



 该论文探讨了一种利用标准目标检测方法检测图像中对象间关系的新方法。通过将关系检测任务分解为连续对象检测任务,论文提出了BAR-Net,它首先检测所有对象,然后对每个对象使用第二个检测器来寻找与其有交互的对象。关键创新在于引入了'box attention',即使用对象框作为二进制掩模输入到检测器中。在实现过程中,为了简化,论文修改了概率表示形式,并利用三个通道的掩模来处理空和非空情况。训练过程包括复制图像并分配不同的掩模和对象标签,以处理不可见对象的关系。最终,通过前向过程计算triplet分数,实现关系的精确识别。
该论文探讨了一种利用标准目标检测方法检测图像中对象间关系的新方法。通过将关系检测任务分解为连续对象检测任务,论文提出了BAR-Net,它首先检测所有对象,然后对每个对象使用第二个检测器来寻找与其有交互的对象。关键创新在于引入了'box attention',即使用对象框作为二进制掩模输入到检测器中。在实现过程中,为了简化,论文修改了概率表示形式,并利用三个通道的掩模来处理空和非空情况。训练过程包括复制图像并分配不同的掩模和对象标签,以处理不可见对象的关系。最终,通过前向过程计算triplet分数,实现关系的精确识别。
BAR-Net(google AI work in progress,待更新)
文章
主要是想用标准的object detection方法进行pair-wise的relationship的检测。将relation检测的任务,分解为了检测两个consecutive的object的任务。Paper提出先用一个detector将图中所有的object检测到,然后对于每一个object,利用第二个detector检测与之有interaction的object。在第二步时,还需要将第一步得到的object的box,作为binary的mask输入到第二个detector。
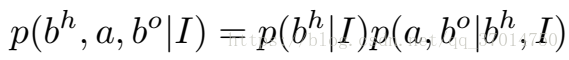
Paper将relation的检测任务,解耦成上式两个概率相乘。b^h代表human的box,第二个概率将其和image作为condition,以binary mask的形式输入,这种输入,paper就称之为box attention。
但是在具体实现时,paper认为使用两个不一样的detector过于cumbersome,因此改写了第一项概率的形式为:
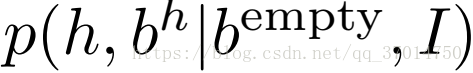
这样一来,两个概率都有了相同概率形式,不过第一个的box attention为empty,总的architecture可以用下图表示
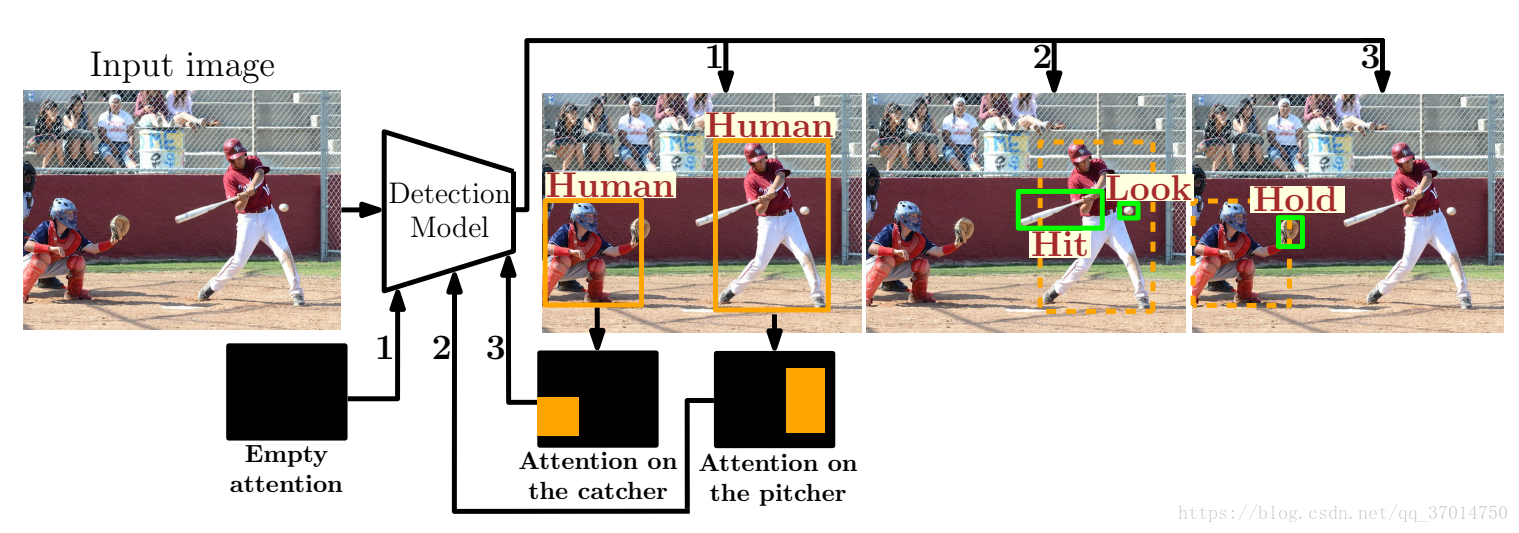
一个有意思的点是mask的设置,paper提出的mask有3个channel,分两种情况设置,1)非empty,第1个channel按普通mask设置,box部分为1,其余为0,然后第2个channel都为0,第3个channel都为1;2)empty,第1个channel全部为0,第2个channel全部为1,第3个channel又全部为0。Paper这样做的motivation是他们认为,由于感受野的问题,许多神经元不能分辨到底mask是否为empty,因此需要直接利用输入告诉他们,具体就体现就在了2,3channel的值。
对于原本detector的每个卷积层的输出u,假设其尺寸为HxWxK,将mask缩放到相同的尺寸,然后利用1x1xK的卷积使mask的通道数也变为K,得到mask的信息m,将u+m输入到下一层。每层都进行这样的操作。
训练步骤:对每张input image,假设其有k个human,先将其copy为k+1份,每张copy有自己的mask和object,一份copy的mask为empty,对应的object则为所有的human,其它的每个mask为一个human的box,对应的object则为与之interact的object。并且每个object都有一个action标签。
Paper有考虑一个比较特殊的情况,就是有时候与human有relation的object是看不见的,这时候将其bbox用和human相同的box代替。
前向过程:首先输入empty mask和原图,得到human的box,然后对于每个human,每次输入human的box mask和原图,检测与之interact的object,每个object有类别向量,也有action向量。最后的triplet分数为

这就是前面概率的分解形式。


















 1138
1138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









