






本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/BCqvesmqdQTF6dRQQVOPag
精简阅读版本
本文主要解决了什么问题
-
1. 缺乏处理大规模非英语数据的根本性数据管理方法:现有尝试要么不对原始非英语图像文本对进行管理,要么依赖专有和私有数据源。
-
2. 多语言诅咒问题:在全局范围(英语+非英语)数据上训练的CLIP模型的英语性能劣于仅使用英语数据训练的模型。
-
3. 英语与非英语数据之间的性能权衡:现有方法无法同时优化英语和非英语性能,需要使用不同模型分别优化。
-
4. 英语互联网数据即将耗尽:需要扩展到全球网络数据以实现下一级别的扩展。
本文的核心创新是什么
-
1. 全局元数据构建:将英文MetaCLIP元数据扩展至维基百科和多语言WordNet上的300+种语言,为每种语言维护独立的元数据。
-
2. 全局策展算法:构建针对每种语言的子字符串匹配与平衡机制,引入语言特定的阈值t_lang,确保所有语言中的尾部概念比例相同。
-
3. 全局模型训练框架:
-
• 多语言文本分词器(XLM-V表现最佳)
-
• 缩放已见训练对:将已见对数量按非英语对数据规模的增长比例进行扩展
-
• 最小可行模型容量研究:发现ViT-H/14是打破多语言诅咒的拐点
-
-
4. 无过滤器理念:移除Pipeline中的最后一个过滤器(替代文本是否为英文),实现更好的多样性并最小化过滤器引入的偏见。
结果相较于以前的方法有哪些提升
-
1. 英语性能提升:MetaCLIP 2 ViT-H/14在零样本ImageNet分类中比其仅英语版本提高0.8%(从80.5%提升至81.3%),比mSigLIP提高0.7%。
-
2. 多语言性能显著提升:
-
• 在CVQA达到57.4%
-
• 在Babel-ImageNet达到50.2%
-
• 在XM3600图像到文本检索中达到64.3%
-
• 在Flicker-30k-200上提升7.7%/7%
-
• 在XTD-200上提升6.4%/5.8%
-
-
3. 打破多语言诅咒:通过精心设计的元数据、数据管理、模型容量和训练,英语和非英语数据之间的性能权衡消失,两者变得相互促进。
-
4. 文化多样性提升:在地理多样化的基准数据集(如Dollar Street、GeoDE和GLDv2)上执行零样本分类和少样本地理定位时,使用全局数据显著提升了性能。
局限性总结
-
1. 模型容量要求高:研究发现ViT-L/14模型仍然受到多语言诅咒的影响,需要更大的ViT-H/14模型才能打破这一诅咒,增加计算资源需求。
-
2. 语言识别(LID)的局限性:LID覆盖的语言集合和元数据来源通常不同,需要建立映射关系,可能引入不精确性。
-
3. 元数据覆盖不均衡:不同语言的元数据质量和覆盖范围可能存在差异,特别是对于资源较少的语言。
-
4. 训练批次大小增加:为了保持英语已见对的数量不变,需要将全局训练批次大小放大2.3倍,增加训练的复杂性和资源需求。
深入阅读版本
导读
对比语言图像预训练(CLIP)是一种流行的基础模型,支持从零样本分类、检索到多模态大语言模型(MLLMs)的编码器。尽管CLIP在来自英语世界的数十亿规模图像-文本对上成功训练,但要进一步扩展CLIP的训练以从全局网络数据中学习仍然具有挑战性:(1) 没有现成的策展方法来处理非英语世界的数据点;(2) 现有多语言CLIP的英语性能不如其仅英语版本,即LLMs中常见的“多语言诅咒”。在此,作者提出MetaCLIP 2,这是首个从零开始使用全局网络规模图像-文本对训练CLIP的方案。为了推广作者的发现,作者进行了严格的消融实验,仅对解决上述挑战所必需的最小改动进行操作,并提出了一种能够从英语和非英语世界数据中获益的方案。在零样本ImageNet分类中,MetaCLIP 2 ViT-H/14比其仅英语版本提高了0.8%,比mSigLIP提高了0.7%,并且令人惊讶的是,在多语言基准测试(如CVQA达到57.4%,Babel-ImageNet达到50.2%,以及XM3600在图像到文本检索中达到64.3%)上,没有系统级混杂因素(例如翻译、定制架构变更)的情况下,设定了新的最先进水平。
代码和模型:https://github.com/facebookresearch/MetaCLIP
1 引言
对比语言图像预训练(CLIP)(Radford等人,2021年)已成为现代视觉和多模态模型的关键构建模块,从零样本图像分类和检索到作为多模态大语言模型(MLLM)(Grattafiori等人,2024年;Team等人,2023年;Liu等人,2023年;Bai等人,2023年)中的视觉编码器。CLIP及其大多数变体(Ilharco等人,2021年;Xu等人,2024年)采用纯英文设置,而MetaCLIP(Xu等人,2024年)引入了一种可扩展的数据策展算法,以精心提取一个包含Common Crawl中长尾概念的十亿规模英文数据集。该算法将原始互联网的分布转换为由元数据(例如由人类专家组成的视觉概念)定义的可控和平衡的训练分布,而训练分布已知是性能的关键贡献者之一。相比之下,流行的CLIP复制品将这种关键贡献者外包给外部资源,例如在LAION(Schuhmann等人,2021年,2022b)上训练的OpenCLIP(Ilharco等人,2021年)和依赖预训练CLIP模型进行黑盒过滤以仅保留高置信度数据的DFN(Fang等人,2023年)。这些方法类似于现有CLIP教师模型的蒸馏,并产生由外包方拥有的难以追踪的分布。
尽管作为最广泛使用的"基础"模型,大多数CLIP变体(包括可扩展的MetaCLIP)依赖于仅英语的策展,从而舍弃了其他语言,例如全局网络数据中50.9%(维基百科,2025年)的非英语数据。为了将CLIP训练和数据扩展到全局网络以实现下一 Level 的扩展,作者不可避免地必须处理这些非英语的图像文本对,作者将其称为全局扩展挑战,这是在数年尝试在多语言数据上训练CLIP后仍未解决的问题。
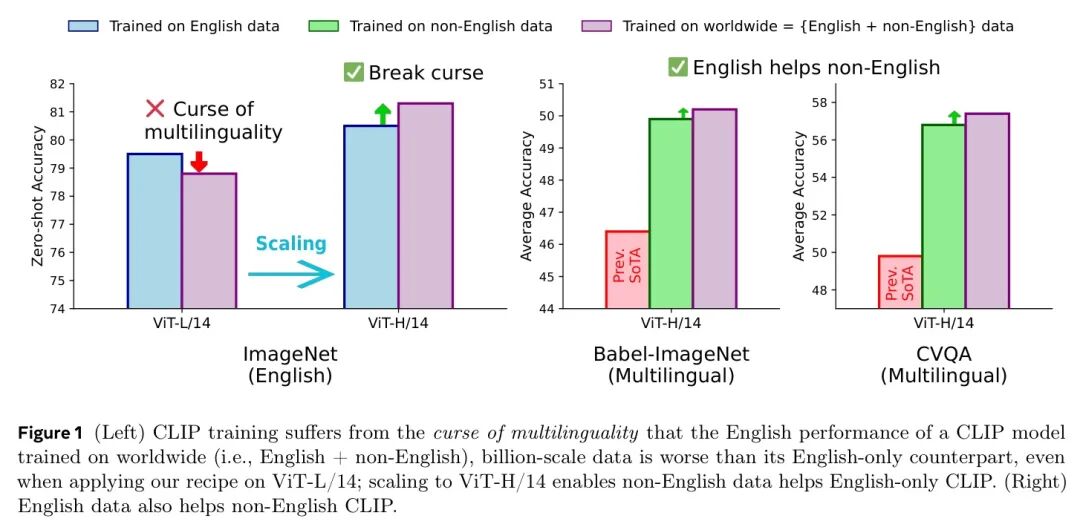
图1(左)CLIP训练受到多语言诅咒的影响,即在一个全局范围(即英语+非英语)的十亿规模数据上训练的CLIP模型的英语性能,甚至在使用MetaCLIP-2在ViT-L/14上训练时,也劣于仅使用英语数据训练的模型;而扩展到ViT-H/14并加入非英语数据,则有助于仅使用英语数据训练的CLIP模型。 (右)英语数据也有助于非英语CLIP模型。
挑战#1:缺乏处理大规模非英语数据的根本性数据管理方法。现有尝试要么完全不对原始非英语图像文本对数据进行管理(例如,从英语CLIP(Chen等人,2023a)或机器翻译(Carlsson等人,2022;Nguyen等人,2024)中提取),要么依赖专有和私有数据源(例如,WebLI(Chen等人,2023b)驱动了mSigLIP和SigLIP 2(Zha)等人,2023;Tschannen等人,2025),后者基于Google图像搜索(Juan等人,2019)。
挑战#2:英语性能不如纯英语CLIP。这也被称为文本仅大语言模型(LLMs)的多语言诅咒。例如,mSigLIP在ImageNet上比其纯英语版本SigLIP差1.5%(Zhai等人,2023年),而SigLIP 2(Tschannen等人,2025年)优先考虑英语性能,代价是比mSigLIP更差的多语言结果。因此,必须使用不同的模型来同时优化英语和非英语性能。
这项工作。作者提出了MetaCLiP 2,这是首个通过在本土全局图像-文本对上进行从头训练来开发CLIP的食谱,不依赖于外包资源,如任何私有数据、机器翻译或蒸馏。作者通过实证表明,CLIP中的多语言诅咒是因缺乏合适的全局数据管理和模型训练食谱而导致规模不足的结果。当元数据、数据管理、模型容量和训练得到精心设计和联合扩展时,作者不仅表明英语和非英语数据之间的性能权衡消失,而且两者变得相互促进。实现这种全局规模扩展是非常有必要的,尤其是在英语互联网数据即将耗尽时(Villalobos等人,2022)。
作者的MetaCLIP 2方案建立在英文MetaCLIP之上,其中与OpenAI CLIP的纯架构重叠被有意最大化。这种重叠使得作者的发现可推广至CLIP及其变体,而相比之下,旨在通过组合所有可用技术实现最先进(SoTA)性能的系统工作则涉及混杂因素或对外包资源的比较,而非CLIP本身。
MetaCLIP 2方案引入了三项原则性创新以扩展至全局范围:
-
1. 元数据。作者将英文MetaCLIP元数据扩展至维基百科和多语言WordNet上的300+种语言。
-
2. 筛选算法。作者构建了针对每种语言的子字符串匹配与平衡机制,以筛选非英文数据的概念分布,类似于英文对应部分。
-
3. 训练框架。作者设计了首个全局规模的CLIP训练框架,包括在训练过程中增加与新增非英文数据示例规模成正比的可见图像-文本对,并研究了最小可行模型容量以从全局规模数据中学习。
如图1所示,尽管OpenAI使用的最大模型尺寸ViT-L/14仍受多语言诅咒的影响,但ViT-H/14打破了这一诅咒。英文准确率在ImageNet上从80.5%提升至81.3%,并且令人惊讶的是,通过最少的CLIP架构变更,新SoTA在多语言图像-文本检索任务中设定了新纪录:ΔXM3600 64.3%,Babel-ImageNet 50.2%,CVQA 57.4%。MetaCLIP 2通过其本质实现了以下理想结果:
-
1. 英文与非英文世界的互惠。非英文数据现在能更好地支持纯英文模型,反之亦然,这在英文数据枯竭的时代至关重要。
-
2. 全多语言支持。MetaCLIP 2不会仅因语言差异而丢弃图像-文本对,并产生了优于所有先前多语言系统(如mSigLIP和SigLIP 2)的模型。
-
3. 母语监督。模型直接从母语者撰写的替代文本中学习,而非合成机器翻译。
-
4. 文化多样性。MetaCLIP 2保留了全局图像的完整分布,从而继承了(Pouget et al., 2024)所倡导的全面文化和经济社会覆盖范围。这种覆盖范围提高了地理定位和区域特定识别能力。
-
5. 无过滤器理念。随着面向全局数据的筛选算法设计,MetaCLIP 2移除了 Pipeline 中的最后一个过滤器(即替代文本是否为英文),实现了更好的多样性并最小化过滤器引入的偏见(Pouget et al., 2024)。
-
6. 对基础数据更广泛的影响。这项工作提供了全局规模的图像-文本对基础数据集,不仅惠及CLIP,也受益于使用CLIP数据的工作,如MLLM、SSL和图像生成(DALL-E和扩散模型)。
2 相关工作
2.1 CLIP的演进及其数据处理
CLIP(Radford等人,2021年)及其变体(Jia等人,2021年;Iharco等人,2021年;Zhai等人,2023年)学习通用的图像和文本表征,这些表征通常对下游任务有用(Grattafiori等人,2024年;Dai等人,2023年;Liu等人,2023年)。这种多模态对比学习和Transformer架构已成为视觉和多模态研究中的标准组件。数据是CLIP性能的关键贡献因素(Gadre等人,2023年;Xu等人,2024年)。针对CLIP数据的两种主要处理方法出现:从头开始的数据策展,以及从外部资源中提取。一个关键区别在于前者能产生更可控的分布,而后者则拥有外包方无法控制的分布。
从零开始进行数据策展。OpenAI CLIP(Radford等人,2021年)从零开始策展了一个包含4亿个图像-文本对的训练数据集,并公开了High-Level策展指导原则。MetaCLIP(Xu等人,2024年)将OpenAI的指导原则作为正式的策展算法,并将策展规模扩展到25亿对。该算法是无模型的,没有黑盒过滤,完全透明,能够完全基于公共数据源进行训练,其中数据分布经过策展以与人类专家组成的元数据(例如WordNet和维基百科)保持一致。
从外部资源中进行蒸馏。基于蒸馏的方法通常具有良好的性能,并通过从教师模型中学习知识来节省计算资源(Hinton等人,2015)。然而,在CLIP训练的上下文中,教师通常是一个外部黑盒系统,这引入了难以追踪的偏差。例如,LAION-400M/5B(Schuhmann等人,2021,2022a)(由OpenCLIP(Ilharco等人,2021)使用)依赖于OpenAI CLIP-flter和DFN(Fang等人,2023),后者使用一个在高质量私有数据上训练的过滤模型(Ranasinghe等人,2023)。最近,SigLIP(Zhai等人,2023)和SigLIP 2(Tschannen等人,2025)从数据源WebLI(Chen等人,2023b)中学习,该数据源源自Google图像搜索(Juan等人,2019)。
2.2 视觉编码
CLIP风格的模型在多模态语言模型(MLLM)中被广泛用作视觉编码器,其中CLIP训练中的语言监督有助于学习紧凑且语义丰富的视觉表示。相比之下,传统的视觉表示学习基于自监督学习(SSL)方法,如SimCLR(Chen等人,2020)、DINOv2(Oquab等人,2024),完全依赖于完整的视觉信号,不受语言偏差影响。存在一些结合两者的变体。SLIP(Mu等人,2021)结合了语言和SSL监督;LiT(Zhai等人,2022)先训练视觉编码器,然后进行语言对齐;Perception Encoder(Bolya等人,2025)表明CLIP表示的早期层产生的视觉驱动特征具有较少的语义对齐。最近,Web-DINO(Fan等人,2025)表明SSL在MetaCLIP精选的大规模数据上具有更好的可扩展性。总之,CLIP专注于人类对齐的表示,优化紧凑模型和高效的下游应用;SSL模型旨在作为通用预训练方法保留所有视觉信息。作者预期这两条研究路线将因互补性而产生更多协同效应。
2.3 多语言CLIP模型
由于缺乏针对全局公共数据的开源管理,多语言CLIP模型的初始尝试主要采用蒸馏方法。M-CLIP(Carlson等人,2022)和mCLIP(Chen等人,2023a)仅利用现有的英文专用CLIP作为视觉编码器,并使用低质量的多语言对训练多语言文本编码器。为整合非英文数据,后续研究(Santos等人,2023;Nguyen等人,2024;Pouget等人,2024)借助机器翻译技术,将非英文标题翻译成英文或反之。这些基于蒸馏的模型在非人类标注数据上带有现有的英文CLIP偏差或翻译偏差。mSigLIP(Zhai等人,2023)通过利用WebLI(Chen等人,2023b)的多语言数据大幅提升了多语言性能,而WebLI是一个未公开的数据集,其构建基于私有数据处理流程而非公开的全局数据管理算法。
然而,mSigLIP和其他多语言CLIP模型受到多语言诅咒的影响,例如,mSigLIP在ImageNet上的准确率比仅使用英语的SigLIP低1.5%。最近,SigLIP 2采用了明显以英语为中心的设计,其90%的数据为英语,这一比例远高于mSigLIP。在将SigLIP从WebLI的10B原始数据扩展到100B时,在英语基准测试中也观察到混合结果(Wang等人,2025),这表明扩展WebLI面临的挑战。
3 MetaCLIP 2 配方
MetaCLIP-2将CLIP扩展到本土全局数据并训练,包括三个步骤,如图2所示:(1)构建全局元数据,(2)实施全局策展算法,(3)构建全局模型训练框架。为了实现可推广的方法和发现,MetaCLIP 2设计为最大限度地与OpenAI CLIP和MetaCLIP重叠,并且仅采用必要的变化以从全局数据中学习。
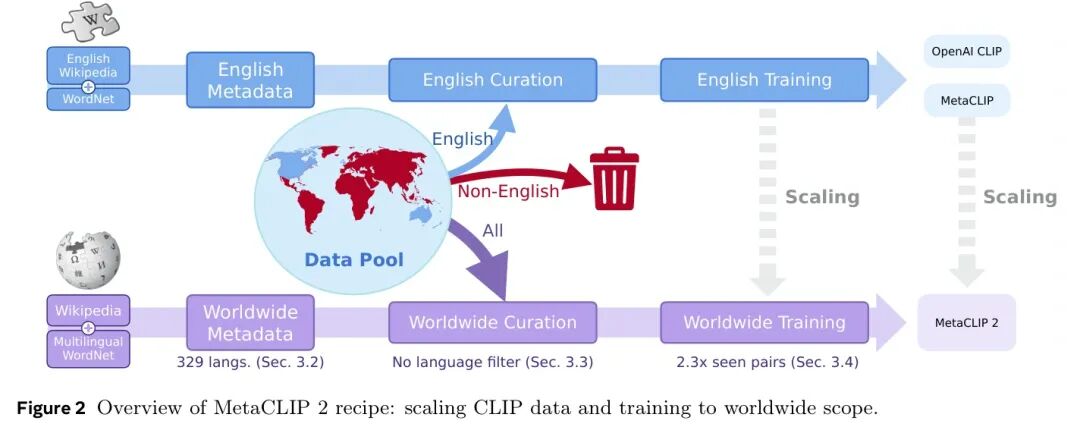
图2 MetaCLIP 2方案概述:扩展CLIP数据并训练至全局范围
3.1 MetaCLIP算法的重新审视

3.2 全局元数据
作者通过构建缺失的元数据来应对全局扩展的首要挑战,以覆盖非英语世界。作者为每种语言维护独立的元数据,因为这种设计直观(例如,同一个词"mit'"在英语和德国有不同的含义),性能更优(参见第4.2.2节的消融实验),并且为未来添加和整理新的语言集提供了灵活性。

3.3 策展算法
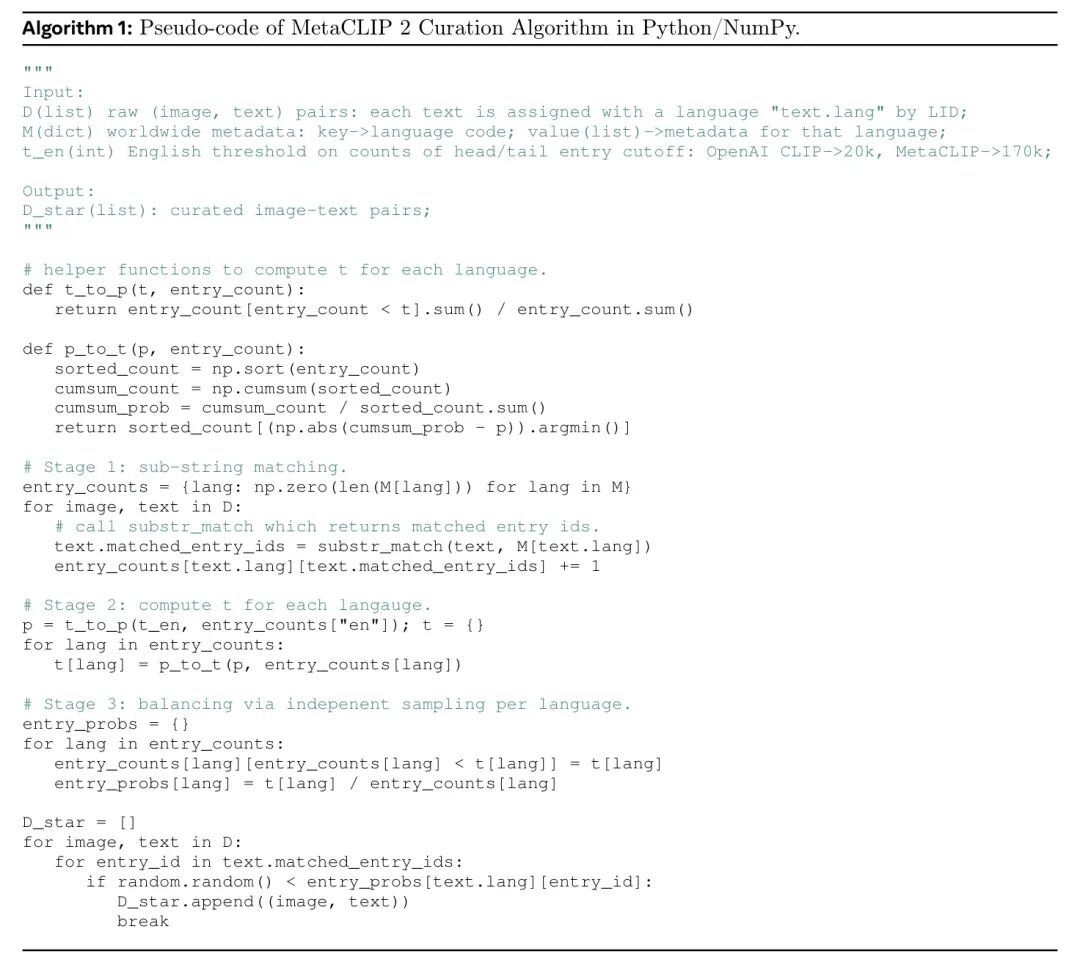
接下来,作者将数据策展扩展到全局范围,按语言逐个进行。数据策展算法的详细描述如下,并以伪代码形式总结为算法1。首先,作者进行语言识别(LID)(Grave等人,2018),用于对图像-文本对中的替代文本进行语言分类,并选择特定语言的元数据以匹配概念。LID覆盖的语言集合和元数据来源(例如维基百科)通常不同,因此作者首先建立LID中的一种语言与元数据条目中唯一语言集合之间的映射。映射到LID中相同语言的元数据被合并为一组。最终得到元数据M的字典表示,其中键是LID中的每种语言,值是每组语言的组合元数据。作者还包含一个键"other",用于无法与LID中任何语言关联的元数据。中的每个替代文本(text)都应用LID以预测其语言(text . 1ang)。之后,与第3.1节中总结的MetaCLIP算法类似,作者对预测语言的元数据运行子串匹配:matched_ent ry_ids = substr_match (text, M[text.1ang]),并在entry_counts中聚合全局计数globalcount,即每个条目的匹配次数。

3.4 训练框架
采用当前CLIP训练框架中经过全局范围策展的数据解决了第一个挑战,但多语种的诅咒问题依然存在,如图1所示。因此,作者进一步设计了全局范围的CLIP训练框架。为了使MetaCLIP-2和研究成果具有通用性,能够适用于CLIP及其变体,MetaCLIP-2遵循OpenAI/MetaCLIP的训练设置和模型架构,并增加了三项改进:(1)多语言文本分词器,(2)缩放已见训练对,以及(3)最小可行模型容量的研究。第一项是为了支持全局语言,并在第4.2.2节中讨论了各种选择;后两项的详细内容将在下文描述。
扩展已见图像文本对。从仅包含英语的数据集和分布扩展到全局范围,自然地增加了可用图像文本对的数量。使用与英语CLIP相同数量的已见对来训练面向全局的CLIP会下采样英语训练对,从而损害英语性能。因此,作者将已见对的数量按非英语对数据规模的增长比例进行扩展,以确保在全局CLIP训练过程中英语已见对的数量保持不变。这是通过增加全局训练批次大小来实现的,这鼓励了跨语言学习,同时保持其他训练超参数不变。作者选择将全局批次放大2.3倍,以反映英语对占作者训练数据的44%。作者在第4.2.1节中消融了其他全局批次大小的选择。
最小可行模型容量。最后,作者研究了最小模型表达能力,以实现对新见数据对的泛化学习并打破多语言诅咒。如图1所示,作者发现即使是OpenAI提供的最大模型ViT-L/14也因容量不足而受到诅咒的影响,而ViT-H/14是打破诅咒的拐点(英语和非英语任务中均表现出显著的性能提升)。
4 实验
4.1 数据集与训练设置
遵循MetaCLIP流程,作者从互联网收集公开可用的图像-文本对。经过LID处理后,大约有的替代文本为英文,这与MetaCLIP仅包含英文数据的规模相当(Xu等人,2024)。为了获得具有泛化能力的配方和发现,作者的训练设置基于OpenAI CLIP的ViT-L/14和MetaCLIP ViT-H/14,除了在Sec. 3.4中描述并在后续小节中排除的使能全局功能所需的变更。详细信息可参见表6和附录B。

4.2 评估
作者首先在广泛的英语和多语言零样本迁移基准上展示了MetaCLIP 2的主要消融实验结果,并与其他多语言CLIP Baseline 进行比较(第4.2.1节);然后作者对元数据、数据筛选和分词器的变体进行了全面的消融研究(第4.2.2节)。最后,作者在文化多样性下游任务上评估了MetaCLIP 2的嵌入质量(第4.2.3节)。此外,作者在第4.2.4节对嵌入对齐和一致性进行了分析(Wang and Isola, 2020)。
4.2.1 主要消融实验
作者首先消融了缩放效应、训练样本对以及最小可行模型容量对打破多语言诅咒的影响,通过以下两组6次训练运行。两组训练分别是在ViT-L/14上使用全局精选数据和其英文部分,其中全局批大小和已见样本对分别设置为OpenAI CLIP和MetaCLIP设置的2.3倍和1.0倍(即1.0倍包含128B已见样本对,或32个epoch对应400M,与OpenAI CLIP设置相同)。另外四次运行是在ViT-H/14上使用精选数据的不同子集,以展示英文数据对多语言性能的影响以及反之亦然的效果。作者根据训练子集和相应的已见样本对对每次运行进行 Token :1)全局(2.3倍)使用完整的全局精选数据;2)全局(1.0倍)使用1)下采样后的数据;3)英文(1.0倍)使用1)的英文部分;4)非英文(1.3倍)使用非英文部分。
作者采用以下两组零样本迁移基准:1) 仅英语的ImageNet (IN val)基准 (Russakovsky等人,2015),SLIP 26任务 (SLIP 26平均) (Mu等人,2021),以及DataComp 37任务 (DC 37平均) (Gadre等人,2023);2) 多语言基准Babel-ImageNet (Babel-IN) (Geigle等人,2024) (在ImageNet上平均零样本分类,类别和 Prompt 翻译成280种语言),xM3600 (Thapliyal等人,2022) (多语言文本到图像,T-I,和图像到文本,I→T,检索,平均Recall@1在36种语言上),cvQA (Mogrovejo等人,2024) (多语言选择题视觉问答,英语和局部平均答案准确率),Flickr30k-200 (Visheratin,2023) (Flickr30k测试集翻译成200种语言),xTD-10 (Aggarwal和Kale,2020) (在MSCOCO (Chen等人,2015)上的多语言图像文本检索,平均Recall@1在7种语言上),以及xTD-200 (Visheratin,2023) (XTD10翻译成200种语言)。主要消融实验结果如表1所示。作者观察到,MetaCLIP 2在ViT-H/14上使用全局数据和扩展的已见对,在英语和多语言任务上始终优于其对应英语(1.0×)和非英语(1.3×)版本,有效打破了“多语言诅咒”。在非扩展的已见对中,诅咒仍然存在,即使是全局数据(2.3×)或更小的ViT-L/14模型。
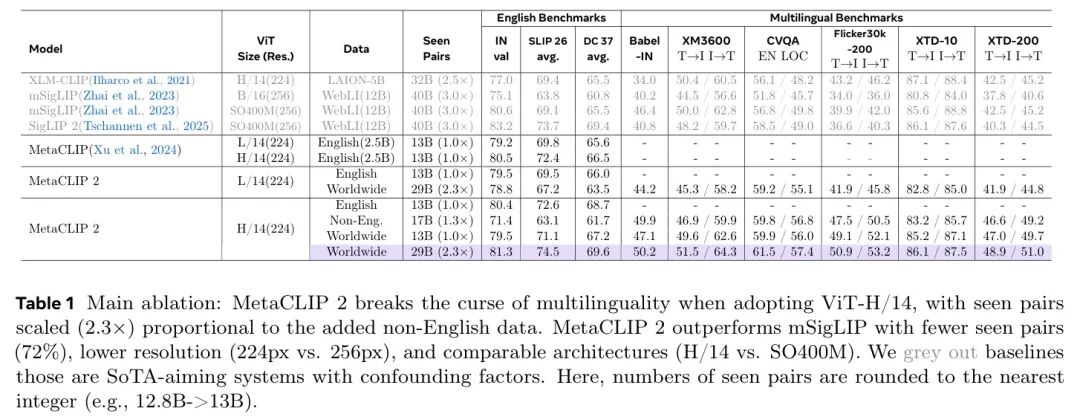
表1 主要消融实验:当采用ViT-H/14时,MetaCLIP 2打破了多语言诅咒,已见数据对比例(2.3倍)随着非英语数据的增加而扩展。MetaCLIP 2在已见数据对较少(72%)、分辨率较低(224px vs. 256px)以及架构相当(H/14 vs. SO400M)的情况下优于mSigLIP。作者灰显那些具有混杂因素、以SOTA为目标系统的 Baseline 。此处,已见数据对的数值四舍五入到最接近的整数(例如,12.8B- 13B)。
尽管SoTA不是MetaCLIP 2的目标,但其完整配方在更少的已知对(SigLIP系列的72%)和更低分辨率(224px对比mSigLIP的256px)的情况下表现出色。MetaCLIP 2在IN、SLIP 26和DC 37上超越了mSigLIP,并在最近的SigLIP 2上超越了后两者。更重要的是,MetaCLIP 2设定了多个SoTA多语言基准,例如Babel-IN(+3.8%)、XM3600(+1.1%/+1.5%)、CVQA(+3%/+7.6%)、Flicker-30k-200(+7.7%/+7%)和XTD-200(+6.4%/+5.8%)。SigLIP 2优先考虑英语(其训练数据的90%为英语),但在多语言任务上不如mSigLIP,在大多数英语基准上(除IN外)也不如MetaCLIP 2。
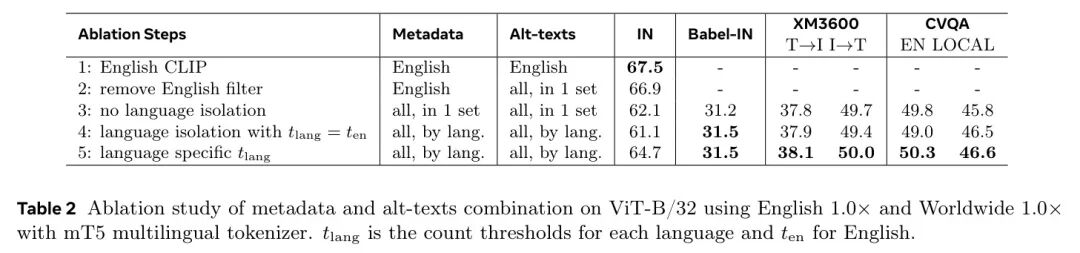
表2 元数据和替代文本组合在ViT-B/32上的消融研究,使用英语和全局以及mT5多语言分词器。是每种语言的计数阈值,是英语的阈值。
4.2.2 元数据、策展和分词器的消融实验
作者进一步消融了元数据和策展过程从仅关注英语到其全局对应物的转变,使用ViT-B/32编码器以提高效率。作者在英语和babel-in、XM3600以及CVQA上评估了零样本迁移。如表2所示,从仅英语的CLIP开始,作者首先移除alt-texts上的英语过滤器,以便所有alt-texts都由英语元数据策展,导致IN上下降0.6%,表明在匹配前由LID将文本或元数据分离的英语隔离非常重要。
然后,作者使用未经分离合并的所有元数据替换英文元数据,从而导致英文性能进一步恶化,但开始构建多语言能力。接下来,作者隔离子串匹配,并逐语言整理替代文本,所有语言使用相同的 。这进一步降低了英文性能,因为 对于非英文来说过高,导致 Head 数据主导整理过程。最后,作者计算 ,以保持每种语言的 Head 到尾部概念的相同比例。这提升了英文和非英文的性能,但多语言诅咒在ViT-B/32上仍未解决,直到上述主要消融实验。
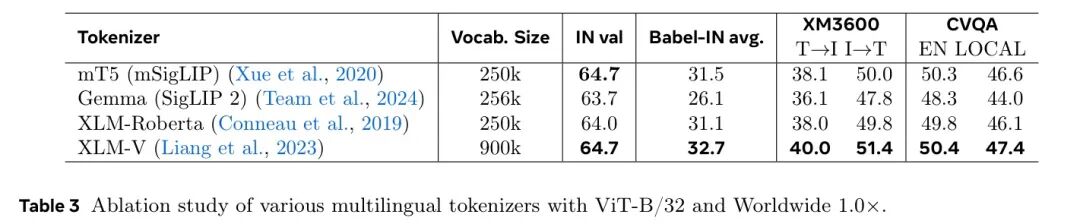
为最小化模型架构的改动,作者仅将英语分词器替换为多语言分词器。在零样本基准测试中研究了四种流行的分词器。如表3所示,XLM-V词汇表在英语和非英语领域均表现出最佳性能。
4.2.3 文化多样性
遵循Pouget等人(2024)和Wang等人(2025)的协议,作者在一系列地理多样化的基准数据集上执行零样本分类和少样局部理定位。具体而言,作者在表4中包含了使用Dollar Street(Gaviria Rojas等人,2022)、GeoDE(Ramaswamy等人,2023)和GLDv2(Weyand等人,2020)的零样本分类,并在图3中展示了在Dollar Street、GeoDE和XM3600上的少样局部理定位(Pouget等人,2024)。作者发现,仅将训练数据分布从13B英文对改为13B全局对即可显著提升性能,而扩展到29B全局对则进一步提升了性能,除了GeoDE中性能相当、可能已饱和的表现。图3在评估少样局部理定位时显示了类似的趋势。
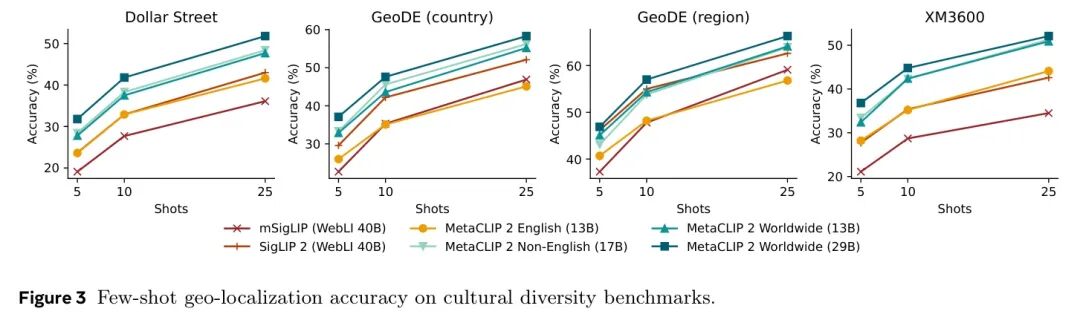
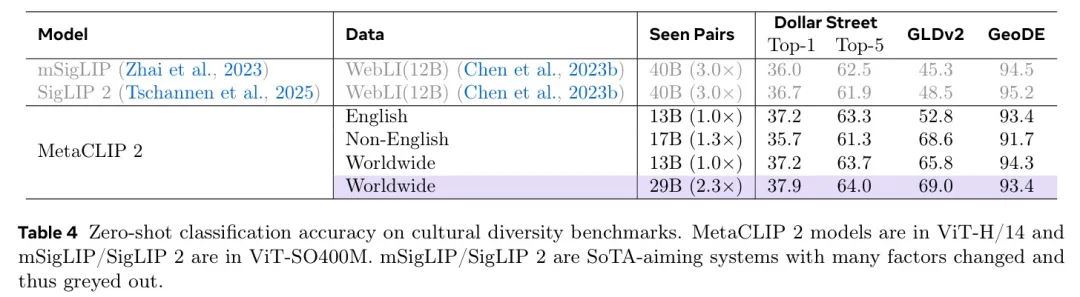
图3 在文化多样性基准上的小样局部理定位准确率
4.2.4 对齐和一致性
遵循 (Wang and Isola, 2020) 的方法,作者进一步测量了不同CLIP模型中嵌入的质量。为避免来自不同基准的各种未知偏差,作者使用了5k个未用于训练的图像-文本对,并报告了对齐和一致性分数,其中对齐度量图像和文本的相关性,一致性度量图像在视觉编码器嵌入空间中的分布情况。请注意,作者无法控制这5k对是否在其他 Baseline 中被泄露。从图4可以看出,MetaCLIP 2在对齐和一致性方面均表现出良好分数(越低越好),而mSigLIP或SigLIP 2可能在作者收集的保留数据上存在非平凡的偏差。
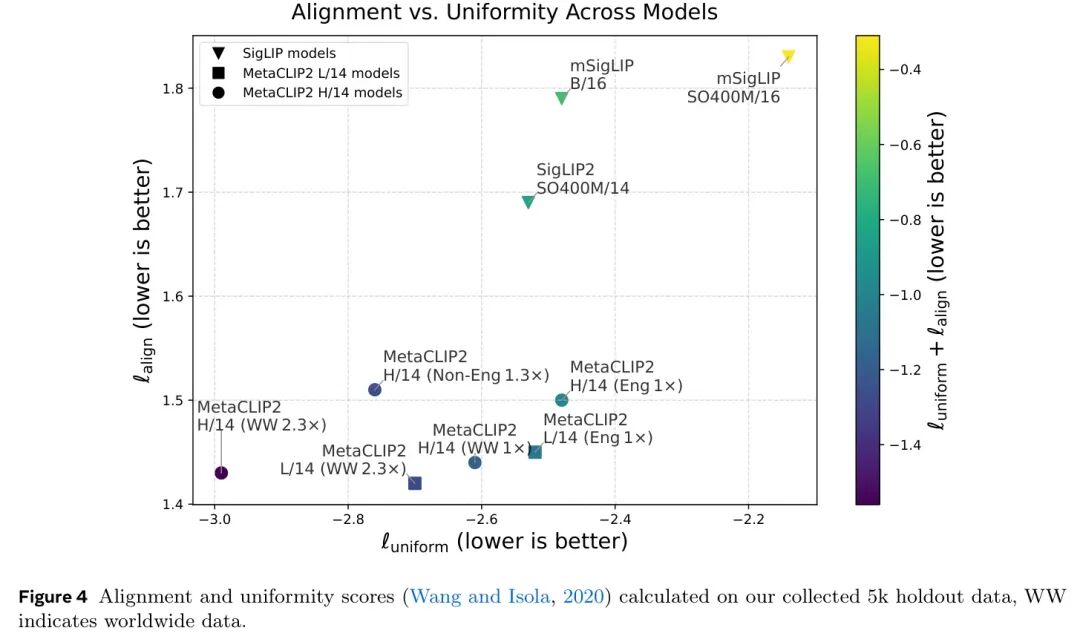
图4 对作者收集的5k验证数据计算的排列和一致性分数(Wang and Isola,2020),WW表示全局数据。
5 结论
作者介绍了MetaCLIP 2,这是首个从零开始使用全局图像-文本对训练的CLIP模型。现有的CLIP训练流程主要针对英语设计,若缺乏对全局数据的筛选或受到“多语言诅咒”的影响,无法直接推广到全局范围而不牺牲英语性能。作者的细致研究表明,通过扩展元数据、筛选和训练能力,可以打破这一诅咒,使英语和非英语世界相互受益。具体而言,MetaCLIP 2(ViT-H/14)在零样本IN上超越了仅使用英语的同类模型(性能从80.5%提升至81.3%),并使用单一模型在XM3600、Babel-IN和CVQA等多语言基准上创下了新的SOTA(State-of-the-Art)记录。作者期望作者的研究成果连同完全开源的元数据、筛选和训练代码,能够鼓励社区超越以英语为中心的CLIP,拥抱全局多模态网络。
参考
[1]. MetaCLIP 2: A Worldwide Scaling Recipe
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 1501
1501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









