




代码
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
from ultralytics.engine.predictor import BasePredictor
from ultralytics.engine.results import Results
from ultralytics.utils import ops
class DetectionPredictor(BasePredictor):
"""
A class extending the BasePredictor class for prediction based on a detection model.
Example:
```python
from ultralytics.utils import ASSETS
from ultralytics.models.yolo.detect import DetectionPredictor
args = dict(model="yolo11n.pt", source=ASSETS)
predictor = DetectionPredictor(overrides=args)
predictor.predict_cli()
```
"""
def postprocess(self, preds, img, orig_imgs, **kwargs):
"""Post-processes predictions and returns a list of Results objects."""
preds = ops.non_max_suppression(
preds,
self.args.conf,
self.args.iou,
self.args.classes,
self.args.agnostic_nms,
max_det=self.args.max_det,
nc=len(self.model.names),
end2end=getattr(self.model, "end2end", False),
rotated=self.args.task == "obb",
)
if not isinstance(orig_imgs, list): # input images are a torch.Tensor, not a list
orig_imgs = ops.convert_torch2numpy_batch(orig_imgs)
return self.construct_results(preds, img, orig_imgs, **kwargs)
def construct_results(self, preds, img, orig_imgs):
"""
Constructs a list of result objects from the predictions.
Args:
preds (List[torch.Tensor]): List of predicted bounding boxes and scores.
img (torch.Tensor): The image after preprocessing.
orig_imgs (List[np.ndarray]): List of original images before preprocessing.
Returns:
(list): List of result objects containing the original images, image paths, class names, and bounding boxes.
"""
return [
self.construct_result(pred, img, orig_img, img_path)
for pred, orig_img, img_path in zip(preds, orig_imgs, self.batch[0])
]
def construct_result(self, pred, img, orig_img, img_path):
"""
Constructs the result object from the prediction.
Args:
pred (torch.Tensor): The predicted bounding boxes and scores.
img (torch.Tensor): The image after preprocessing.
orig_img (np.ndarray): The original image before preprocessing.
img_path (str): The path to the original image.
Returns:
(Results): The result object containing the original image, image path, class names, and bounding boxes.
"""
pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)
return Results(orig_img, path=img_path, names=self.model.names, boxes=pred[:, :6])
继承BasePredictor: 有preprocess和pre_transform和stream_inference等方法
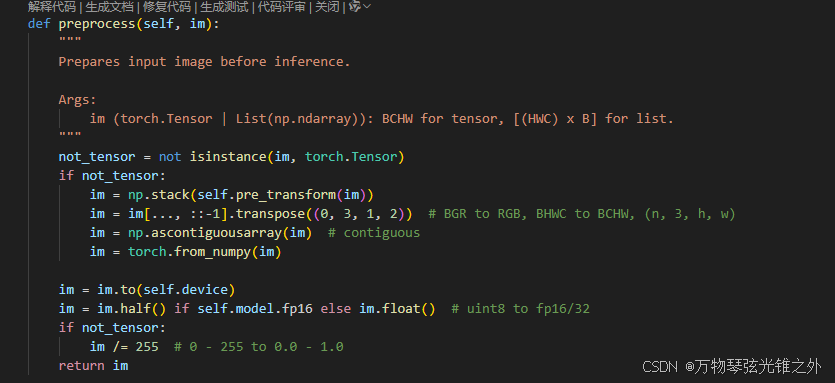
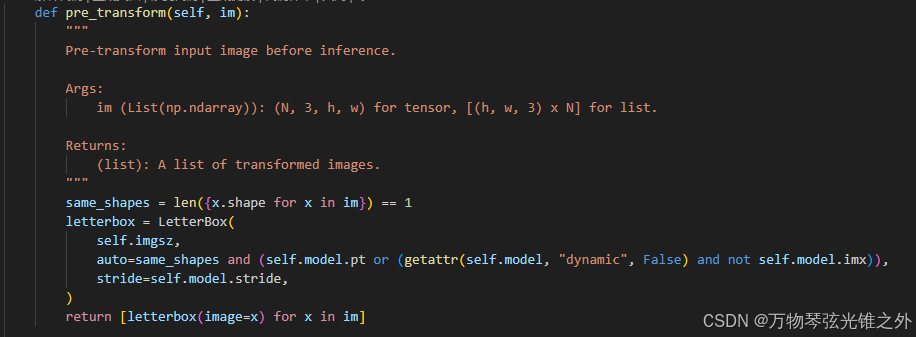
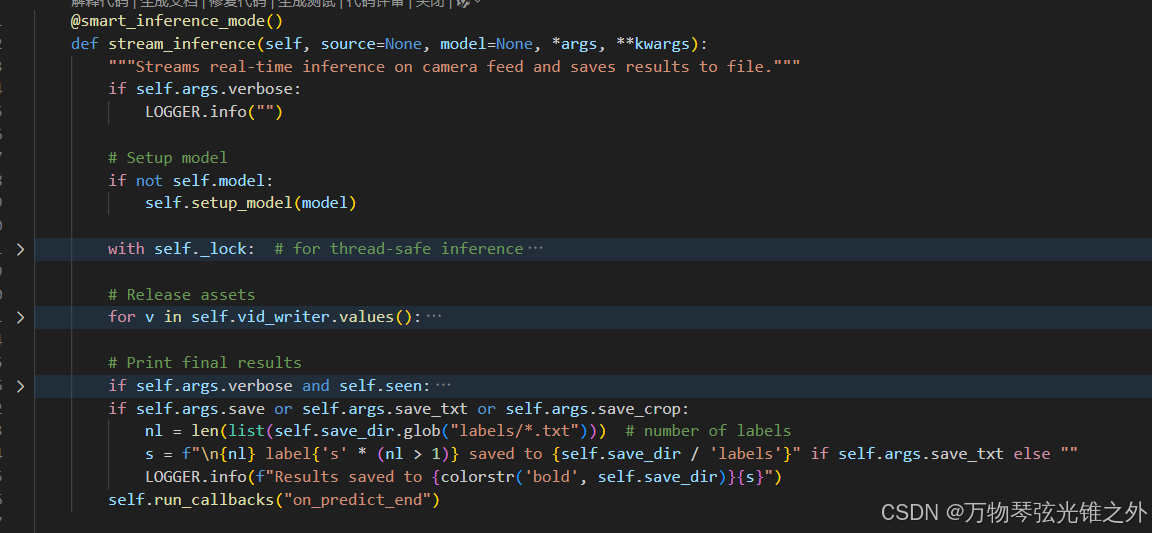
自己重写了 postprocess:
主要关注nms和construct_results
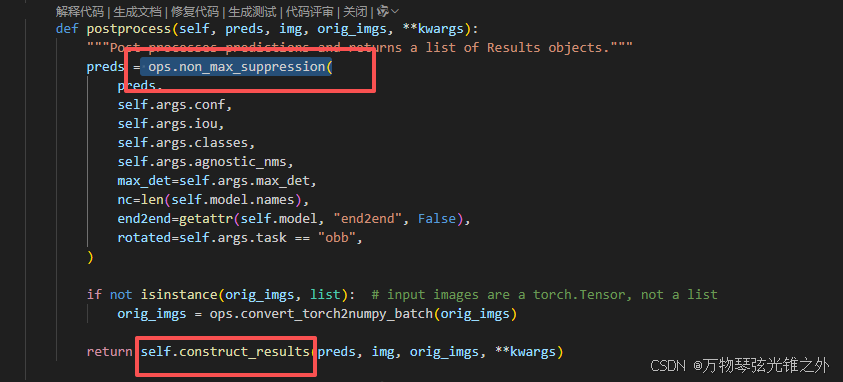
construct_results就是构造成独有的Result对象
non_max_pression就是极大值抑制,具体代码如下:
non_max_suppression
def non_max_suppression(
prediction,
conf_thres=0.25,
iou_thres=0.45,
classes=None,
agnostic=False,
multi_label=False,
labels=(),
max_det=300,
nc=0, # number of classes (optional)
max_time_img=0.05,
max_nms=30000,
max_wh=7680,
in_place=True,
rotated=False,
end2end=False,
):
"""
Perform non-maximum suppression (NMS) on a set of boxes, with support for masks and multiple labels per box.
Args:
prediction (torch.Tensor): A tensor of shape (batch_size, num_classes + 4 + num_masks, num_boxes)
containing the predicted boxes, classes, and masks. The tensor should be in the format
output by a model, such as YOLO.
conf_thres (float): The confidence threshold below which boxes will be filtered out.
Valid values are between 0.0 and 1.0.
iou_thres (float): The IoU threshold below which boxes will be filtered out during NMS.
Valid values are between 0.0 and 1.0.
classes (List[int]): A list of class indices to consider. If None, all classes will be considered.
agnostic (bool): If True, the model is agnostic to the number of classes, and all
classes will be considered as one.
multi_label (bool): If True, each box may have multiple labels.
labels (List[List[Union[int, float, torch.Tensor]]]): A list of lists, where each inner
list contains the apriori labels for a given image. The list should be in the format
output by a dataloader, with each label being a tuple of (class_index, x1, y1, x2, y2).
max_det (int): The maximum number of boxes to keep after NMS.
nc (int, optional): The number of classes output by the model. Any indices after this will be considered masks.
max_time_img (float): The maximum time (seconds) for processing one image.
max_nms (int): The maximum number of boxes into torchvision.ops.nms().
max_wh (int): The maximum box width and height in pixels.
in_place (bool): If True, the input prediction tensor will be modified in place.
rotated (bool): If Oriented Bounding Boxes (OBB) are being passed for NMS.
end2end (bool): If the model doesn't require NMS.
Returns:
(List[torch.Tensor]): A list of length batch_size, where each element is a tensor of
shape (num_boxes, 6 + num_masks) containing the kept boxes, with columns
(x1, y1, x2, y2, confidence, class, mask1, mask2, ...).
"""
import torchvision # scope for faster 'import ultralytics'
# Checks
assert 0 <= conf_thres <= 1, f"Invalid Confidence threshold {conf_thres}, valid values are between 0.0 and 1.0"
assert 0 <= iou_thres <= 1, f"Invalid IoU {iou_thres}, valid values are between 0.0 and 1.0"
if isinstance(prediction, (list, tuple)): # YOLOv8 model in validation model, output = (inference_out, loss_out)
prediction = prediction[0] # select only inference output
if classes is not None:
classes = torch.tensor(classes, device=prediction.device)
if prediction.shape[-1] == 6 or end2end: # end-to-end model (BNC, i.e. 1,300,6)
output = [pred[pred[:, 4] > conf_thres][:max_det] for pred in prediction]
if classes is not None:
output = [pred[(pred[:, 5:6] == classes).any(1)] for pred in output]
return output
bs = prediction.shape[0] # batch size (BCN, i.e. 1,84,6300)
nc = nc or (prediction.shape[1] - 4) # number of classes
nm = prediction.shape[1] - nc - 4 # number of masks
mi = 4 + nc # mask start index
xc = prediction[:, 4:mi].amax(1) > conf_thres # candidates
# Settings
# min_wh = 2 # (pixels) minimum box width and height
time_limit = 2.0 + max_time_img * bs # seconds to quit after
multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
prediction = prediction.transpose(-1, -2) # shape(1,84,6300) to shape(1,6300,84)
if not rotated:
if in_place:
prediction[..., :4] = xywh2xyxy(prediction[..., :4]) # xywh to xyxy
else:
prediction = torch.cat((xywh2xyxy(prediction[..., :4]), prediction[..., 4:]), dim=-1) # xywh to xyxy
t = time.time()
output = [torch.zeros((0, 6 + nm), device=prediction.device)] * bs
for xi, x in enumerate(prediction): # image index, image inference
# Apply constraints
# x[((x[:, 2:4] < min_wh) | (x[:, 2:4] > max_wh)).any(1), 4] = 0 # width-height
x = x[xc[xi]] # confidence
# Cat apriori labels if autolabelling
if labels and len(labels[xi]) and not rotated:
lb = labels[xi]
v = torch.zeros((len(lb), nc + nm + 4), device=x.device)
v[:, :4] = xywh2xyxy(lb[:, 1:5]) # box
v[range(len(lb)), lb[:, 0].long() + 4] = 1.0 # cls
x = torch.cat((x, v), 0)
# If none remain process next image
if not x.shape[0]:
continue
# Detections matrix nx6 (xyxy, conf, cls)
box, cls, mask = x.split((4, nc, nm), 1)
if multi_label:
i, j = torch.where(cls > conf_thres)
x = torch.cat((box[i], x[i, 4 + j, None], j[:, None].float(), mask[i]), 1)
else: # best class only
conf, j = cls.max(1, keepdim=True)
x = torch.cat((box, conf, j.float(), mask), 1)[conf.view(-1) > conf_thres]
# Filter by class
if classes is not None:
x = x[(x[:, 5:6] == classes).any(1)]
# Check shape
n = x.shape[0] # number of boxes
if not n: # no boxes
continue
if n > max_nms: # excess boxes
x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence and remove excess boxes
# Batched NMS
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
scores = x[:, 4] # scores
if rotated:
boxes = torch.cat((x[:, :2] + c, x[:, 2:4], x[:, -1:]), dim=-1) # xywhr
i = nms_rotated(boxes, scores, iou_thres)
else:
boxes = x[:, :4] + c # boxes (offset by class)
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
i = i[:max_det] # limit detections
# # Experimental
# merge = False # use merge-NMS
# if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
# # Update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
# from .metrics import box_iou
# iou = box_iou(boxes[i], boxes) > iou_thres # IoU matrix
# weights = iou * scores[None] # box weights
# x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
# redundant = True # require redundant detections
# if redundant:
# i = i[iou.sum(1) > 1] # require redundancy
output[xi] = x[i]
if (time.time() - t) > time_limit:
LOGGER.warning(f"WARNING ⚠️ NMS time limit {time_limit:.3f}s exceeded")
break # time limit exceeded
return output
核心是一个这个:
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
ops.scale_boxes
def scale_boxes(img1_shape, boxes, img0_shape, ratio_pad=None, padding=True, xywh=False):
"""
Rescales bounding boxes (in the format of xyxy by default) from the shape of the image they were originally
specified in (img1_shape) to the shape of a different image (img0_shape).
Args:
img1_shape (tuple): The shape of the image that the bounding boxes are for, in the format of (height, width).
boxes (torch.Tensor): the bounding boxes of the objects in the image, in the format of (x1, y1, x2, y2)
img0_shape (tuple): the shape of the target image, in the format of (height, width).
ratio_pad (tuple): a tuple of (ratio, pad) for scaling the boxes. If not provided, the ratio and pad will be
calculated based on the size difference between the two images.
padding (bool): If True, assuming the boxes is based on image augmented by yolo style. If False then do regular
rescaling.
xywh (bool): The box format is xywh or not, default=False.
Returns:
boxes (torch.Tensor): The scaled bounding boxes, in the format of (x1, y1, x2, y2)
"""
if ratio_pad is None: # calculate from img0_shape
gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
pad = (
round((img1_shape[1] - img0_shape[1] * gain) / 2 - 0.1),
round((img1_shape[0] - img0_shape[0] * gain) / 2 - 0.1),
) # wh padding
else:
gain = ratio_pad[0][0]
pad = ratio_pad[1]
if padding:
boxes[..., 0] -= pad[0] # x padding
boxes[..., 1] -= pad[1] # y padding
if not xywh:
boxes[..., 2] -= pad[0] # x padding
boxes[..., 3] -= pad[1] # y padding
boxes[..., :4] /= gain
return clip_boxes(boxes, img0_shape)
老东西了,扣除padding后,除以gain,返回到最初的大小。这里有个clip_boxes:
def clip_boxes(boxes, shape):
"""
Takes a list of bounding boxes and a shape (height, width) and clips the bounding boxes to the shape.
Args:
boxes (torch.Tensor): The bounding boxes to clip.
shape (tuple): The shape of the image.
Returns:
(torch.Tensor | numpy.ndarray): The clipped boxes.
"""
if isinstance(boxes, torch.Tensor): # faster individually (WARNING: inplace .clamp_() Apple MPS bug)
boxes[..., 0] = boxes[..., 0].clamp(0, shape[1]) # x1
boxes[..., 1] = boxes[..., 1].clamp(0, shape[0]) # y1
boxes[..., 2] = boxes[..., 2].clamp(0, shape[1]) # x2
boxes[..., 3] = boxes[..., 3].clamp(0, shape[0]) # y2
else: # np.array (faster grouped)
boxes[..., [0, 2]] = boxes[..., [0, 2]].clip(0, shape[1]) # x1, x2
boxes[..., [1, 3]] = boxes[..., [1, 3]].clip(0, shape[0]) # y1, y2
return boxes
就是个控制上下界,避免计算错误


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











