







一、本文介绍
🔥本文给大家介绍使用 SCPP(Scale-aware Contextual Pyramid Pooling)模块改进YOLOv13 网络,可显著增强其多尺度感知与上下文理解能力。SCPP通过空洞卷积、多尺度分支及像素级注意力融合机制,使模型能够自适应地捕捉不同尺寸目标的特征,特别在遥感图像、密集场景和小目标检测中表现优异。它提升了目标边界清晰度、抑制了背景干扰,并改善了分割完整性,同时结构轻量、易于集成,不显著影响推理速度。因此,SCPP可有效提升YOLOv13在复杂环境中的检测精度和鲁棒性,具备良好的工程实用价值。
专栏改进目录:YOLOv13改进包含各种卷积、主干网络、各种注意力机制、检测头、损失函数、Neck改进、小目标检测、二次创新模块、HyperACE二次创新、独家创新等几百种创新点改进。
全新YOLOv13创新—发论文改进专栏链接:全新YOLOv13创新改进高效涨点+永久更新中(至少500+改进)+高效跑实验发论文
展示YOLOv13改进后的网络结构图、供小伙伴自己绘图参考:
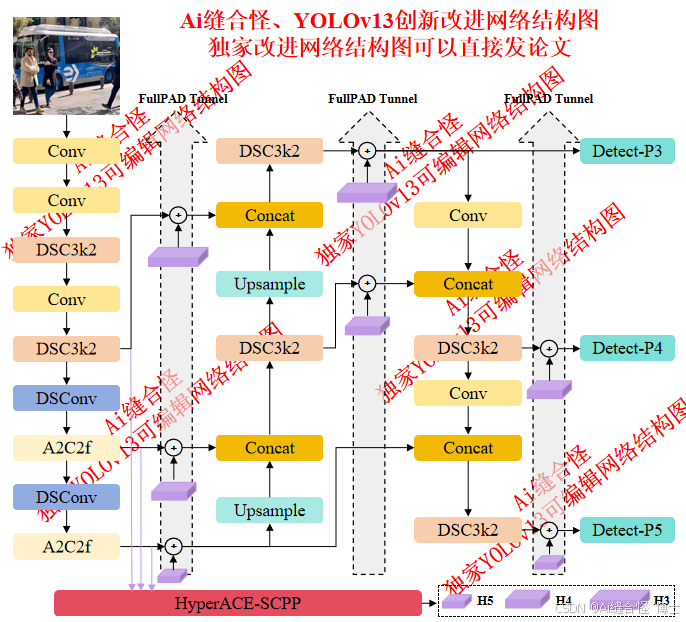
🚀 创新改进结构图: yolov13n_HyperACE_SCPP.yaml
本文目录
1.首先在ultralytics/nn/newsAddmodules创建一个.py文件
2.在ultralytics/nn/newsAddmodules/__init__.py中引用
🚀 创新改进2: yolov13n_DSC3k2_SCPP.yaml
🚀 创新改进3: yolov13n_HyperACE_SCPP.yaml
二、SCPP尺度感知上下文金字塔池化模块介绍

摘要:遥感图像(RSIs)的语义分割在采用深度神经网络后取得了显著进展,利用卷积神经网络(CNN)在局部特征提取方面的优势,以及变换器在全局信息建模方面的能力。然而,由于CNN在长程建模能力上的局限性以及变换器的计算复杂性限制,遥感(RS)语义分割仍然面临诸如严重空洞、边缘分割粗糙,以及光照、阴影等因素导致的误检甚至漏检等问题。为了解决这些问题,我们提出了一种称为GLVMamba的视觉状态空间(VSS)模型,该模型使用CNN作为编码器,并以提出的全局-局部VSS(GLVSS)模块作为核心解码器。具体而言,GLVSS模块引入了局部前向反馈和滑动窗口机制,以解决Mamba在邻近像素依赖建模不足的问题,从而在特征重建过程中增强全局与局部上下文的整合,提升模型的目标感知能力,并有效优化边缘轮廓。此外,我们提出了具有尺度感知的金字塔池化(SCPP)模块,以充分融合各尺度特征,并自适应地融合和提取区分性特征,从而减轻空洞和误检问题。通过GLVSS模块和SCPP模块,GLVMamba能够有效捕捉全局-局部语义信息和多尺度特征,实现高效且准确的遥感语义分割。</

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 186
186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









