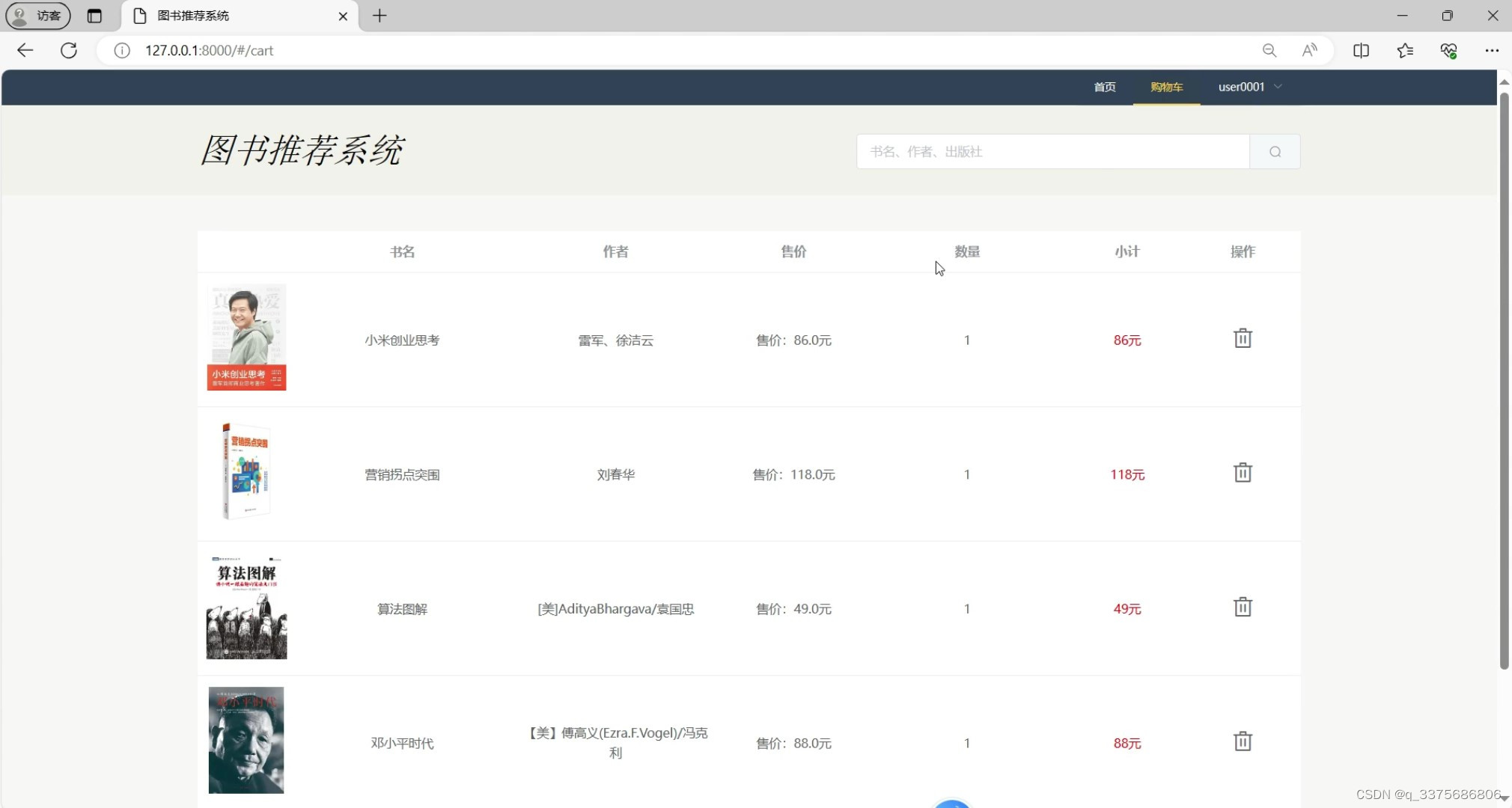
(4)购物车模块
(5)支付购买模块
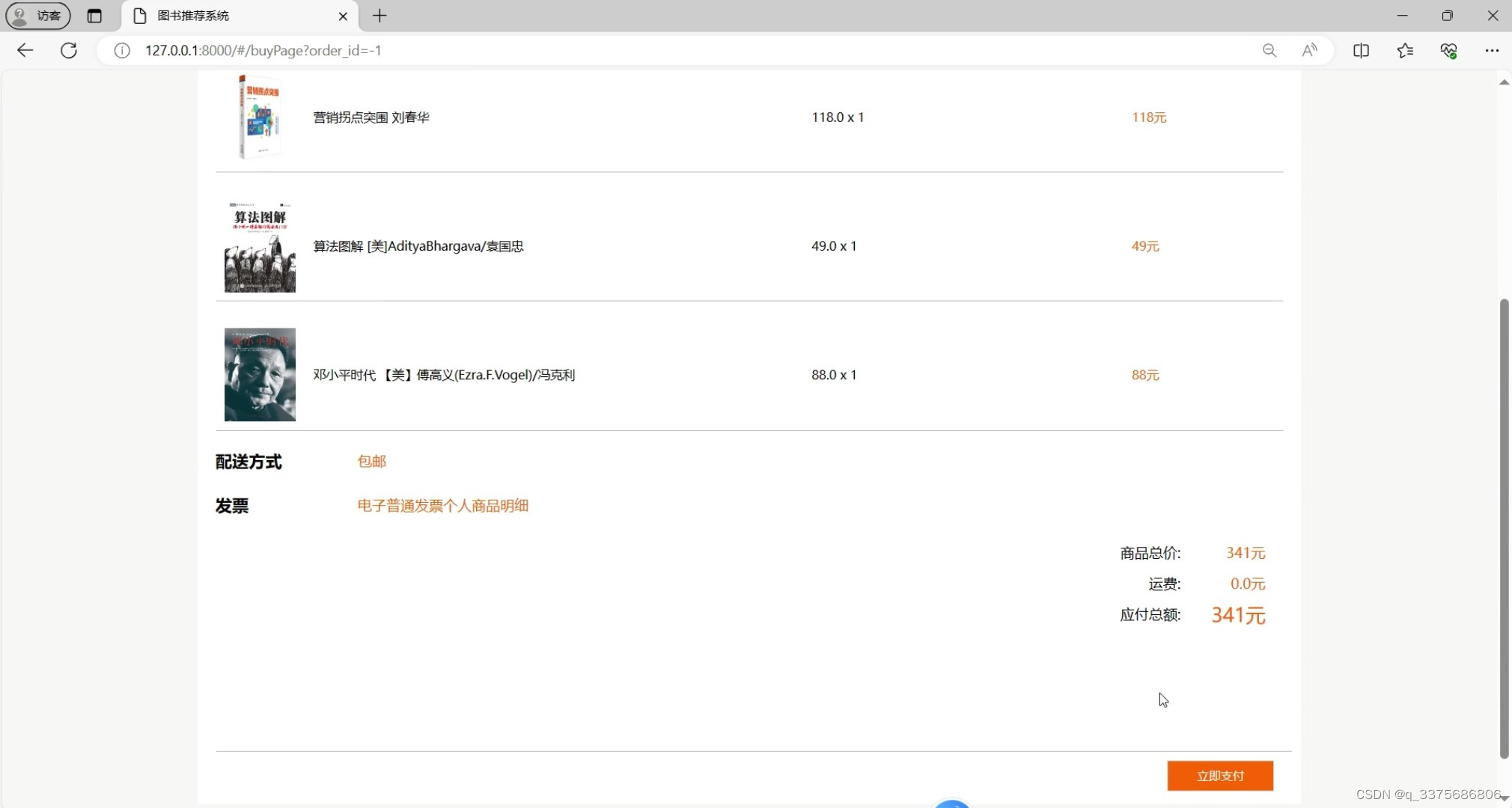
(6)我的订单模块
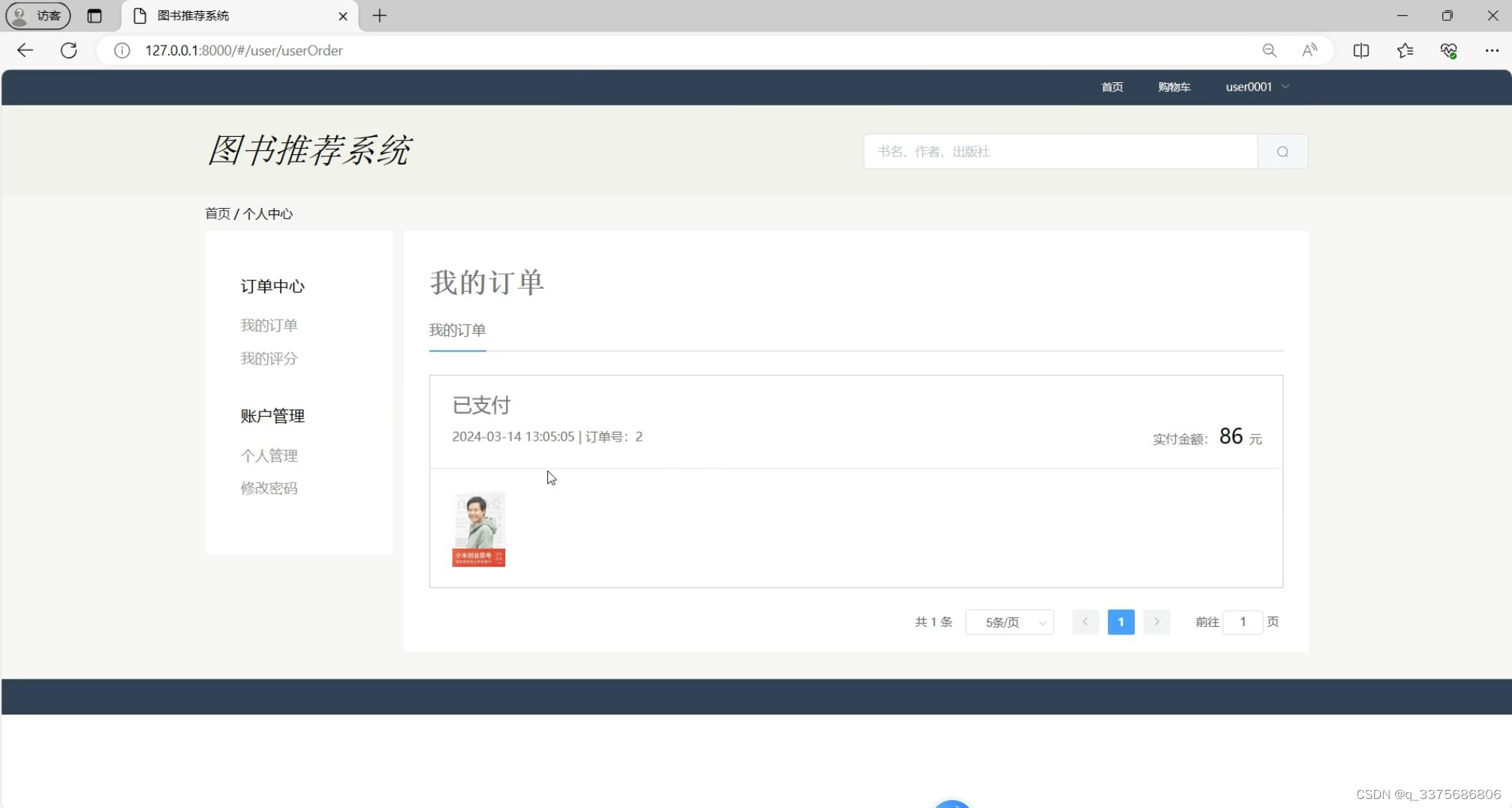
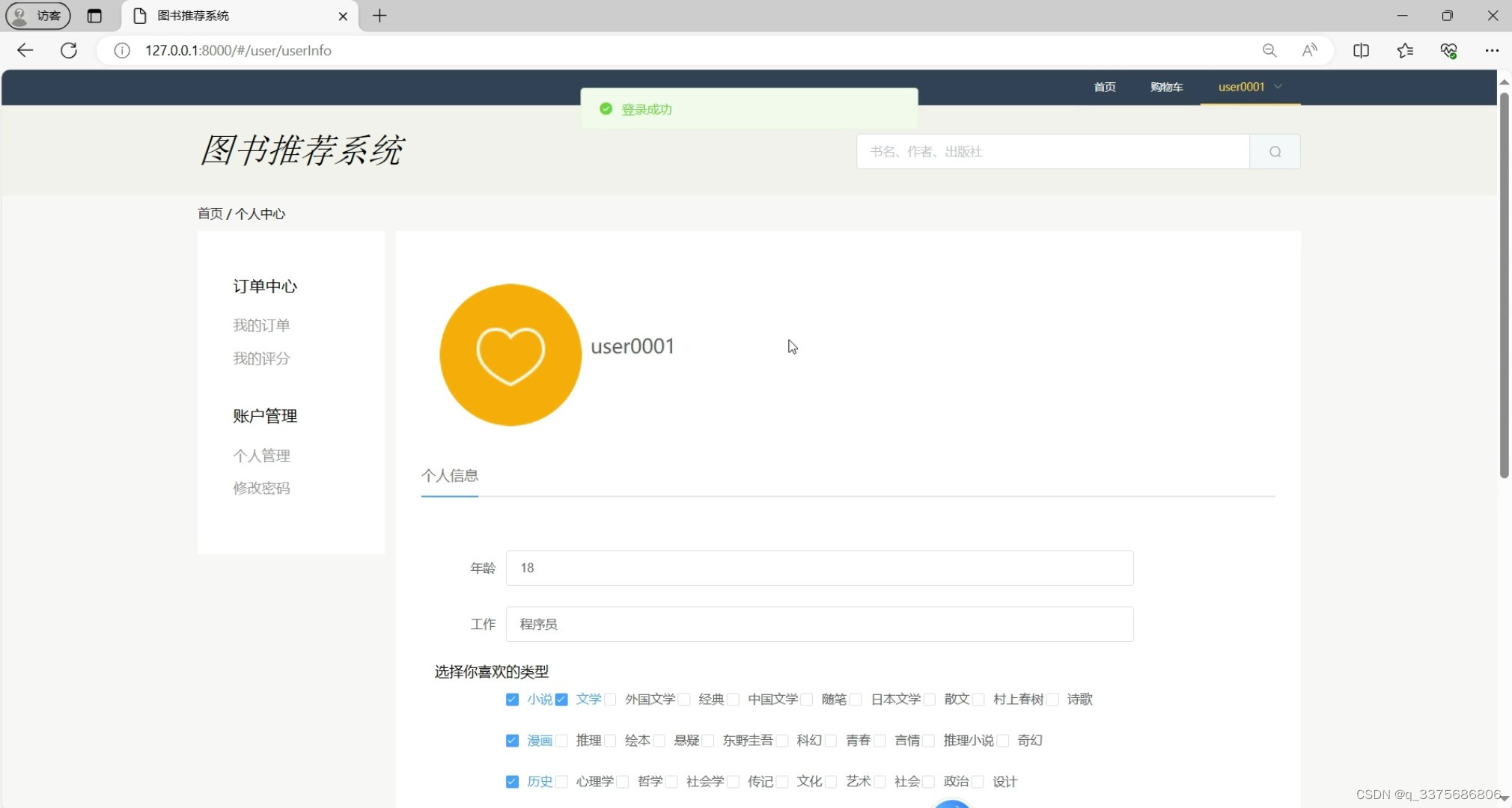
(7)个人中心
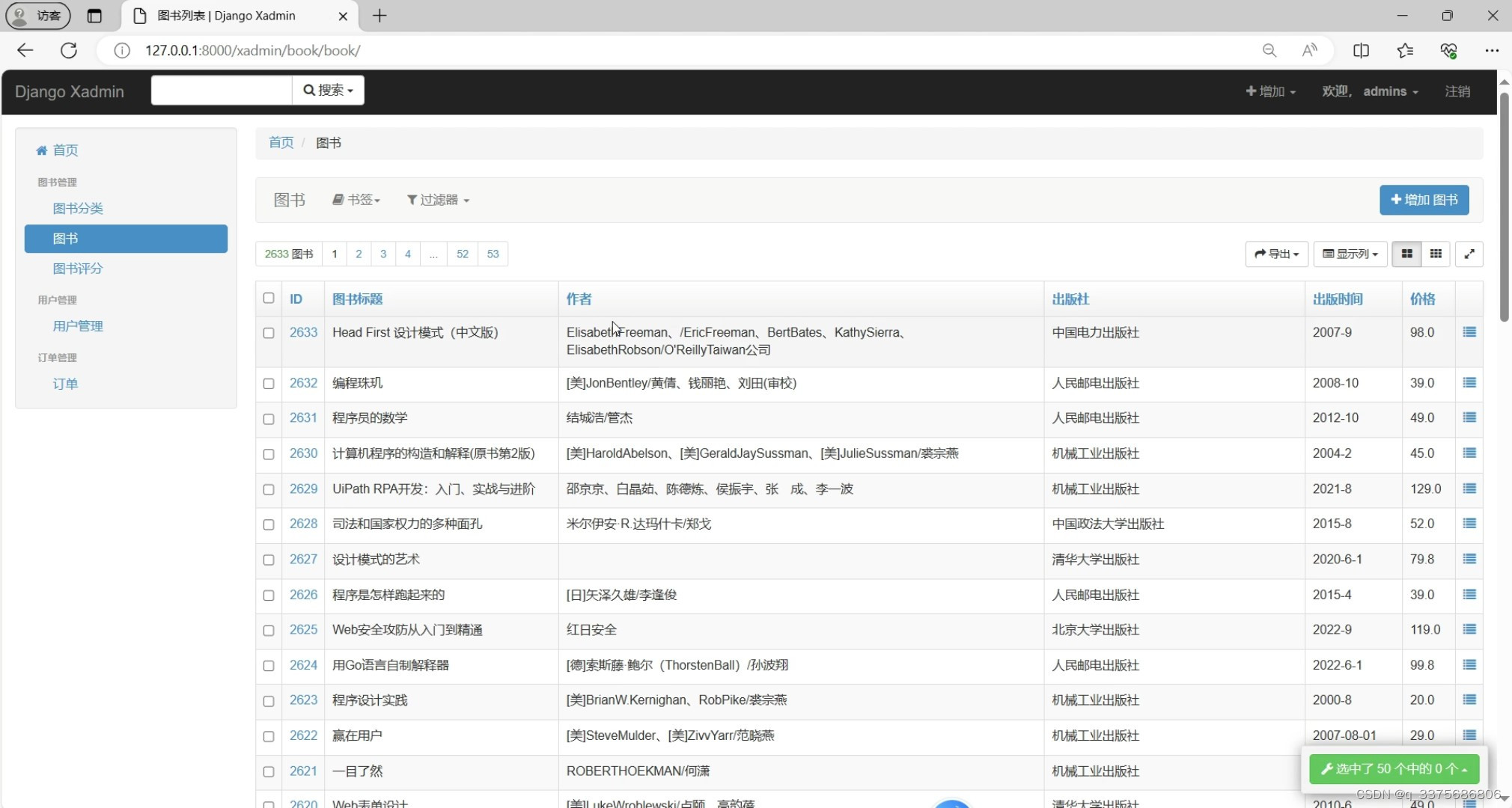
(8)后台图书信息管理
(9)注册登录模块
3、项目说明
本文是基于协同过滤算法的图书推荐系统设计,通过对这个系统研究,我发现传统的网上书店系统具有一些缺点使用起来并没有那么智能。通过引入推荐算法可以提高用户体验、促进用户购买决策、优化产品布局、实现自动化运营、提高市场竞争力等。
对于本系统的实现,我首先是从需求开始分析需要画整个系统的流程图还有系统的功能结构图,对于数据库表进行分析画出实体图,E-R关系图。
本系统使用的是B/S的结构对于这个结构我们考虑到用户以及管理员的操作是移动的,我认为使用浏览器比起安装程序更加适合这个系统。使用的是MySQL数据库,这个数据库历史悠久,网上的一些问题解决和教程都比较多比较全。但是对于这个系统来说也有很多地方不够完善。比如对于这个支付的模块,因为个人的能力有限,这个功能还没有实现完全。
本文对本系统中使用到的一些技术栈做出了详细的说明,并且对于整个开发过程也有详细的说明。对整体系统做出来一个比较全面的测试,在浏览器中可以通畅的运行,达到了基本预期的效果。
该系统是一个集成了多种现代技术栈的在线图书销售与推荐平台。以下是对该系统的详细介绍:
系统采用Python语言作为主要开发语言,结合Django框架,为后端提供了强大的功能和良好的可扩展性。Django以其高效的开发效率和安全性,确保了系统后端代码的健壮性和稳定性。同时,Vue框架作为前端技术栈的选择,以其组件化的开发方式和流畅的用户界面体验,为用户提供了直观、易用的交互界面。
系统的主要功能模块包括:
首页:展示图书分类、热门图书、促销活动等信息,吸引用户浏览和购买。
个性化图书推荐:基于用户协同过滤推荐算法,根据用户的购买历史和浏览行为,为用户提供个性化的图书推荐,提升用户购物体验和满意度。
图书详情页面:展示图书的详细信息,包括书名、作者、出版社、价格、评分、评论等,帮助用户全面了解图书。
购物车模块:用户可以将心仪的图书加入购物车,随时查看和修改购物车内的图书,方便用户批量购买。
支付购买模块:支持多种支付方式,确保用户支付安全便捷,同时提供订单跟踪功能,让用户随时了解订单状态。
我的订单模块:用户可以查看自己的历史订单,包括订单详情、物流信息等,方便用户管理自己的订单。
个人中心:用户可以修改个人信息、查看积分和优惠券等,提供个性化服务。
后台图书信息管理:管理员可以方便地管理图书信息,包括添加、修改、删除图书等,确保图书信息的准确性和时效性。
注册登录模块:用户可以通过注册登录功能,享受更多的个性化服务,如查看个人订单、修改个人信息等。
该系统不仅为用户提供了便捷的在线购书体验,还通过个性化推荐算法,提高了用户满意度和忠诚度。同时,后台管理功能的完善也确保了图书信息的准确性和系统的稳定性。
4、核心代码
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

















 1234
1234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









