




工作流程:
1、准备数据
准备图片数据,如果图片比640*640大很多,就用学习记录(六)中的脚本把图片裁切成640*640。https://blog.youkuaiyun.com/xulibo5828/article/details/155039775
脚本内容:
# 将标注过的大图片分割为640x640的块,并保存json文件
import copy
import json
import cv2
import os
from pathlib import Path
# 将图像尺寸调整为640的倍数
def split_image_into_blocks(image_path, output_dir, block_width=640, block_height=640):
block_count = 0 # 块计数器
# 创建输出目录
os.makedirs(output_dir, exist_ok=True)
# 读取图片
image = cv2.imread(image_path)
if image is None:
raise ValueError(f"无法读取图片: {image_path}")
# 调整图片尺寸
height, width = image.shape[:2]
_, b = divmod(width, block_width)
w_out = width + block_width - b # 调整为640的倍数
_, b = divmod(height, block_height)
h_out = height + block_height - b # 调整为640的倍数
img = cv2.resize(image, (w_out, h_out), interpolation=cv2.INTER_CUBIC)
# 放大比例
w_scale = w_out / width
h_scale = h_out / height
# 获取同名json文件
file_name = Path(image_path).stem
try:
with open(file_name + '.json', encoding="utf-8") as f:
json_data = json.load(f) # 同名图片文件的json数据
except:
json_data = None
# 获取图片尺寸
height, width = img.shape[:2]
print(f"调整后的大图片尺寸: 宽{width} x 高{height}")
print(f"分割块尺寸: 宽{block_width} x 高{block_height}")
# 计算可以分割的块数(按完整块计算)
num_blocks_width = width // block_width
num_blocks_height = height // block_height
print(f"将分割为 {num_blocks_width}x{num_blocks_height} 个图片块")
# 分割并保存块
for i in range(num_blocks_height):
for j in range(num_blocks_width):
# 计算当前块的坐标(左上角开始)
start_x = j * block_width
start_y = i * block_height
end_x = start_x + block_width
end_y = start_y + block_height
# 提取图片块
block = img[start_y:end_y, start_x:end_x]
# 保存图片块(文件名包含行列信息)
block_filename = os.path.join(
output_dir,
f"{file_name}_row{i}_col{j}_index{block_count}.jpg"
)
json_filename = os.path.join(
output_dir,
f"{file_name}_row{i}_col{j}_index{block_count}.json"
)
cv2.imwrite(block_filename, block) # 保存图片块
# 更新json文件
if json_data is None:
print(f"无法读取json文件: {file_name}.json")
block_count += 1
continue
data= copy.deepcopy(json_data) # 复制json数据,避免修改原数据
for shape in data['shapes']:
points = []
for point in shape['points']:
w = round(point[0] * w_scale, 0) - start_x # 坐标按照小块的0点重新定位
h = round(point[1] * h_scale, 0) - start_y
if 0 <= w <= block_width and 0 <= h <= block_height: # 如果坐标在小块内,则添加到points中
points.append([w, h])
# 如果points的长度大于20,则保留,否则删除
if len(points) > 20:
shape['points'] = points
else:
shape['points'] = []
data['shapes'] = [item for item in data['shapes'] if item['points'] != []] # 删除points为空的形状
data['imagePath'] = f"{file_name}_row{i}_col{j}_index{block_count}.jpg" # 更新图片路径
data['imageHeight'] = block_height # 更新图片高度
data['imageWidth'] = block_width # 更新图片宽度
# 更新json文件
with open(json_filename, 'w', encoding="utf-8") as f:
json.dump(data, f)
block_count += 1
print(f"分割完成,共生成 {block_count} 个图像块")
if __name__ == "__main__":
# 替换为你的图片路径
input_image_path = "img000012.jpg"
split_image_into_blocks(
image_path=input_image_path, output_dir='new')2、标注图片
使用AnyLabeling 标注图片,方法学习记录(四)。https://blog.youkuaiyun.com/xulibo5828/article/details/145576775
3、转换成YOLO格式
将数据转换成YOLO格式,并自动生成数据集和设置文件。学习记录(五)。
https://blog.youkuaiyun.com/xulibo5828/article/details/154795464
# 将·AnyLabeling标注的json文件转换为YOLO格式
import json
import os
import random
import shutil
from pathlib import Path
import yaml
def convert_AnyLabeling_to_YOLO(source_path, target_path, copy_image=False, divide_train_val=True):
# 创建目标文件夹
os.makedirs(os.path.join(target_path, 'labels', 'train'), exist_ok=True)
os.makedirs(os.path.join(target_path, 'labels', 'val'), exist_ok=True)
os.makedirs(os.path.join(target_path, 'labels', 'test'), exist_ok=True)
os.makedirs(os.path.join(target_path, 'images', 'train'), exist_ok=True)
os.makedirs(os.path.join(target_path, 'images', 'val'), exist_ok=True)
os.makedirs(os.path.join(target_path, 'images', 'test'), exist_ok=True)
file_idx = 0 # 当前处理文件的索引(用来区分训练集和验证集)
classes_file = os.path.join(source_path, 'classes.txt') # 类别文件,所有分类标签
yaml_file = os.path.join(target_path, 'dataset.yaml') # 设置文件
# 读取json文件
jsons = list(Path(source_path).resolve().glob("*.json")) # 获取json文件列表
random.shuffle(jsons) # 随机打乱json文件列表
jsons_count = len(list(jsons)) # json文件数量
# 标签类别文件的处理
if not os.path.exists(classes_file): # 如果不存在标签类别文件,则创建一个空文件
with open(classes_file, 'w', encoding='utf-8') as cf:
cf.write('')
with open(classes_file, 'r+', encoding='utf-8') as cf:
classes = cf.read().splitlines() # 读取标签类别文件中的所有标签,并存储在列表中
# 从json文件中读取标签类别并写入标签类别文件
for file in jsons:
with open(file, 'r', encoding='utf-8') as jf:
data = json.load(jf)
for d in data['shapes']:
if d['label'] not in classes:
classes.append(d['label'])
cf.write(f"{d['label']}\n")
if divide_train_val and jsons_count < 10:
print(f"{source_path} 文件夹中json文件数量小于10,不进行转换")
return
# 开始转换json文件
for json_file in jsons:
# 读取json文件并获取数据
file_name = json_file.stem # 文件名(不带后缀)
with open(json_file, encoding="utf-8") as f:
data = json.load(f) # json数据
# 数据集的划分
if file_idx < jsons_count * 0.7:
purpose = 'train'
elif file_idx < jsons_count * 0.9:
purpose = 'val'
else:
purpose = 'test'
if not divide_train_val: # 如果不划分训练集和验证集,则全部写入训练集
purpose = 'train'
h, w = data['imageHeight'], data['imageWidth'] # 图片的宽度和高度
# 写入标注文件
with open(os.path.join(target_path, 'labels', purpose, file_name + '.txt'), 'w') as f:
for d in data['shapes']:
label_idx = str(classes.index(d['label'])) # 类别在类别表中的索引顺序
points = d['points']
line = label_idx # 写入类别索引(每一行的第一个数字)
# 写入坐标点
for point in points:
x = point[0] / w
y = point[1] / h
x = max(0, min(1, x))
y = max(0, min(1, y))
x = round(x, 6)
y = round(y, 6)
line += ' ' + str(x) + ' ' + str(y)
line += '\n' # 写入换行符
f.write(line)
# 如果需要复制图片到images文件夹中,则复制图片到images文件夹中
if copy_image:
jpg_file = os.path.join(source_path, file_name + '.jpg')
png_file = os.path.join(source_path, file_name + '.png')
if os.path.exists(jpg_file):
shutil.copy(jpg_file, os.path.join(target_path, 'images', purpose, file_name + '.jpg'))
if os.path.exists(png_file):
shutil.copy(png_file, os.path.join(target_path, 'images', purpose, file_name + '.png'))
file_idx += 1
# 设置文件的处理
if not os.path.exists(yaml_file): # 如果不存在yaml文件,则创建一个空文件
with open(yaml_file, 'w', encoding='utf-8') as f:
f.write('')
with open(yaml_file, 'r+', encoding='utf-8') as f:
data = yaml.safe_load(f) or {}
data['path'] = target_path
data['train'] = os.path.join('..', 'images', 'train')
data['val'] = os.path.join('..','images', 'val')
data['test'] = os.path.join('..','images', 'test')
data['nc'] = len(classes)
data['names'] = classes
yaml.dump(data, f, allow_unicode=True, default_flow_style=False, sort_keys=False)
print(f"{source_path} 文件夹中的json文件转换完成")
if __name__ == '__main__':
convert_AnyLabeling_to_YOLO('custom_blocks', r'datasets', copy_image=True)4、训练
不使用预训练模型从头训练:
yolo task=segment mode=train model=yolo11s-seg.yaml data=dataset.yaml epochs=100 imgsz=640 batch=16 device=0,1 workers=2在已有模型基础上微调训练:
yolo task=segment mode=train model=已有模型.pt data=dataset.yaml epochs=100 imgsz=640 batch=16 device=0,1 workers=2微调参数,再次优化训练:
yolo task=segment \
mode=train \
model=datasets/runs/segment/train5/weights/best.pt \
data=datasets/dataset.yaml \
epochs=200 \
imgsz=640 \
batch=4 \
device=0,1 \
workers=2 \
lr0=0.001 \
lrf=0.005 \
cos_lr=True在项目的runs目录下的args.yaml文件中,可以看到所有的训练参数
5、训练参数详解
下面是一次训练的参数:
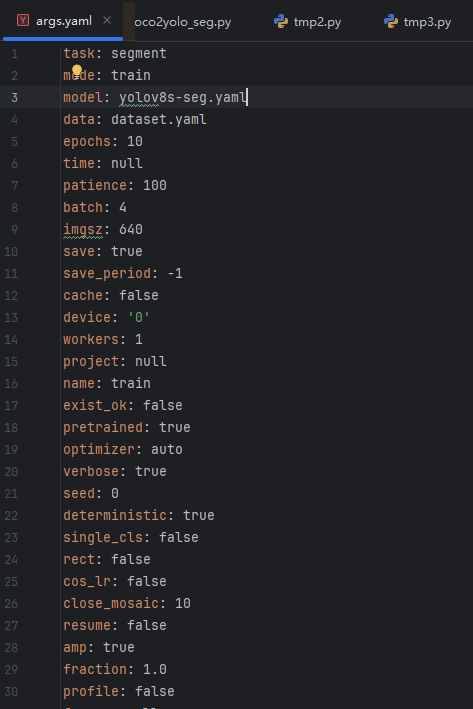
以下是对这些参数的逐行解释:
一、核心任务与模式配置
| 参数 | 含义与说明 |
|---|---|
task: segment | 任务类型:指定为图像分割任务(YOLOv8 支持 detect (检测)、segment (分割)、classify (分类) 等)。 |
mode: train | 运行模式:指定为训练模式(其他模式如 val (验证)、predict (预测)、export (导出))。 |
二、模型与数据配置
| 参数 | 含义与说明 |
|---|---|
model: yolov8s-seg.yaml | 所使用的模型配置文件:YOLOv8-small(s=small)版本的分割模型配置,定义了网络结构、通道数等。 |
data: dataset.yaml | 数据集配置文件:指定数据集的路径(训练集 / 验证集 / 测试集)、类别名称、类别数等核心信息,是训练的关键配置。 |
pretrained: true | 是否使用预训练权重:true 表示加载官方预训练权重(基于 COCO 数据集),用于迁移学习,提升训练效果和收敛速度;false 则从零开始训练。 |
三、训练核心参数(迭代、批次、设备)
| 参数 | 含义与说明 |
|---|---|
epochs: 10 | 训练轮数:整个训练集被模型学习的次数,10 表示遍历训练集 10 次(轮数越多拟合能力越强,但可能过拟合,需结合早停调整)。 |
batch: 4 | 批次大小:每次迭代训练时,模型同时处理的图像数量(受 GPU 显存限制,显存越大可设越大,如 8、16;4 是较小的显存友好值)。 |
imgsz: 640 | 输入图像尺寸:训练时将图像 resize 到 640×640 像素(YOLOv8 默认推荐尺寸,需与数据集图像比例适配,避免失真)。 |
device: '0' | 训练设备:指定使用第 0 号 GPU('0'= 单 GPU,'0,1'= 多 GPU,'cpu'=CPU 训练,CPU 速度极慢,不推荐)。 |
workers: 1 | 数据加载线程数:用于并行读取数据集的线程数(值越大加载越快,受 CPU 核心数限制,默认 1 或 4 即可,避免线程过多占用资源)。 |
四、训练早停与优化器配置
| 参数 | 含义与说明 |
|---|---|
patience: 100 | 早停耐心值:当验证集性能(如 mAP)连续 100 个 epoch 没有提升时,自动停止训练(防止无效迭代,节省时间;值越大越晚停)。 |
optimizer: auto | 优化器选择:auto 表示 YOLOv8 自动选择优化器(默认 AdamW,适合大多数场景);也可手动指定sgd、adam等。 |
lr0: 0.01 | 初始学习率:训练起始的学习率(YOLOv8 默认 0.01,是 AdamW 优化器的经典初始值,学习率过大会震荡不收敛,过小会收敛过慢)。 |
lrf: 0.01 | 学习率最终因子:训练末期的学习率 = lr0 × lrf(0.01 表示最终学习率降到初始的 1%,实现学习率衰减,稳定收敛)。 |
momentum: 0.937 | 动量(仅 SGD 优化器生效):加速梯度下降,减少震荡,默认 0.937 是经验值。 |
weight_decay: 0.0005 | 权重衰减:L2 正则化系数,用于抑制过拟合(惩罚模型权重过大,值越大正则化越强,默认 0.0005 平衡拟合与泛化)。 |
warmup_epochs: 3.0 | 热身轮数:前 3 个 epoch 使用低学习率逐步提升到 lr0(避免初始高学习率破坏预训练权重,稳定训练初期)。 |
warmup_momentum: 0.8 | 热身阶段动量:热身时的动量值(低于正常 momentum,配合低学习率稳定初期训练)。 |
warmup_bias_lr: 0.1 | 热身阶段偏置学习率:偏置参数的初始热身学习率(加速偏置参数收敛)。 |
五、损失函数权重配置(分割任务核心)
| 参数 | 含义与说明 |
|---|---|
box: 7.5 | 边界框损失权重:调节检测框位置预测的损失占比(权重越大,模型越重视检测框的精准度)。 |
cls: 0.5 | 类别损失权重:调节类别预测的损失占比(权重越大,模型越重视类别分类的准确率)。 |
dfl: 1.5 | 分布焦点损失(Distribution Focal Loss)权重:用于优化边界框回归的损失,提升小目标检测效果。 |
pose: 12.0 | 姿态损失权重(分割任务中通常无用,仅姿态估计任务生效,此处为默认值,可忽略)。 |
kobj: 1.0 | 关键点目标损失权重(同上,分割任务无用,默认值)。 |
overlap_mask: true | 分割掩码是否允许重叠:true 表示允许多个目标的掩码重叠(符合真实场景,如两个物体部分遮挡)。 |
mask_ratio: 4 | 掩码下采样比例:将原始掩码下采样 4 倍后计算损失(减少计算量,提升训练速度,不影响最终精度)。 |
六、数据增强配置(提升泛化能力)
| 参数 | 含义与说明 |
|---|---|
hsv_h: 0.015 | 色相(H)增强幅度:随机调整图像色相的范围(0~0.015),提升模型对颜色变化的鲁棒性。 |
hsv_s: 0.7 | 饱和度(S)增强幅度:随机调整图像饱和度(0~0.7)。 |
hsv_v: 0.4 | 明度(V)增强幅度:随机调整图像明度(0~0.4)。 |
degrees: 0.0 | 随机旋转角度:图像随机旋转的最大角度(0.0 表示不旋转,避免分割掩码变形过大)。 |
translate: 0.1 | 随机平移幅度:图像在水平 / 垂直方向随机平移(最大偏移量为图像尺寸的 10%)。 |
scale: 0.5 | 随机缩放幅度:图像随机缩放(范围:1-0.5=0.5~1+0.5=1.5 倍),提升模型对目标大小变化的适应力。 |
shear: 0.0 | 随机剪切幅度:不进行剪切变换(避免掩码失真)。 |
perspective: 0.0 | 透视变换幅度:不进行透视变换(默认关闭,防止分割目标形状失真)。 |
flipud: 0.0 | 上下翻转概率:0.0 表示不进行上下翻转(适合目标无上下对称性的场景,如文字、特定物体)。 |
fliplr: 0.5 | 左右翻转概率:50% 的概率对图像进行左右翻转(最常用的增强手段,不改变目标本质,提升泛化)。 |
bgr: 0.0 | BGR 通道反转概率:0.0 表示不反转(YOLOv8 默认使用 RGB 格式,反转无意义)。 |
mosaic: 1.0 | Mosaic 增强概率:1.0 表示每次训练都使用 Mosaic(将 4 张图像拼接成 1 张,丰富背景和目标分布,提升模型鲁棒性)。 |
close_mosaic: 10 | 关闭 Mosaic 的轮数:训练最后 10 个 epoch 关闭 Mosaic(使用原始图像训练,提升检测框和掩码的精准度)。 |
mixup: 0.0 | Mixup 增强概率:0.0 表示不使用(将两张图像混合,适合分类任务,分割任务中可能破坏掩码,默认关闭)。 |
cutmix: 0.0 | Cutmix 增强概率:0.0 表示不使用(类似 Mixup,分割任务不推荐)。 |
copy_paste: 0.0 | 复制粘贴增强概率:0.0 表示不使用(将一个目标的掩码复制到另一张图像,分割任务可选开启)。 |
auto_augment: randaugment | 自动增强策略:使用 Randaugment(轻量级增强策略,平衡效果与速度)。 |
erasing: 0.4 | 随机擦除概率:40% 的概率随机擦除图像部分区域(模拟遮挡场景,提升模型抗遮挡能力)。 |
七、训练保存与输出配置
| 参数 | 含义与说明 |
|---|---|
save: true | 是否保存模型:true 表示训练过程中保存最优模型(基于验证集性能)和最后一轮模型。 |
save_period: -1 | 模型保存周期:-1 表示只保存最优和最后一轮模型;若设为 n,则每 n 个 epoch 保存一次(避免占用过多存储)。 |
save_dir: runs\segment\train | 模型保存路径:训练日志、权重文件、可视化结果等均保存在该目录下(Windows 系统路径格式)。 |
project: null | 项目名称:null 表示使用默认项目目录(runs);可自定义项目名,如project: my_seg,则保存路径为my_seg\segment\train。 |
name: train | 实验名称:当前训练实验的名称,用于区分不同训练任务(如name: train_v1)。 |
exist_ok: false | 是否允许覆盖已有目录:false 表示若save_dir已存在,则报错;true 表示覆盖(适合重复训练同一任务)。 |
plots: true | 是否生成训练可视化图表:true 表示训练完成后生成损失曲线、mAP 曲线、混淆矩阵等图表(便于分析训练效果)。 |
八、验证与评估配置
| 参数 | 含义与说明 |
|---|---|
val: true | 训练过程中是否进行验证:true 表示每个 epoch 结束后,在验证集上评估性能(mAP、Precision、Recall 等),用于早停和模型选择。 |
split: val | 验证集划分:使用数据集配置文件(dataset.yaml)中定义的val集进行验证(也可设为test用测试集验证)。 |
save_json: false | 是否保存 COCO 格式的评估结果:false 表示不保存;true 可用于后续第三方工具分析(如 COCO API)。 |
conf: null | 置信度阈值:验证时的目标置信度阈值(null 表示使用默认值,通常 0.001)。 |
iou: 0.7 | NMS 的 IOU 阈值:非极大值抑制(去除重复检测框)的 IOU 阈值(0.7 为默认值,IOU>0.7 的重复框会被过滤)。 |
max_det: 300 | 单张图像最大检测数量:每张图像最多输出 300 个目标的检测框和掩码(足够覆盖大多数场景)。 |
九、其他辅助配置
| 参数 | 含义与说明 |
|---|---|
time: null | 训练时间限制:null 表示无时间限制;可设为1h、2d等,达到时间后停止训练(较少使用)。 |
cache: false | 是否缓存数据集:false 表示不缓存;true 会将预处理后的图像缓存到磁盘,加速后续训练(首次训练会慢,后续快)。 |
verbose: true | 是否输出详细日志:true 表示训练过程中打印 epoch、损失、mAP 等信息;false 只输出关键信息。 |
seed: 0 | 随机种子:固定随机种子(0),使训练过程可复现(每次运行结果一致,便于调参对比)。 |
deterministic: true | 是否使用确定性算法:true 配合seed保证训练过程完全可复现(避免 GPU 并行计算的随机性)。 |
single_cls: false | 是否单类别训练:false 表示多类别训练;true 表示所有目标视为同一类别(仅单类别数据集使用)。 |
rect: false | 是否使用矩形训练:false 表示所有图像 resize 到固定尺寸(imgsz×imgsz);true 表示按图像原始比例 resize,减少黑边(提升训练速度,但需适配批次处理)。 |
cos_lr: false | 是否使用余弦学习率调度:false 表示使用默认的学习率衰减策略(StepLR);true 用余弦退火调度(适合长训练周期)。 |
resume: false | 是否 resume 训练:false 表示从头开始训练;true 表示从上次中断的 epoch 继续训练(需确保save_dir存在 checkpoint 文件)。 |
amp: true | 是否使用混合精度训练:true 表示使用 FP16 混合精度(减少 GPU 显存占用,提升训练速度,不损失精度);false 用 FP32(显存占用大,速度慢)。 |
fraction: 1.0 | 训练数据占比:1.0 表示使用全部训练集;可设为 0.5 表示使用 50% 数据(快速测试训练流程)。 |
profile: false | 是否性能分析:false 表示不分析;true 会输出数据加载、前向传播、反向传播的耗时(用于优化训练速度)。 |
freeze: null | 冻结网络层:null 表示不冻结;可设为[0,1,2]表示冻结前 3 层(迁移学习时固定底层特征,只训练顶层)。 |
multi_scale: false | 是否多尺度训练:false 表示固定 imgsz;true 表示训练时随机选择 imgsz±50% 的尺寸(提升模型对不同尺度目标的适应力,显存占用会波动)。 |
compile: false | 是否编译模型:false 表示不编译;true 用 PyTorch 2.0 + 的torch.compile加速训练(需 PyTorch 版本支持)。 |
dropout: 0.0 | Dropout 概率:0.0 表示不使用 Dropout(YOLOv8 默认不使用,Dropout 会降低检测 / 分割精度)。 |
half: false | 是否使用半精度推理:false 表示不使用(训练时由amp控制,此处为推理参数,训练时无用)。 |
dnn: false | 是否使用 OpenCV DNN 推理:false 表示不使用(训练时无用,推理时可选)。 |
source: null | 推理数据源:null 表示训练时不进行推理(推理时需指定图像 / 视频路径)。 |
vid_stride: 1 | 视频帧采样间隔:推理视频时,每 1 帧取 1 帧(训练时无用)。 |
stream_buffer: false | 是否流式缓冲:推理时是否缓冲视频流(训练时无用)。 |
visualize: false | 是否可视化特征图:false 表示不可视化;true 会输出网络中间层特征图(用于调试模型)。 |
augment: false | 推理时是否使用增强:false 表示不使用(训练时增强已生效,推理时用原始图像)。 |
agnostic_nms: false | 是否类别无关 NMS:false 表示按类别进行 NMS;true 表示忽略类别,直接对所有检测框 NMS(多类别场景不推荐)。 |
classes: null | 筛选类别:null 表示检测所有类别;可设为[0,2]表示只检测第 0、2 类(训练时无用,推理时可选)。 |
retina_masks: false | 是否使用 Retina 掩码:false 表示不使用(分割掩码的后处理方式,默认关闭)。 |
embed: null | 特征嵌入维度:null 表示不使用(用于迁移学习提取特征,训练时无用)。 |
show: false | 是否显示推理结果:false 表示不显示(训练时无用)。 |
save_frames: false | 是否保存推理视频帧:false 表示不保存(训练时无用)。 |
save_txt: false | 是否保存检测结果到 txt 文件:false 表示不保存(训练时无用,推理时可选)。 |
save_conf: false | 是否保存置信度到 txt:false 表示不保存(推理时可选)。 |
save_crop: false | 是否保存裁剪的目标区域:false 表示不保存(推理时可选)。 |
show_labels: true | 推理时是否显示类别标签:true 表示显示(训练时无用)。 |
show_conf: true | 推理时是否显示置信度:true 表示显示(训练时无用)。 |
show_boxes: true | 推理时是否显示检测框:true 表示显示(训练时无用)。 |
line_width: null | 绘制框 / 掩码的线宽:null 表示自动适配(训练时无用)。 |
format: torchscript | 模型导出格式:训练时无用,导出模型时指定为 TorchScript 格式(其他格式如onnx、tensorrt等)。 |
keras: false | 是否导出为 Keras 格式:false 表示不导出(训练时无用)。 |
optimize: false | 导出时是否优化:false 表示不优化(导出 ONNX 等格式时可选)。 |
int8: false | 是否导出为 INT8 量化模型:false 表示不量化(量化可减小模型体积,提升推理速度,损失少量精度)。 |
dynamic: false | 是否导出动态维度模型:false 表示固定输入尺寸(imgsz×imgsz);true 支持任意尺寸输入(推理时灵活,训练时无用)。 |
simplify: true | 导出时是否简化模型:true 表示简化 ONNX 等模型的计算图(减少冗余节点,提升推理速度)。 |
opset: null | ONNX 算子集版本:null 表示自动选择(导出 ONNX 时使用)。 |
workspace: null | TensorRT 工作空间大小:null 表示默认(导出 TensorRT 时使用)。 |
nms: false | 导出时是否内置 NMS:false 表示不内置(推理时手动执行 NMS)。 |
cfg: null | 额外配置文件:null 表示不使用(可指定其他细分配置文件,较少用)。 |
tracker: botsort.yaml | 跟踪器配置文件:训练时无用,目标跟踪任务(detect+track)时指定跟踪器(如 BotSort)。 |
总结
这份配置是 YOLOv8s 分割模型的标准训练配置,核心逻辑是:使用预训练权重迁移学习,10 轮训练,批次 4,输入尺寸 640,启用混合精度和常用数据增强,训练过程中验证并保存最优模型。可根据实际需求调整(如增大batch、增加epochs、开启multi_scale等),重点关注data(数据集配置)、epochs(轮数)、batch(批次)、device(设备)这几个关键参数。


















 1253
1253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











