







 这篇博客介绍了如何结合目标检测网络和注意力输入(attentionmap)来识别图像中的主语、宾语和谓语。attentionmap是一个二值图像,用于引导模型关注特定区域。训练时,通过复制图像并附加不同的attentionmap生成多个训练样本。测试时,首先检测主语,然后利用主语bbox生成新的attentionmap,再次输入模型以检测宾语和谓语。博主分享了这一方法的实现细节,并提及了个人生活琐事,如看电影和返校心情。
这篇博客介绍了如何结合目标检测网络和注意力输入(attentionmap)来识别图像中的主语、宾语和谓语。attentionmap是一个二值图像,用于引导模型关注特定区域。训练时,通过复制图像并附加不同的attentionmap生成多个训练样本。测试时,首先检测主语,然后利用主语bbox生成新的attentionmap,再次输入模型以检测宾语和谓语。博主分享了这一方法的实现细节,并提及了个人生活琐事,如看电影和返校心情。
这篇论文的思想也挺简单的:目标检测网络+box attention input

那么,attention map又是什么呢?
attention map是与原图像大小相同,channel为3的二值图,第一维channel表示的是图像上的主语bbox。如果第一维是empty,第二维就是全1,第三维就是全0。如果第一维不是empty就倒过来。
把attention map加到目标检测网络也很简单:
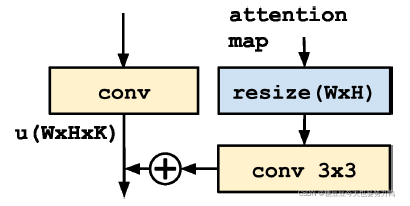
训练时:
如果一张图片里有k个主语,那么首先把这张图片复制k份,每一份附上主语的attention map,同时与这个主语相关的宾语及谓语作为gt,这是k个训练样本。再把这张图片复制一份,附上empty attention map,同时全部主语作为gt,这是第k+1个训练样本。
测试时:
先输入图片和empty attention map到模型中,输出主语bbox和主语类别。再从主语bbox中提取attention map,再输入一次模型,就得到与主语相关的宾语的bbox、宾语和谓语类别。然后将主谓宾三者的置信度相乘,分数最高就是最终的结果了。
------------------------------------一些碎碎念---------------------------------------
今天大师兄已经回实验室了QAQ
我不想那么早回去
我还想再苟苟嘤。
后天去看这个杀手不太冷静
这总不能踩雷了吧。
---------------------------2022.02.14-------------------------
补个影评 真的好好看
学校延迟返校了
现在心情就是比较纠结
又想早回又不想早回。

















 8661
8661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









