 LlamaIndex入门教程:从数据到查询的全面指南
LlamaIndex入门教程:从数据到查询的全面指南








 LlamaIndex是一个用于LLM应用的数据框架,提供数据连接、结构化数据处理和高级查询接口。它允许用户通过高层API轻松操作数据,也支持自定义扩展。本文档介绍了LlamaIndex的安装、数据加载、节点解析、索引构建、查询接口和架构概述,适合初学者和高级用户使用。
LlamaIndex是一个用于LLM应用的数据框架,提供数据连接、结构化数据处理和高级查询接口。它允许用户通过高层API轻松操作数据,也支持自定义扩展。本文档介绍了LlamaIndex的安装、数据加载、节点解析、索引构建、查询接口和架构概述,适合初学者和高级用户使用。
LlamaIndex
1、概述
LlamaIndex(GPT索引)是LLM应用程序的数据框架。
LlamaIndex所提供的的工具:
- 提供data connectors以引入现有数据源和数据格式(API、PDF、文档、SQL 等)
- 提供结构化数据(索引、图形)的方法,以便此数据可以轻松地与 LLM 一起使用。
- 为您的数据提供高级检索/查询界面:输入任何LLM输入提示,获取检索到的上下文和知识增强的输出。
- 允许与外部应用程序框架轻松集成(例如与LangChain,Flask,Docker,ChatGPT等任何内容)。
LlamaIndex能做到的事:
- 高层 API 允许初学者用户使用 LlamaIndex 在 5 行代码中摄取和查询他们的数据。
- 较底层 API 允许高级用户自定义和扩展任何模块(数据连接器、索引、检索器、查询引擎、重新排名模块),以满足他们的需求。
2、安装与环境配置
2.1 使用pip安装
pip install llama-index
2.2 环境配置
略
3、入门
LlamaIndex的核心是一个工具包,旨在轻松连接LLM与您的外部数据。以下指南旨在帮助您充分利用LlamaIndex。
它提供以下内容的高级概述:
- LlamaIndex的一般使用模式(从数据摄取到数据结构,再到查询接口)
- 每个指数的工作原理
- 查询接口
- LlamaIndex架构概述(截至0.6.0版本)
通用指南:
- LlamaIndex 使用模式
- 每个指数的工作原理
- 查询接口
- 架构概述
3.1 LlamaIndex 使用模式
LlamaIndex 的一般使用模式如下:
- 加载文档(手动或通过数据加载器)
- 将文档解析为节点
- 构建索引(从节点或文档中)
- 在其他索引之上构建索引【可选,高级】
- 查询索引
3.1.1 加载文档
第一步是加载数据。这些数据以 Document 对象的形式表示。我们提供了各种数据加载器,可以通过 load_data 函数加载文档,例如:
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader('./data').load_data()
也可以选择手动构建文档。LlamaIndex公开了 Document 结构体。
from llama_index import Document
text_list = [text1, text2, ...]
documents = [Document(t) for t in text_list]
一个文档代表着数据源的轻量级容器。
3.1.2 将文档解析为节点
下一步是将这些文档对象解析为节点对象。节点代表源文档的“chunks”(块),无论是文本块、图像还是其他内容。它们还包含与其他节点和索引结构的元数据和关系信息。
节点是LlamaIndex中的一等公民。您可以选择直接定义节点及其所有属性。您也可以通过我们的 NodeParser 类将源文档“解析”为节点。
from llama_index.node_parser import SimpleNodeParser
parser = SimpleNodeParser()
nodes = parser.get_nodes_from_documents(documents)
也可以选择跳过第一部分来手动构建节点对象。
from llama_index.data_structs.node import Node, DocumentRelationship
node1 = Node(text="<text_chunk>", doc_id="<node_id>")
node2 = Node(text="<text_chunk>", doc_id="<node_id>")
# set relationships
node1.relationships[DocumentRelationship.NEXT] = node2.get_doc_id()
node2.relationships[DocumentRelationship.PREVIOUS] = node1.get_doc_id()
nodes = [node1, node2]
3.1.3 构建索引
现在我们可以在这些文档对象上建立索引。最简单的高级抽象是在索引初始化期间加载文档对象(如果您直接从步骤1跳过步骤2,则这很重要)。
from llama_index import VectorStoreIndex
index = VectorStoreIndex.from_documents(documents)
还可以选择直接在一组节点对象上构建索引。
from llama_index import VectorStoreIndex
index = VectorStoreIndex(nodes)
根据您使用的索引,LlamaIndex 可能会进行 LLM 调用以构建索引。
跨索引重用节点
如果您定义了多个Node对象,并希望在多个索引结构之间共享这些Node对象,只需实例化一个StorageContext对象,将Node对象添加到底层的DocumentStore中,并传递StorageContext即可。
from llama_index import StorageContext
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)
index1 = VectorStoreIndex(nodes, storage_context=storage_context)
index2 = ListIndex(nodes, storage_context=storage_context)
注意:如果未指定
storage_context参数,则在索引构建期间将隐式为每个索引创建它。您可以通过index.storage_context访问与给定索引关联的文档存储。
插入文档或节点
还可以利用索引的 insert 功能,逐个插入文档对象,而不是在索引构建期间插入。
from llama_index import VectorStoreIndex
index = VectorStoreIndex([])
for doc in documents:
index.insert(doc)
如果您想要直接插入节点,可以使用 insert_nodes 函数。
from llama_index import VectorStoreIndex
# nodes: Sequence[Node]
index = VectorStoreIndex([])
index.insert_nodes(nodes)
自定义文档
在创建文档时,您还可以附加有用的元数据。添加到文档中的任何元数据都将复制到从其相应源文档创建的节点。
document = Document(
'text',
extra_info={
'filename': '<doc_file_name>',
'category': '<category>'
}
)
自定义LLM
默认情况下,我们使用OpenAI的 text-davinci-003 模型。您可以选择在构建索引时使用另一个LLM。
from llama_index import LLMPredictor, VectorStoreIndex, ServiceContext
from langchain import OpenAI
...
# define LLM
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="text-davinci-003"))
# configure service context
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
# build index
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
全局ServiceContext
如果您希望上一节的service context始终是默认值,可以按以下方式进行配置:
from llama_index import set_global_service_context
set_global_service_context(service_context)
如果在LlamaIndex函数中没有指定关键字参数,那么这个服务上下文将始终被用作默认值
自定义Prompts
根据所使用的索引,我们使用默认提示词模板来构建索引(以及插入/查询)。
个性化嵌入
对于基于嵌入的索引,您可以选择传入自定义嵌入模型。
成本预测器
创建索引、插入索引和查询索引可能会使用令牌。我们可以通过这些操作的输出跟踪令牌使用情况。运行操作时,令牌使用情况将被打印。
您还可以通过 index.llm_predictor.last_token_usage 获取令牌使用情况。
保存索引以备将来使用【可选】
默认情况下,数据存储在内存中。要持久化到磁盘:
index.storage_context.persist(persist_dir="<persist_dir>")
您可以省略 persist_dir 参数,默认将数据持久化到 ./storage 。
重新从磁盘加载:
from llama_index import StorageContext, load_index_from_storage
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="<persist_dir>")
# load index
index = load_index_from_storage(storage_context)
注意:如果您使用自定义
ServiceContext对象初始化了索引,则在load_index_from_storage期间还需要传递相同的ServiceContext。
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
# when first building the index
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
...
# when loading the index from disk
index = load_index_from_storage(
service_context=service_context,
)
3.1.4 在其他索引之上构建索引【可选,高级】
你可以在其他索引之上构建索引!可组合性为您在索引异构数据源方面提供更大的能力。
3.1.5 查询索引
构建索引后,您现在可以使用 QueryEngine 查询它。
注意,“查询”只是LLM的输入 - 这意味着您可以使用索引进行问答,但您也可以做更多的事情!
高层API
首先,您可以使用默认配置查询索引 QueryEngine ,方法如下:
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
response = query_engine.query("Write an email to the user given their background information.")
print(response)
低层API
我们还支持低级别的组合 API,可以更精细地控制查询逻辑。以下我们重点介绍一些可能的自定义选项。
from llama_index import (
VectorStoreIndex,
ResponseSynthesizer,
)
from llama_index.retrievers import VectorIndexRetriever
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.indices.postprocessor import SimilarityPostprocessor
# build index
index = VectorStoreIndex.from_documents(documents)
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=2,
)
# configure response synthesizer
response_synthesizer = ResponseSynthesizer.from_args(
node_postprocessors=[
SimilarityPostprocessor(similarity_cutoff=0.7)
]
)
# assemble query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)
# query
response = query_engine.query("What did the author do growing up?")
print(response)
您还可以通过实现相应的接口,添加自己的检索(retrieval)、响应合成(response synthesis)和整体查询逻辑(overall query logic)。
配置检索器
索引可以有多种特定于索引的检索模式。例如,列表索引支持默认的 ListIndexRetriever ,它检索所有节点,以及 ListIndexEmbeddingRetriever ,它通过嵌入相似性检索前k个节点。
为了方便起见,您也可以使用以下简写:
# ListIndexRetriever
retriever = index.as_retriever(retriever_mode='default')
# ListIndexEmbeddingRetriever
retriever = index.as_retriever(retriever_mode='embedding')
选择您想要的检索器后,您可以构建您的查询引擎:
query_engine = RetrieverQueryEngine(retriever)
response = query_engine.query("What did the author do growing up?")
配置响应合成
当一个检索器(retriever )获取到相关节点后, ResponseSynthesizer 通过组合信息来综合最终响应。
您可以通过配置来进行设置:
query_engine = RetrieverQueryEngine.from_args(retriever, response_mode=<response_mode>)
目前,我们支持以下选项:
default:“创建和完善”回答,通过逐个检索每个Node来实现;这将为每个节点进行单独的LLM调用。适用于更详细的答案。compact:在每次LLM调用期间,通过尽可能多地填充Node文本块来“压缩”提示。如果有太多的块无法放入一个提示中,则通过多个提示“创建和完善”回答。tree_summarize:给定一组Node个对象和查询,递归构建一棵树并返回根节点作为响应。适用于汇总目的。no_text:仅运行检索器以获取本应发送到LLM的节点,而不实际发送它们。然后可以通过检查response.source_nodes进行检查。accumulate:给定一组Node个对象和查询条件,将查询应用于每个Node文本块,同时将响应累积到数组中。返回所有响应的连接字符串。适用于需要单独针对每个文本块运行相同查询的情况。
index = ListIndex.from_documents(documents)
retriever = index.as_retriever()
# default
query_engine = RetrieverQueryEngine.from_args(retriever, response_mode='default')
response = query_engine.query("What did the author do growing up?")
# compact
query_engine = RetrieverQueryEngine.from_args(retriever, response_mode='compact')
response = query_engine.query("What did the author do growing up?")
# tree summarize
query_engine = RetrieverQueryEngine.from_args(retriever, response_mode='tree_summarize')
response = query_engine.query("What did the author do growing up?")
# no text
query_engine = RetrieverQueryEngine.from_args(retriever, response_mode='no_text')
response = query_engine.query("What did the author do growing up?")
配置节点后置处理器(即过滤和增强)
我们还支持高级 Node 过滤和增强功能,可以进一步提高检索到的 Node 对象的相关性。这可以帮助减少LLM调用的时间/数量/成本或提高响应质量。
例如:
KeywordNodePostprocessor:按required_keywords和exclude_keywords筛选节点。SimilarityPostprocessor:通过在相似度得分上设置阈值来过滤节点(因此仅由基于嵌入的检索器支持)PrevNextNodePostprocessor:根据Node关系,为检索到的Node个对象提供额外的相关上下文信息。
配置所需的节点后处理器:
node_postprocessors = [
KeywordNodePostprocessor(
required_keywords=["Combinator"],
exclude_keywords=["Italy"]
)
]
query_engine = RetrieverQueryEngine.from_args(
retriever, node_postprocessors=node_postprocessors
)
response = query_engine.query("What did the author do growing up?")
3.1.6 解析响应
返回的对象是一个 Response 对象。该对象包含响应文本以及响应的“sources”。
response = query_engine.query("<query_str>")
# get response
# response.response
str(response)
# get sources
response.source_nodes
# formatted sources
response.get_formatted_sources()
3.2 每个索引的工作原理
terminology术语:
- Node:对应于文档中的一块文本。LlamaIndex接受文档对象并在内部将其解析/分块为节点对象。
- Response Synthesis:我们的模块可以根据检索到的节点合成响应。合成响应有不同的响应模式
3.2.1 列表索引
列表索引仅将节点存储为顺序链。

在查询时,如果没有指定其他查询参数,LlamaIndex 将简单地将列表中的所有节点加载到我们的响应合成模块中。

列表索引提供了许多查询列表索引的方式,可以通过基于嵌入的查询来获取前k个邻居,也可以通过添加关键字过滤器来查询,如下所示:

3.2.2 向量存储索引
向量存储索引将每个节点及其对应的嵌入存储在向量存储器中。

查询向量存储索引涉及获取前k个最相似的节点,并将它们传递到我们的响应合成模块中。

3.2.3 树索引
树索引从一组节点(这些节点成为树中的叶节点)构建一个分层树。

查询树索引需要从根节点遍历到叶节点。默认情况下,( child_branch_factor=1 ),查询在给定父节点的情况下选择一个子节点。如果 child_branch_factor=2 ,则查询每层选择两个子节点。

3.2.4 关键词表索引
关键词表索引从每个节点中提取关键词,并建立从每个关键词到该关键词对应节点的映射。

在查询时,我们从查询中提取相关关键词,并将其与预先提取的节点关键词进行匹配,以获取相应的节点。提取的节点将传递给我们的响应合成模块。

3.3 查询接口
查询索引或图形涉及三个主要组件:
- Retrievers:检索器类根据查询从索引中检索一组节点。
- Response Synthesizer:该类接收一组节点并在给定查询的情况下合成答案。
- Query Engine:该类接收查询并返回响应对象。它可以在底层使用检索器和响应合成器模块。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EdGWlkX9-1687501746363)(IMAGES/query_classes.png)]
设计理念:逐步揭示复杂性
资源
3.4 架构概述
LlamaIndex的核心使命是为大型语言模型(LLM)和您的私人外部数据提供接口。在过去的几个月中,它已成为最受欢迎的开源框架之一,用于LLM数据增强(上下文增强生成),适用于各种用例:问答、摘要、结构化查询等。
LlamaIndex 0.6.0 在以下领域进行了一些基本的改变:
- 解耦状态与计算:我们将抽象层分离,以更清晰地将状态(数据+索引)与计算(检索器、查询引擎)解耦。
- 逐步披露复杂性:我们希望LlamaIndex能够满足初学者和高级用户的需求。我们引入了一个新的开发者友好的低级API,强调可组合性并使接口更清晰,以便更容易实现自定义构建块。
- 基于原则的存储抽象:我们重写了存储抽象,使其更加灵活(可存储数据和索引)和可扩展(超越内存存储的一般化)。
解耦状态与计算
我们已经围绕着三个关键抽象重新设计了LlamaIndex,这些抽象更清晰地将状态与计算分离。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FljesDcZ-1687501746364)(IMAGES/query_classes.png)]
- 在LlamaIndex的核心,
Index管理状态:抽象底层存储,并公开处理数据和相关元数据的视图。 - 然后,
Retriever根据查询从Index中获取最相关的节点。 - 最后,
QueryEngine综合查询和检索到的节点,生成一个响应。
使用LlamaIndex非常简单,只需要进行一些小的语法更改即可。它使用默认配置,非常适合初学者,您只需要几行代码就可以开始使用。
旧的语法
index.query("Who is Paul Graham?")
新语法
query_engine = index.as_query_engine()
query_engine.query("Who is Paul Graham?")
逐步披露复杂性
渐进式披露复杂性是一种设计哲学,旨在平衡初学者和专家的需求。其理念是,当用户第一次接触系统或产品时,应该给予他们最简单和最直接的界面或体验,然后随着用户对系统的熟悉程度逐渐揭示更多的复杂性和高级功能。这可以帮助防止用户感到被一个看似过于复杂的系统所压倒,同时仍然为有经验的用户提供完成高级任务所需的工具。
基于原则的存储抽象
由于LlamaIndex充当LLM和您的数据之间的接口,因此我们需要强大的抽象来管理现有数据(在存储系统内)以及我们定义的任何新数据(例如索引、其他元数据)。我们重写了存储抽象,以更灵活地摄取不同类型的数据,并更易于定制。
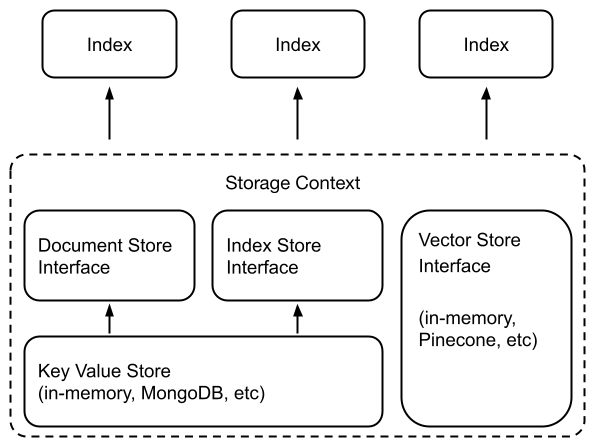
在基础层,我们需要存储抽象来存储任何数据。我们在这一层定义了一个新的键值存储 —— 一个围绕着任何支持键值存储的系统(内存、文件系统、MongoDB、对象存储等)的层。
从这里开始,我们定义文档存储和索引存储:
- Document stores:用于存储已摄取的文档(即节点对象)。
- Index stores:存储索引元数据的地方
向量存储如何适用
许多向量存储库都提供原始数据的存储功能(例如Pinecone、Weaviate、Chroma);它们都隐式地提供了一个“索引”——通过索引嵌入,它们通过相似性搜索公开了一个查询接口。
LlamaIndex提供了许多向量存储提供商的强大存储抽象。我们的向量存储抽象与我们的基本KV抽象、文档和索引存储抽象并行操作。
索引相当于数据的轻量级视图
这个变化所突出的一个基本原则是索引只是您数据的轻量级视图。这意味着在现有数据上定义新索引不会复制数据;新索引类似于在数据上定义元数据。
- 定义向量索引将使用嵌入对您的数据进行索引。
- 定义关键词索引将使用关键词对您的数据进行索引。
为现有数据定义元数据/索引是允许LLMs对数据执行不同检索/合成能力的关键因素。
型的数据,并更易于定制。
[外链图片转存中…(img-RuWAUtOs-1687501746364)]
在基础层,我们需要存储抽象来存储任何数据。我们在这一层定义了一个新的键值存储 —— 一个围绕着任何支持键值存储的系统(内存、文件系统、MongoDB、对象存储等)的层。
从这里开始,我们定义文档存储和索引存储:
- Document stores:用于存储已摄取的文档(即节点对象)。
- Index stores:存储索引元数据的地方
向量存储如何适用
许多向量存储库都提供原始数据的存储功能(例如Pinecone、Weaviate、Chroma);它们都隐式地提供了一个“索引”——通过索引嵌入,它们通过相似性搜索公开了一个查询接口。
LlamaIndex提供了许多向量存储提供商的强大存储抽象。我们的向量存储抽象与我们的基本KV抽象、文档和索引存储抽象并行操作。
索引相当于数据的轻量级视图
这个变化所突出的一个基本原则是索引只是您数据的轻量级视图。这意味着在现有数据上定义新索引不会复制数据;新索引类似于在数据上定义元数据。
- 定义向量索引将使用嵌入对您的数据进行索引。
- 定义关键词索引将使用关键词对您的数据进行索引。
为现有数据定义元数据/索引是允许LLMs对数据执行不同检索/合成能力的关键因素。

















 1415
1415




 到【灌水乐园】发言
到【灌水乐园】发言







