




SSD系列:
SSD系列1——网络结构
SSD系列2——PriorBox
SSD系列3——损失计算
SSD网络结构概述
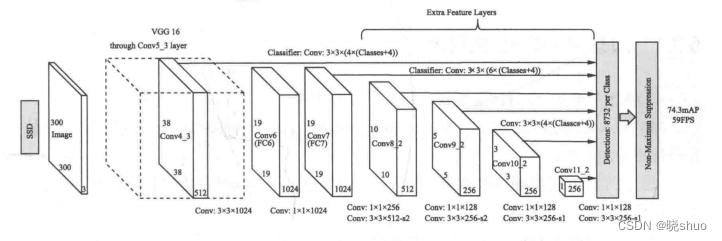
SSD在VGGNet的基础上,增加了4个卷积模块,这些卷积模块获得的特征图具有不同的感受野,可以较好地检测不同尺度的目标。
VGG16
SSD网络使用VGG16作为基础网络,输入图像的尺寸为 300 × 300 × 3 300×300×3 300×
 SSD在VGG16基础上增加卷积模块以检测不同尺度的目标,使用300x300的输入图像,通过改变池化层和应用空洞卷积来维持特征图尺寸并扩大感受野。深层卷积层用于获取更高维度的语义信息,1x1卷积降低通道数后再进行3x3卷积。
SSD在VGG16基础上增加卷积模块以检测不同尺度的目标,使用300x300的输入图像,通过改变池化层和应用空洞卷积来维持特征图尺寸并扩大感受野。深层卷积层用于获取更高维度的语义信息,1x1卷积降低通道数后再进行3x3卷积。
SSD系列:
SSD系列1——网络结构
SSD系列2——PriorBox
SSD系列3——损失计算
SSD在VGGNet的基础上,增加了4个卷积模块,这些卷积模块获得的特征图具有不同的感受野,可以较好地检测不同尺度的目标。
SSD网络使用VGG16作为基础网络,输入图像的尺寸为 300 × 300 × 3 300×300×3 300×

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3万+
3万+







