



Table of Contents
事实上,确实得老老实实听取查到的资料的话...在用头铁的不依照各位老哥们的话依旧用VS2010去配置tensorflow C++API的三天里饱受煎熬,转为2015后果然很流畅的就配置好了呢~所以其实前面一直试错、改错其实收获还是挺大的嘛,后续遇到的问题基本瞬间就解决了。
参考
基本上参考了这位大神的步骤:
【Tensorflow】Windows以cmake+visual studio方式编译cpu版tensorflow.dll和tensorflow.lib
【Tensorflow】Windows以cmake+visual studio方式编译gpu版tensorflow.dll和tensorflow.lib
【Tensorflow】Windows下用tensorflow C++接口调用pb模型文件进行预测
准备
visual studio 2015 update 3(必须要,没有的可以去下载补丁更新一下,官网有)
git(用于从github上down东西下来,推荐架梯子,或者也可以自己下载再放入相应路径下)
Cmake v3.6.3
python3.6或python3.5
tensorflow r1.8(https://github.com/tensorflow/tensorflow/tree/r1.8)
swigwin
CUDA、cudnn
修改CMakeLists.txt
修改tensorflow/contrib/cmake/CMakeList.txt,将
if (tensorflow_OPTIMIZE_FOR_NATIVE_ARCH)
include(CheckCXXCompilerFlag)
CHECK_CXX_COMPILER_FLAG("-march=native" COMPILER_OPT_ARCH_NATIVE_SUPPORTED)
if (COMPILER_OPT_ARCH_NATIVE_SUPPORTED)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -march=native")
endif()
endif()
修改为
if (tensorflow_OPTIMIZE_FOR_NATIVE_ARCH)
include(CheckCXXCompilerFlag)
CHECK_CXX_COMPILER_FLAG("-march=native" COMPILER_OPT_ARCH_NATIVE_SUPPORTED)
if (COMPILER_OPT_ARCH_NATIVE_SUPPORTED)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -march=native")
else()
CHECK_CXX_COMPILER_FLAG("/arch:AVX" COMPILER_OPT_ARCH_AVX_SUPPORTED)
if(COMPILER_OPT_ARCH_AVX_SUPPORTED)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} /arch:AVX")
endif()
endif()
endif()文章中在gpu版本下还推荐修改了几个地方,分别是:
set(CUDA_NVCC_FLAGS ${CUDA_NVCC_FLAGS};-gencode arch=compute_30,code=\"sm_30,compute_30\";-gencode arch=compute_35,code=\"sm_35,compute_35\";-gencode arch=compute_52,code=\"sm_52,compute_52\";-gencode arch=compute_61,code=\"sm_61,compute_61\")if (WIN32)
add_definitions(-DGOOGLE_CUDA=1 -DTF_EXTRA_CUDA_CAPABILITIES=3.0,3.5,5.2,6.1)
else (WIN32)
# Without these double quotes, cmake in Linux makes it "-DTF_EXTRA_CUDA_CAPABILITIES=3.0, -D3.5, -D5.2" for cc, which incurs build breaks
add_definitions(-DGOOGLE_CUDA=1 -D"TF_EXTRA_CUDA_CAPABILITIES=3.0,3.5,5.2,6.1")
endif (WIN32)FILE(WRITE ${tensorflow_source_dir}/third_party/gpus/cuda/cuda_config.h
"#ifndef CUDA_CUDA_CONFIG_H_\n"
"#define CUDA_CUDA_CONFIG_H_\n"
"#define TF_CUDA_CAPABILITIES CudaVersion(\"3.0\"),CudaVersion(\"3.5\"),CudaVersion(\"5.2\"),CudaVersion(\"6.1\")\n"
"#define TF_CUDA_VERSION \"64_${short_CUDA_VER}\"\n"
"#define TF_CUDNN_VERSION \"64_${tensorflow_CUDNN_VERSION}\"\n"
"#define TF_CUDA_TOOLKIT_PATH \"${CUDA_TOOLKIT_ROOT_DIR}\"\n"
"#endif // CUDA_CUDA_CONFIG_H_\n"
)此处,添加了计算力为6.1的选项配置,不过考虑到我显卡和系统的渣属性,不敢把计算力提太高就没有加。
Cmake
在../tensorflow/contrib/cmake下新建一个build文件夹,打开cmake-gui
Where is the source code选择:../tensorflow/contrib/cmake
Where to build the binaries选择:../tensorflow/contrib/cmake/build
点击Configure,
选择Visual Studio的版本,点击Finish。
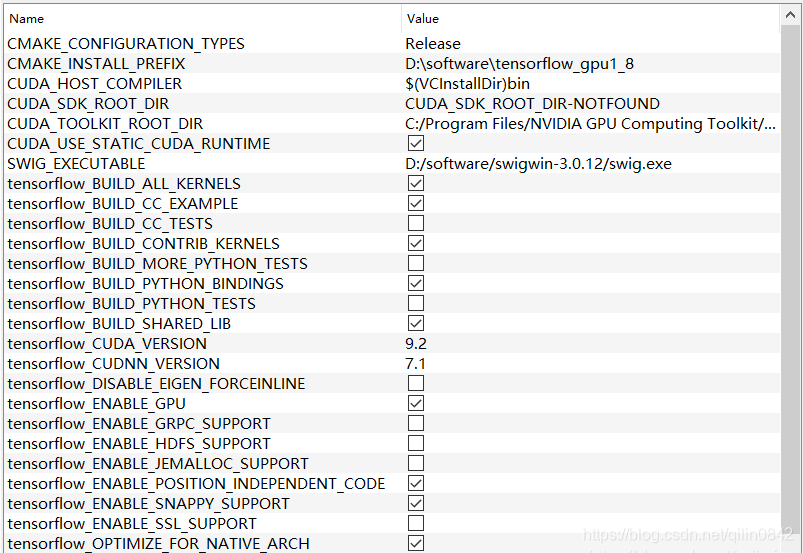
按照自己的需求:
选择编译版本:
修改INSTALL路径(编译后的相关文件会保存于此);
选择SWIG_EXECUTABLE路径;
勾选tensorflow_ENABLE_GPU(GPU版本tensorflow选);
勾选tensorflow_BUILD_SHARED_LIB,取消勾选tensorflow_ENABLE_GRPC_SUPPORT。
注意:在我这第二次点击configure后SWIG_EXECUTABLE就消失了,没关系,查看cmaketxt发现路径已经上传了。
点击Generate,成功不报错即可。
编译tensorflow
打开tensorflow.sln(路径在build/Release或者Debug)。
按照https://blog.youkuaiyun.com/heiheiya/article/details/89242567修改几个工程的配置属性。
注意:我第一次修改完后依旧报错,查询后发现我的该文件不在路径中,文件全局搜索发现在Python某个路径下,拷贝放入路径..\tensorflow\contrib\cmake\build\Release中再生成就没问题了。
还有个小错误,如果是手动下载的tensorflow源代码,记得在根路径上git init一下,否则git会找不到路径
选择项目ALL_BUILD生成。
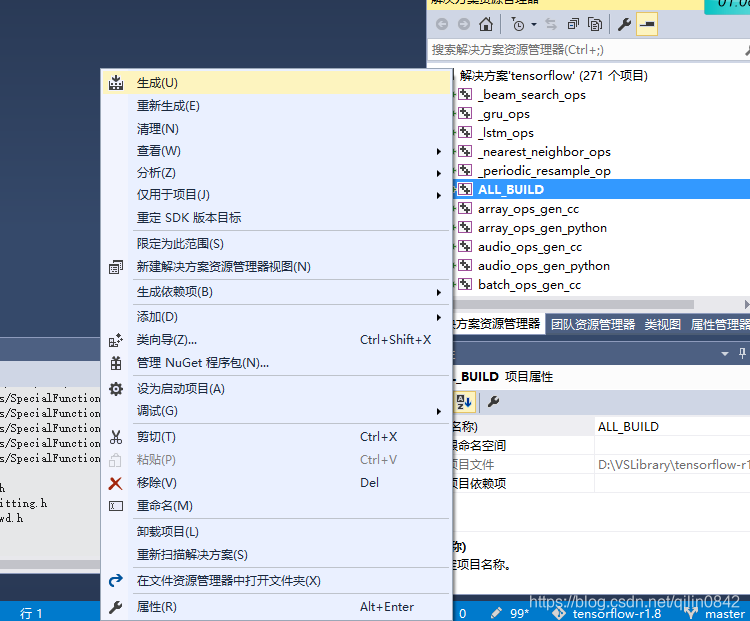
全部生成成功之后,选择生成INSTALL项目,
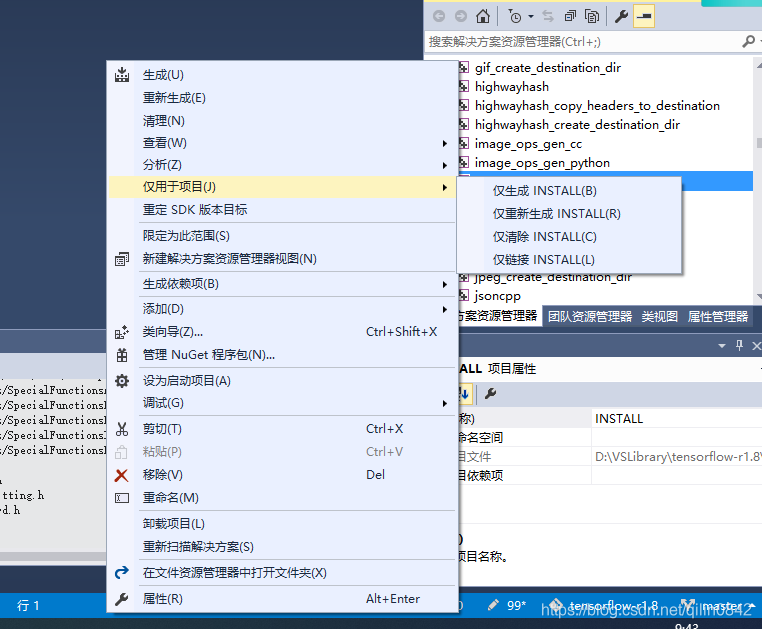
会把相应的bin文件,头文件和库文件拷贝到cmake配置时设置的CMAKE_INSTALL_PREFIX路径下。
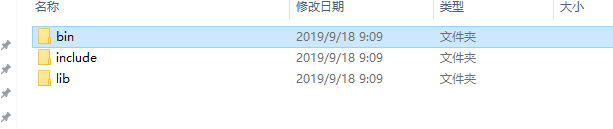
至此,gpu版本的tensorflow dll和lib编译过程结束。
测试
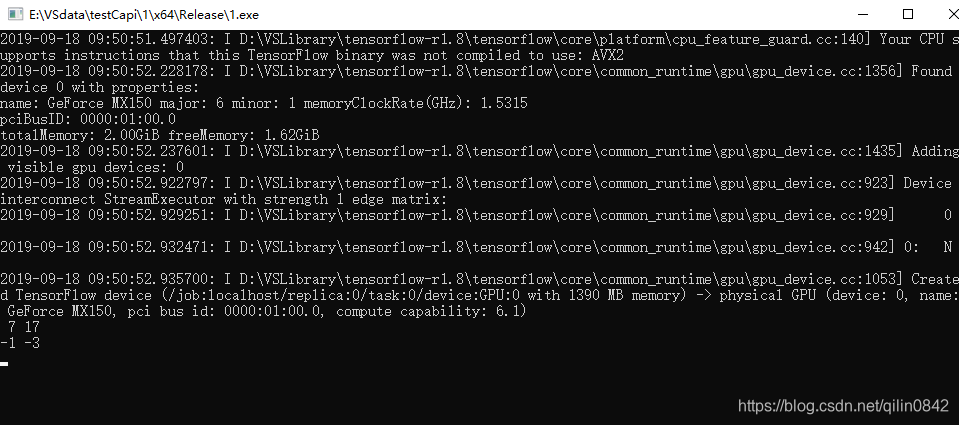
测试一下是否正确编译了,在bin文件夹下有一个tf_tutorials_example_trainer.exe,在cmd中运行它,如果输出类似如下内容,则证明编译是ok的。
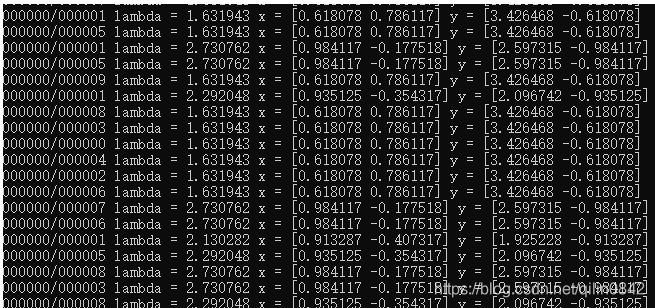
在没有对INSTALL项目单独生成的时候我参考https://www.cnblogs.com/steven_oyj/p/8259205.html进行了tensorflow.dll的测试,
相关过程:
![]()
最后测试结果:
下一步
写代码测试模型的效果,单张测试和batch测试都试试。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









