





从经典的SGDSGDSGD算法到如今备受瞩目的AdamAdamAdam算法,这一段发展历程不仅是技术的演进,更是人类智慧与机器智能深度交融的生动写照。
今天,就让我们深入探讨SGDSGDSGD和AdamAdamAdam的数学原理,分析其在实际应用中的优缺点,为神经网络训练中优化算法的选择提供参考依据。
一、随机梯度下降(SGDSGDSGD)算法
随机梯度下降(SGDSGDSGD)算法是神经网络优化的基础算法之一,其核心思想是通过随机选择一个样本或一个小批量样本,计算损失函数在这些样本上的梯度,从而近似整个数据集的梯度,进而更新模型参数。
这种方法不仅减少了计算量,还提高了训练速度,使得SGDSGDSGD在处理大规模数据集时尤为高效。
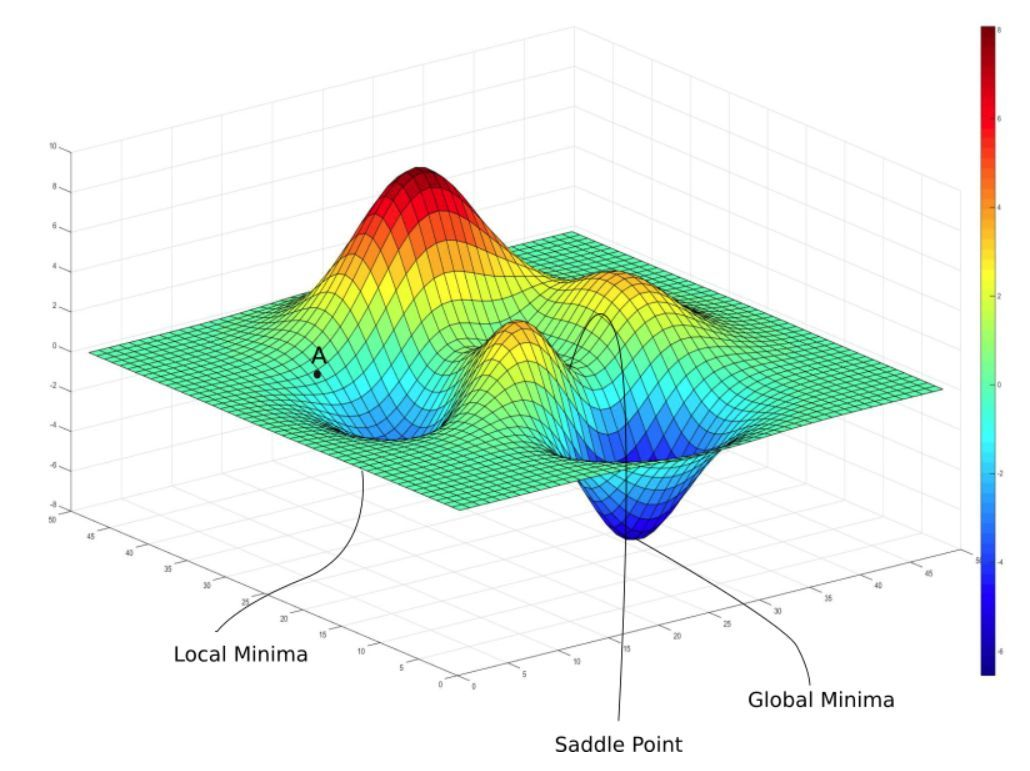
SGDSGDSGD的原理是基于梯度下降法,通过迭代更新参数,逐步逼近损失函数的最小值。其更新公式为:
θt+1=θt−η∇θL(θt;xi,yi)\theta_{t+1} = \theta_t - \eta \nabla_{\theta}L(\theta_t; x_i, y_i)θt+1=θt−η∇θL(θt;xi,yi)
其中,η\etaη 是学习率,θt\theta_tθt 是第 ttt 次迭代的参数,∇θL(θt;xi,yi)\nabla_{\theta}L(\theta_t; x_i, y_i)∇θL(θt;xi,yi) 是在样本 (xi,yi)(x_i, y_i)(xi,yi) 上计算的梯度。
SGDSGDSGD通过这种方式,利用随机性引入的噪声帮助模型跳出局部最小值,从而在某些情况下能够找到更优的全局最小值。
SGDSGDSGD的简单高效的特点使其在早期神经网络训练中得到了广泛应用,尤其是在数据量较大且模型复杂度较高的场景下,SGDSGDSGD能够有效地加速训练过程,提高模型的收敛速度。
SGDSGDSGD的收敛性分析是其理论研究的核心内容之一,其收敛性主要取决于学习率的选择和梯度的稳定性。
理论上,SGDSGDSGD在满足特定条件下能够收敛到损失函数的全局最小值或局部最小值。对于凸优化问题,SGDSGDSGD在合适的学习率设置下可以收敛到全局最小值。
具体来说,如果学习率满足以下条件:
∑t=1∞ηt=∞和∑t=1∞ηt2<∞\sum_{t=1}^{\infty} \eta_t = \infty \quad \text{和} \quad \sum_{t=1}^{\infty} \eta_t^2 < \inftyt=1∑∞ηt=∞和t=1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1049
1049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









