



 本文介绍了Shuffle-Then-Assemble方法,旨在训练出一个对对象不敏感的CNN,减少关系对特定对象的偏见。通过对抗式训练,该方法使用预训练的CNN和随机初始化的OA卷积层,结合转移G和F以及判别器D_A和D_B,促进特征提取逐步变得object-agnostic。实验结果显示,即使不进行微调,OA模块也能提高基线性能,并且注意力更集中在主题和对象重叠的区域。
本文介绍了Shuffle-Then-Assemble方法,旨在训练出一个对对象不敏感的CNN,减少关系对特定对象的偏见。通过对抗式训练,该方法使用预训练的CNN和随机初始化的OA卷积层,结合转移G和F以及判别器D_A和D_B,促进特征提取逐步变得object-agnostic。实验结果显示,即使不进行微调,OA模块也能提高基线性能,并且注意力更集中在主题和对象重叠的区域。
Shuffle-Then-Assemble
文章
Paper认为标记triplet的cost是很大的,而且人标记的relation有很强的的object的依赖性,就是某些relation对某些object-object会有bias。
shuffle-then-assemble的目的是希望训练出一个比较object agnostic的CNN,这样就能缓解relation对object的bias。
作者的基本思路是先用普通的pretrained的CNN网络连接上随机初始化的OA conv layer,然后利用domain transfer和discriminator进行对抗式的训练,最终达到使CNN提取的特征变得object-agnostic为止。

关于shuffle-and-assemble模块的具体实现,主要是下面的结构和损失函数:


具体的步骤是:每次将要训练的ground truth triplet先进行拆分,将object分为两个一样大的集合A和B。然后利用transfer G和F分别对A和B里的每一个特征进行transfer,然后利用D_A,D_B进行fake和real的判断。理想的Discriminator应该是:
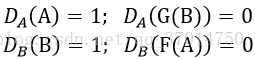
也即D能区分domain原有的特征,和转换到domain的特征,上面的对抗项中不同的max和min就是为了一边使得discriminator更强,一边使得F,G的transfer能力更强,最终的结果就是能够让前面的特征提取慢慢的变得object-agnostic。
有一个要注意的点是,为了发掘更多的组合,要避免一个domain向另一个domain转换时,出现大量重叠的现象,比如多个不同的A domain中的特征,它们的F(a)却很相似,这是不好的(虽然我还没弄懂为啥不好,文章是这样说的)。
因此paper定义了一个loss:
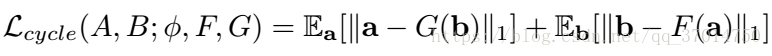
我感觉这个loss的意思就是,鼓励转换前后的差距尽可能小。
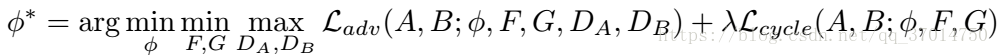
上式就是最后的shuffle-and-assemble的损失函数。
实验结果表明,OA模块训练好后即便不finetune,结果也比baseline好,毕竟参数多了嘛。同时有趣的是,加入OA后的feature map会更多地关注subject和object重叠的地方。


















 1069
1069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









