




 本文记录了一次使用MX150 GPU进行目标检测模型训练的过程,包括遇到的问题、调试方法及最终效果。因样本标签不足导致模型无法有效收敛,通过调整参数和改进样本质量提升训练效果。
本文记录了一次使用MX150 GPU进行目标检测模型训练的过程,包括遇到的问题、调试方法及最终效果。因样本标签不足导致模型无法有效收敛,通过调整参数和改进样本质量提升训练效果。
清早起来神清气爽,想着今天要解决昨天那个不知道如何解决的问题就很惆怅,明明学习率也调小了,batch-size也调小了,为何一直报错了,打开电脑,再一次输入指令,想着记录一下错误类型:
python train.py --logtostderr --train_dir=training/ --pipeline_config_path=training/ssd_mobilenet_v1_coco.config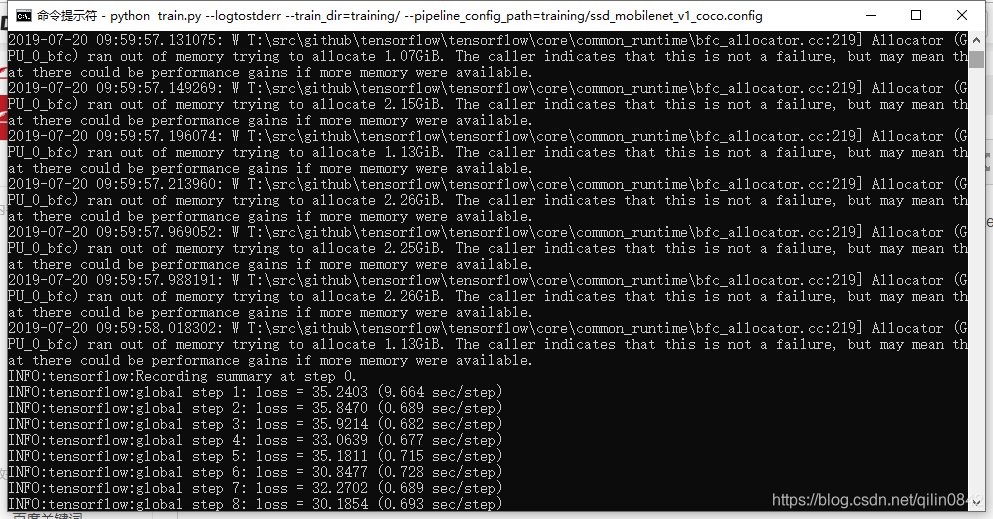
没想到,这么触不及防的就跑起来了 。。。
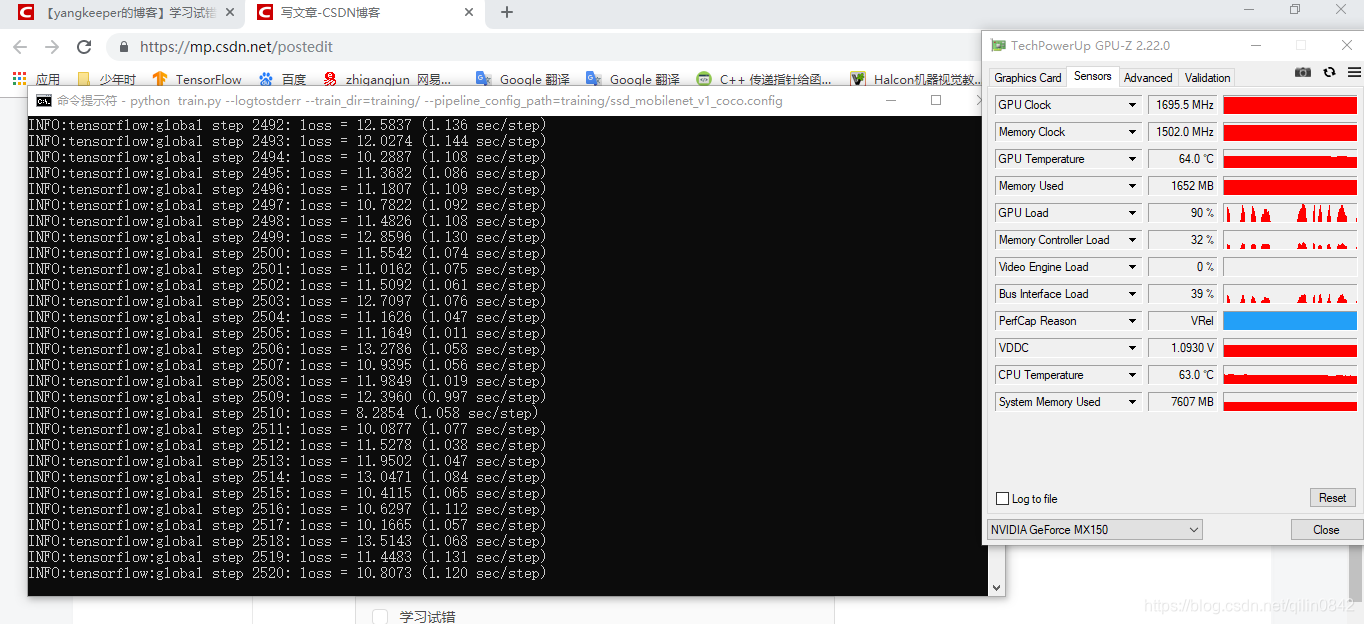
查看gpu,发现果然这次现存没炸,难道是之前因为训练之前就耗用了太多gpu显存没有释放吗? 总之先跑着,看看会不会收敛先。
MX150,现存为2g,速度较之cpu快乐将近十几倍,不过在跑了3000步后却一直在14-10之间波动,不能收敛,目前总结最大的原因是标签样本太少(我只做了一百多的train样本,且标签做的不认真),后续试试这个显卡能承受的batch-size和lr,然后忍着改好样本标签,进行正式的训练。
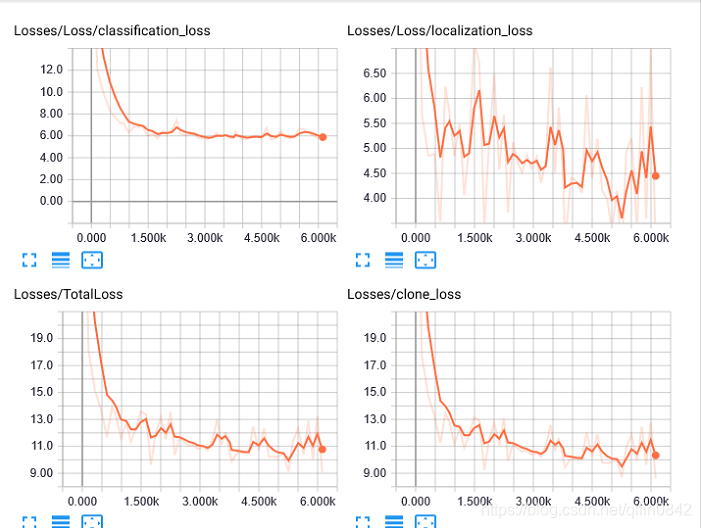
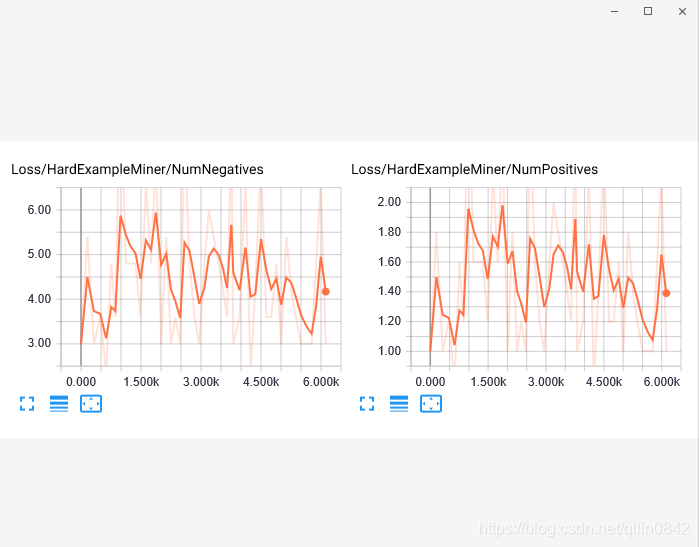
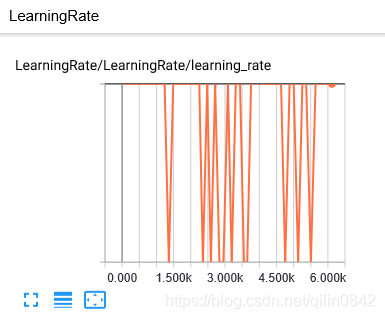
调参及神经网络学习参考:https://blog.youkuaiyun.com/mzpmzk/article/details/80136958
https://www.jianshu.com/p/0b116c43eb16
https://www.jianshu.com/p/a0009ec5225e
https://www.cnblogs.com/ya-cpp/p/9205552.html
最后结果由于样本太少,标签做的太烂:
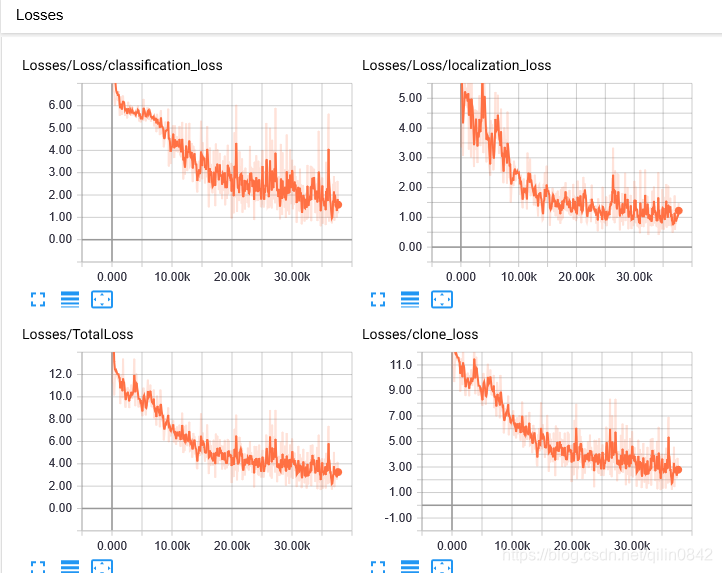
只能收敛到这个程度了,看看效果
cmd路径到object_detection输入:
python export_inference_graph.py --input_type image_tensor --pipeline_config_path training/ssd_mobilenet_v1_coco.config --trained_checkpoint_prefix training/model.ckpt-37476 --output_directory inference_graph37476为自己训练的次数,需修改。此步将训练的文件转化为pb文件,
--trained_checkpoint_prefix training/model.ckpt-37476 这个checkpoint(.ckpt-后面的数字)可以在training文件夹下找到你自己训练的模型的情况,填上对应的数字(如果有多个,选最大的)。
--output_inference_graph 改成自己的名字,会生成一个文件夹。
运行完后,可以在该文件夹下发现若干文件,有saved_model、checkpoint、frozen_inference_graph.pb等。 .pb结尾的就是最重要的frozen model了。
然后报错:
TypeError: non_max_suppression() got an unexpected keyword argument 'score_threshold'
参考:https://github.com/EdjeElectronics/TensorFlow-Object-Detection-API-Tutorial-Train-Multiple-Objects-Windows-10/issues/133可能是tensorflow版本的原因,更新为1.9:pip install --upgrade tensorflow-gpu==1.9
更新后,转化为pb文件成功,试试效果:


效果很差,汗~后续好好做标签,扩展样本吧,可以试试数据增强或者迁移学习~

















 1370
1370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









