







01.js 框架入门
02.js 中间件
03.js app.use
04.js 中间件应用
05.js 错误处理中间件
06.js 异步函数错误的捕获
07.js 构建模块化路由的基础代码
08.js 构建模块化路由
09.js 如何获取get请求参数
10.js 如何获取post请求参数
11.js app.use方法
12.js 路由参数
13.js 静态资源访问功能
14.js 模板引擎
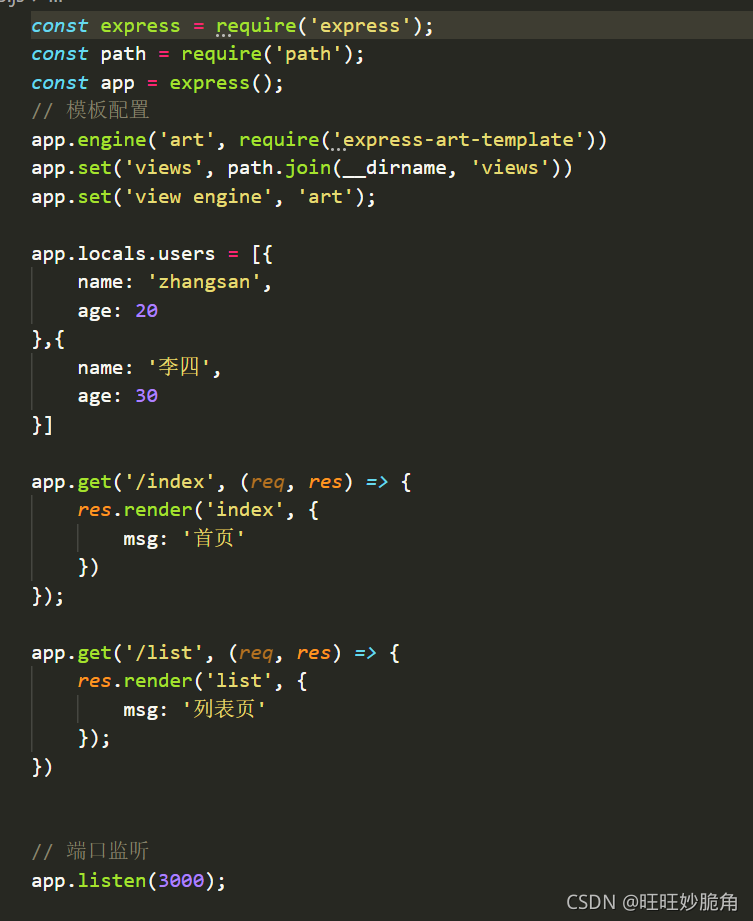
14.js app.locals对象
express的send方法比原生Node.js end优越之处
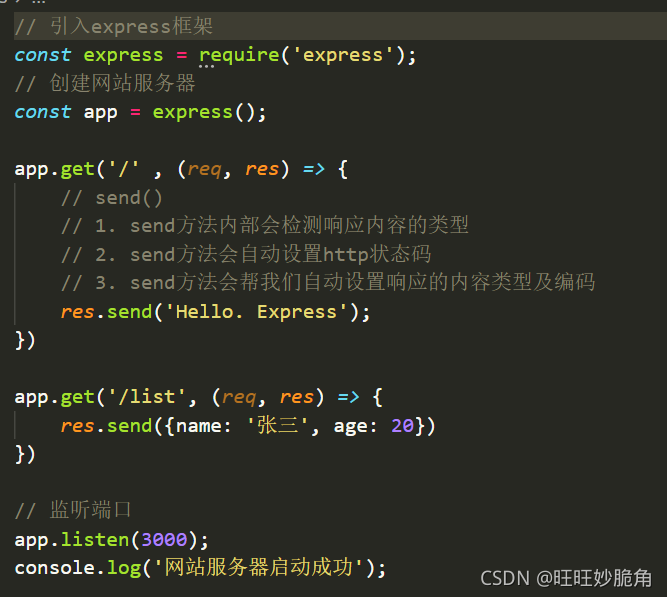
中间件next
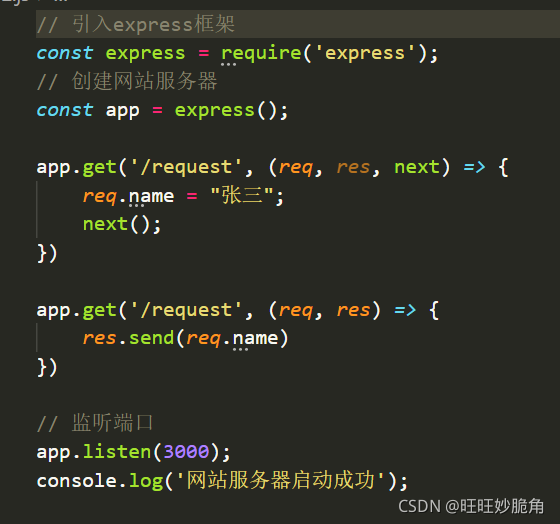
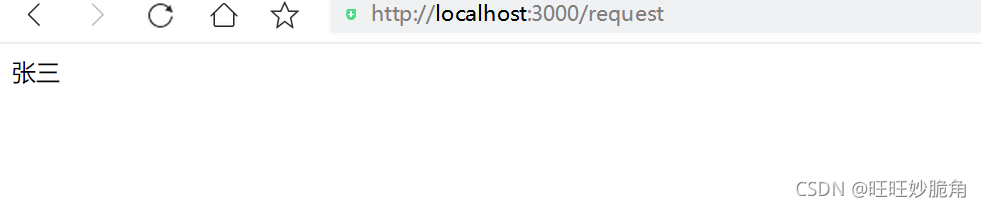

next作用

错误处理中间件
next err

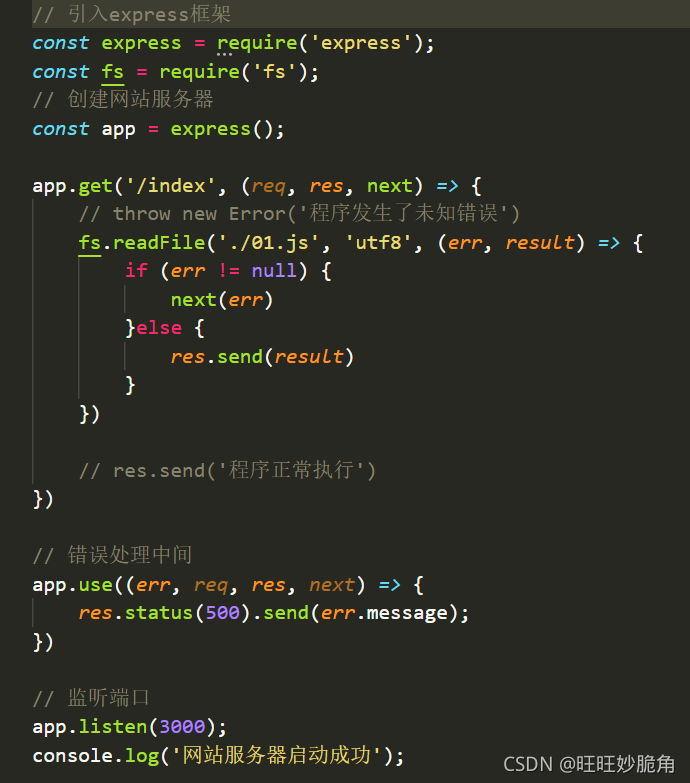
throw是同步,异步有四个参数
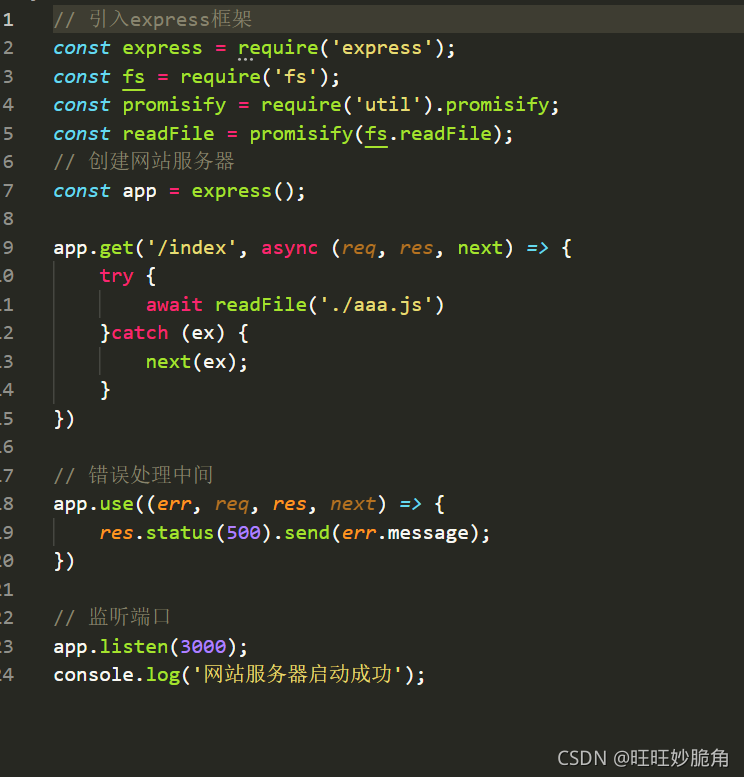
中间件捕获错误
try catch方法捕获同步错误和异步错误
一级二级路由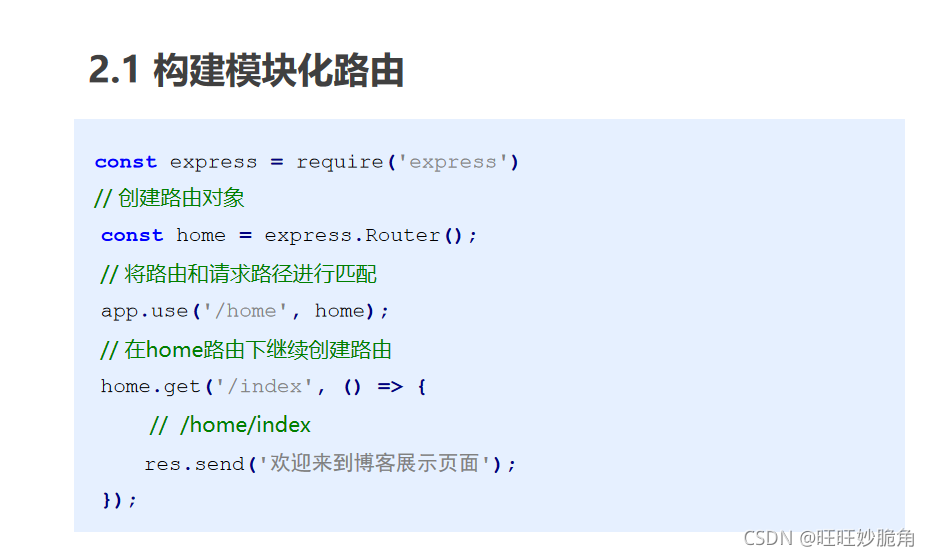
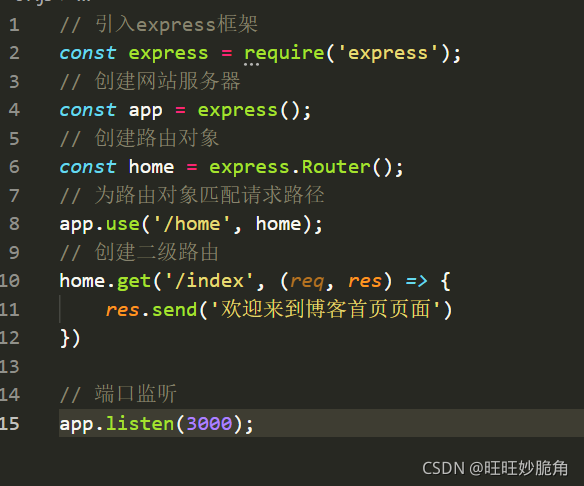

模块化路由

创建路由并导出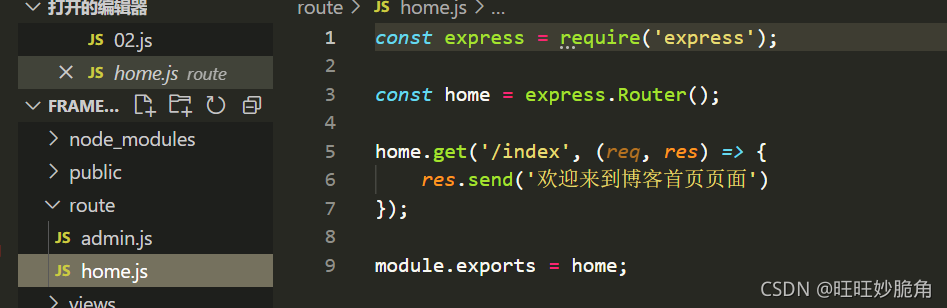
通过require创建的二级路由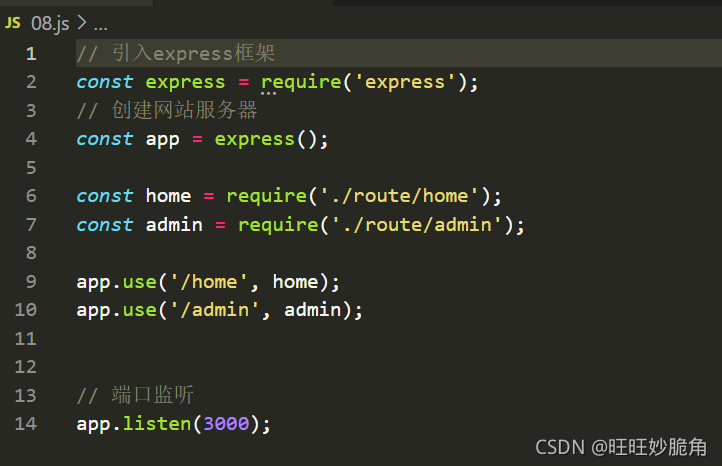
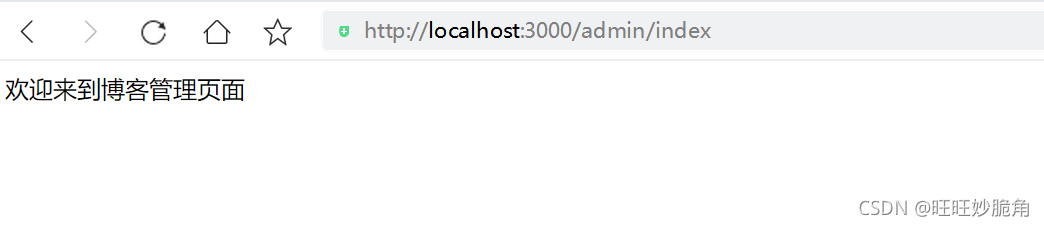 在express框架下用req.query获得get请求参数
在express框架下用req.query获得get请求参数


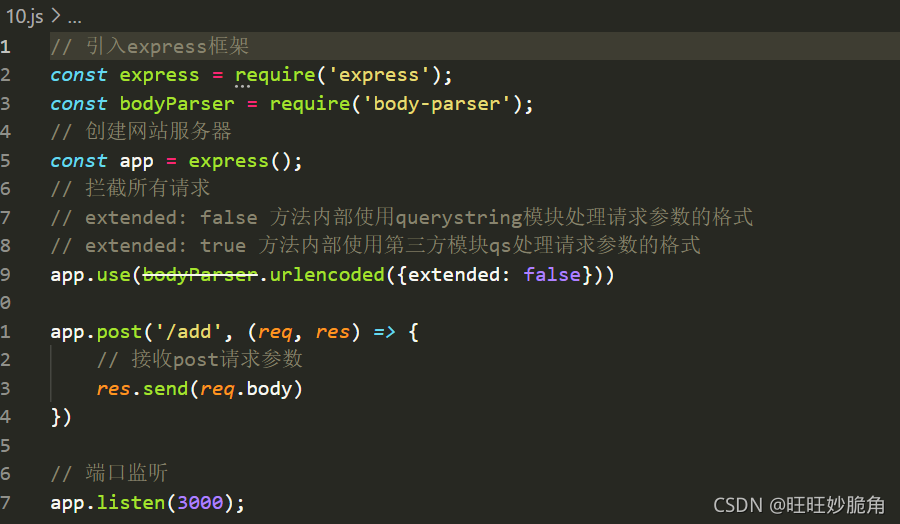
在express框架下用body-parser来获得post参数
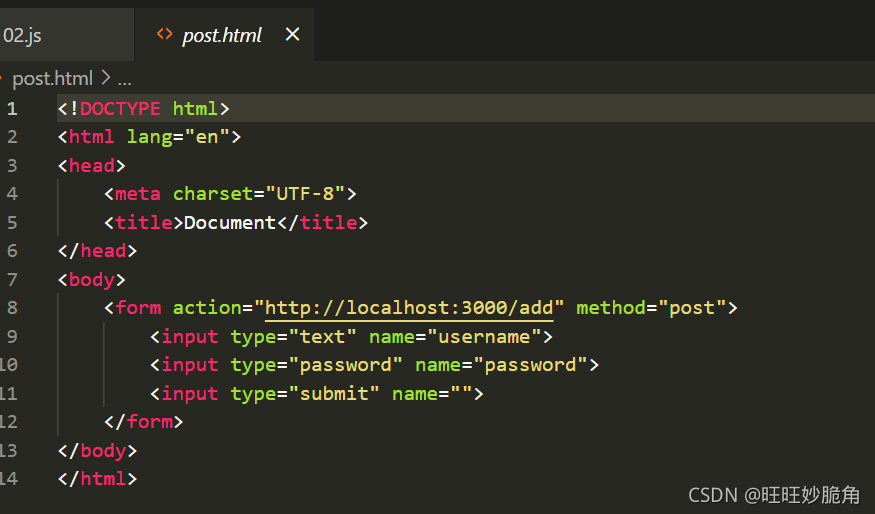
利用表单


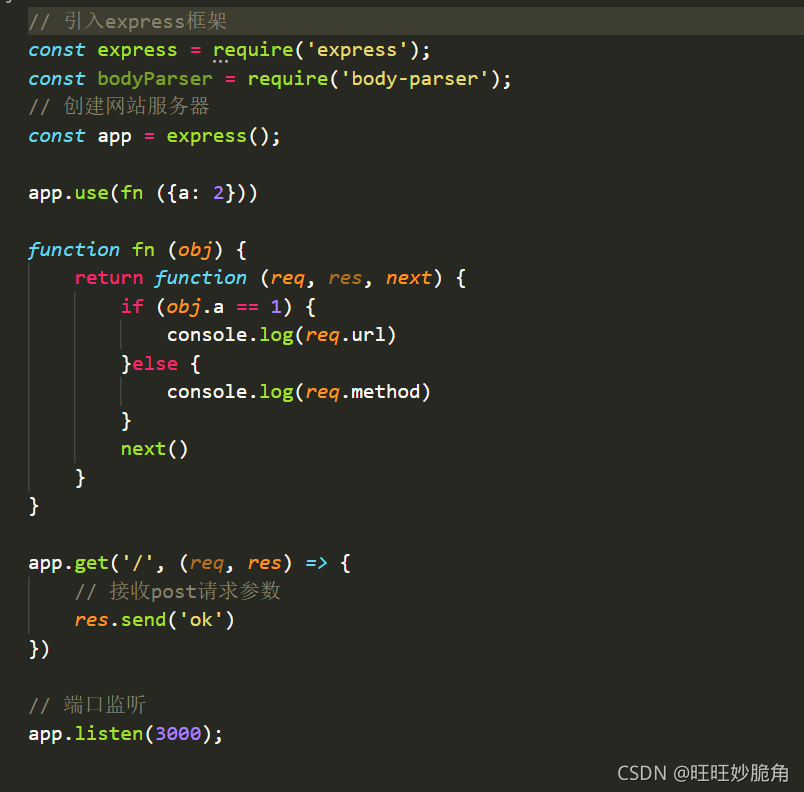
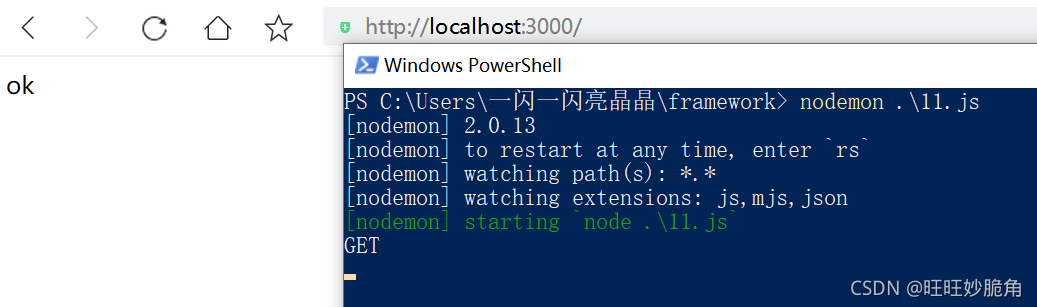
app.use中传递了一个函数的调用
添加判断,等于1输出地址 不等于一输出方法
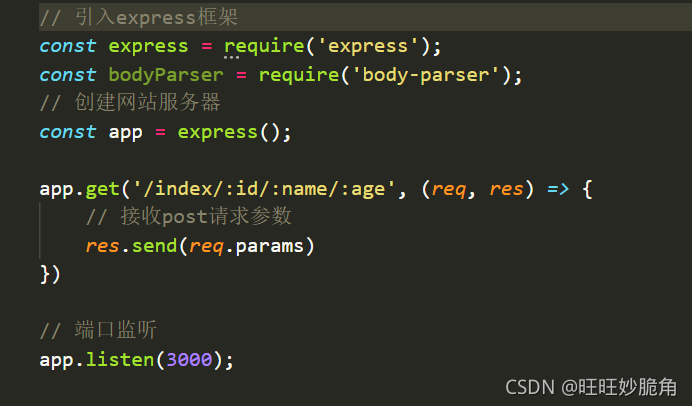
express中利用路由参数来获取get参数的方式
/:id/:name


实现静态资源访问的功能
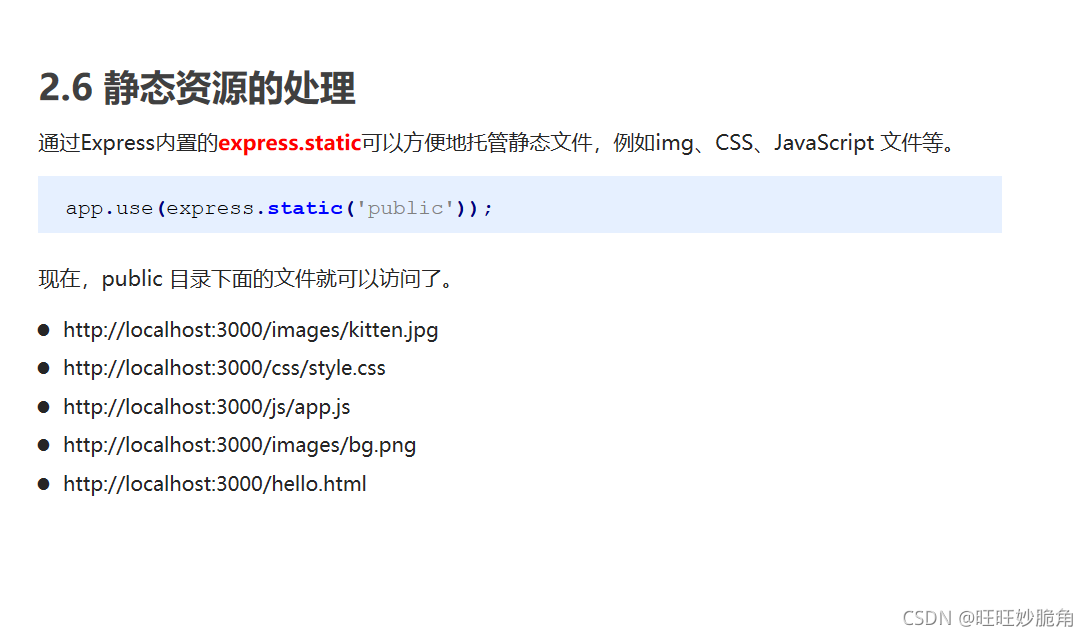
app.use('/static', express.static(path.join(__dirname, 'public')))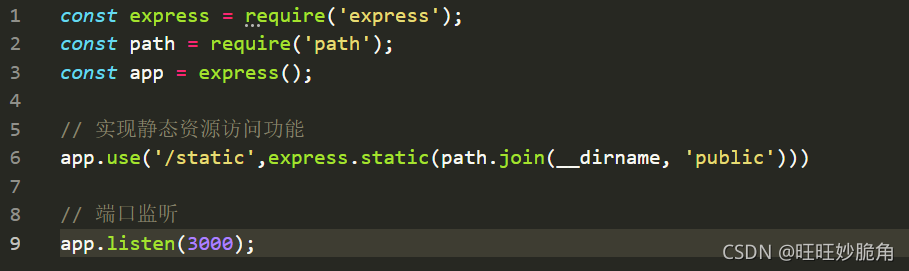
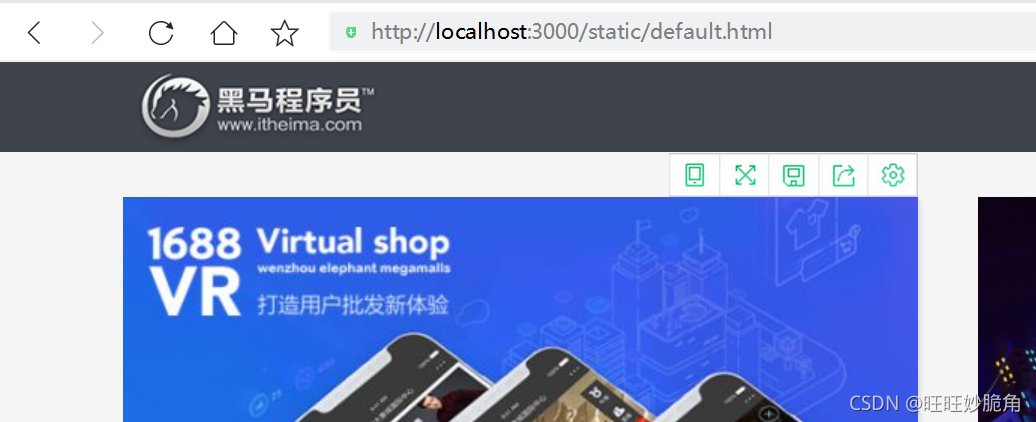
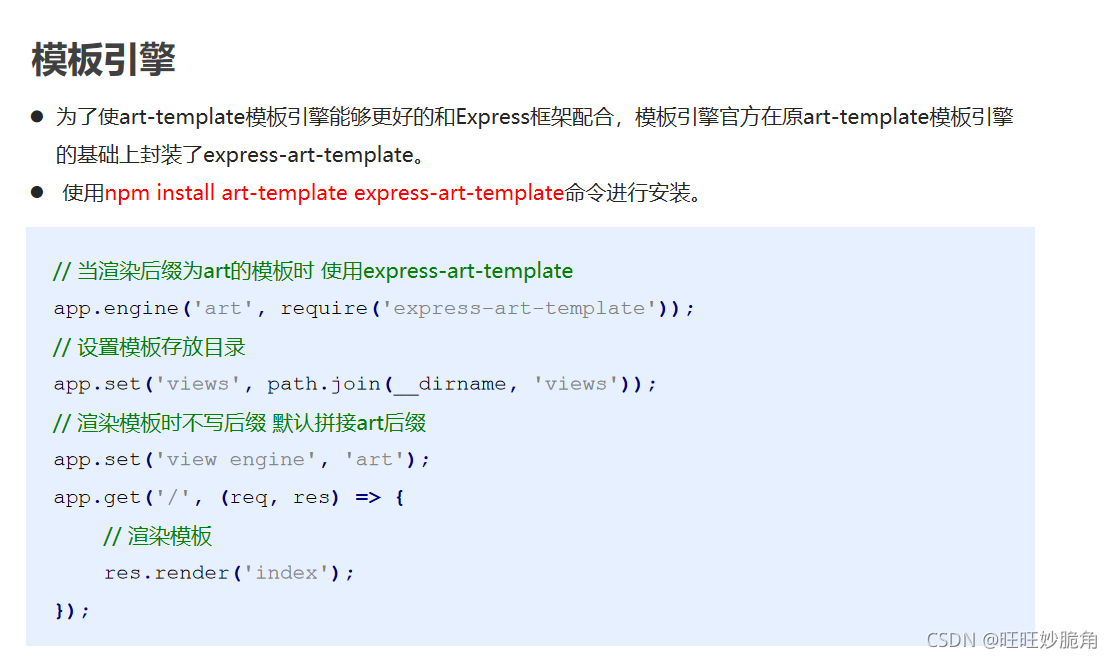
在express框架中去配置模板引擎
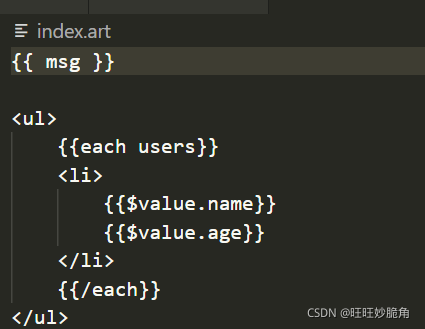
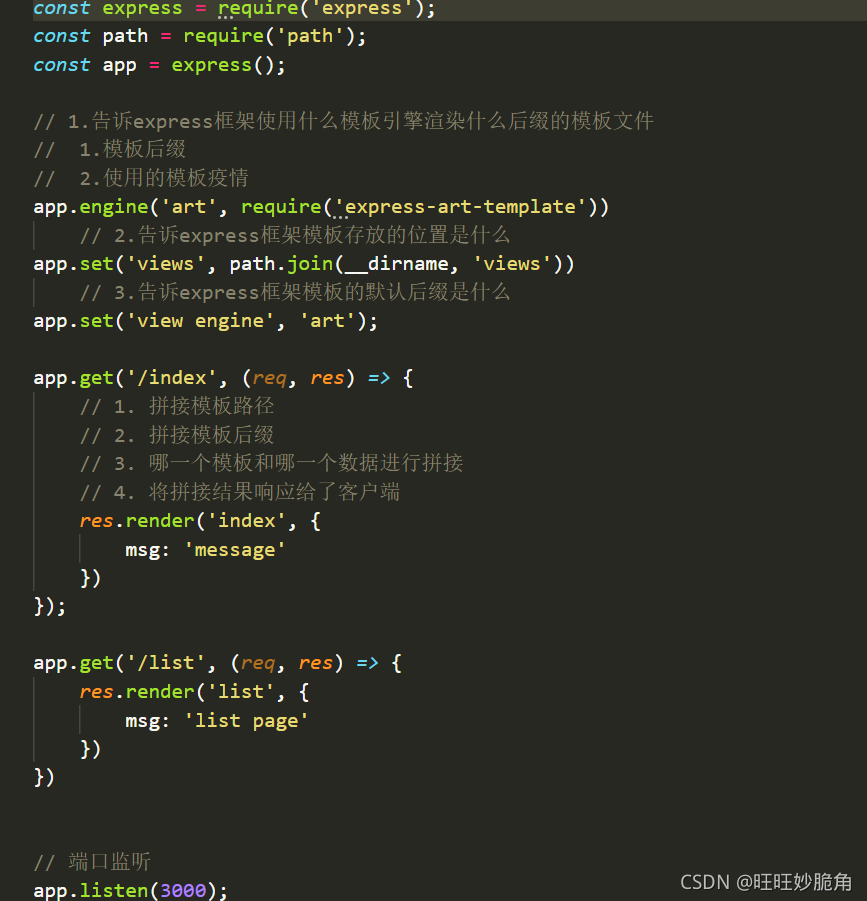

项目中的公共数据添加到app.locals

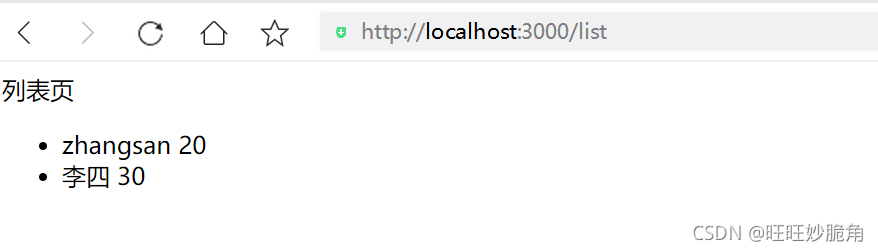
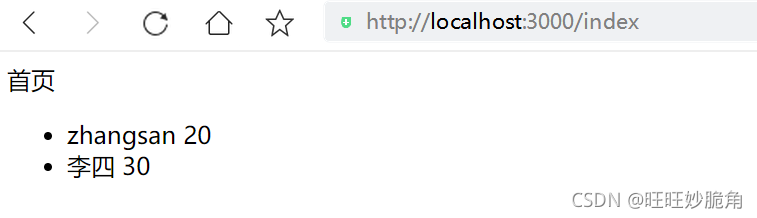

















 172
172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









