 Agent三大核心痛点解析
Agent三大核心痛点解析




本文系统解析了AI Agent的三大核心痛点:知识库、工作流和Prompt工程。知识库部分详细介绍了知识收集、整理、存储、检索和更新的方法;工作流部分讲解了任务自动化的流程设计;Prompt工程部分则聚焦于系统提示词设计、示例提供和输出格式规范。这些内容为构建高效可靠的AI Agent提供了实用指导,是开发者必须掌握的关键技术点。
欢迎留言,每条留言都会精选、本人当天回复,文章错误内容也会在回复中更新。本文分为三部分,介绍Agent三大痛点:知识库+工作流+Prompt工程。第一部分是知识库,第二部分是工作流,第三部分是Prompt工程。
正文:
一个好的AI Agent 的大概包括五大组件:
大语言模型 (LLM)是基础计算能力,日趋标准化;工具 (Tools)是能力扩展接口,通过MCP等协议日趋标准化;知识库 (RAG)决定知识深度与专业性,减少模型“幻觉”,是企业知识的载体;工作流 (Workflow)决定处理效率与逻辑,是复杂任务自动化的骨架;提示词 (Prompt)直接决定输出精度,需要深度结合业务场景进行设计。设计精准的提示词、编排可靠的工作流,以及构建和维护高质量的知识库,是设计AI Agent的三大痛点。
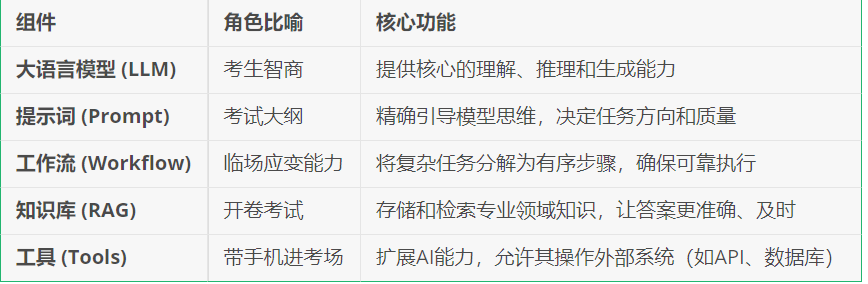
一、知识库
咱们先聊聊知识库怎么建。
1、知识收集
先说知识收集:你手头的PDF、Word、PPT都算"知识原料"。比如你有个眼镜行业的pdf报告,用minerU这种工具一扫,就能把里面内容"扒"出来,变成系统能用的文本。就像你把一堆杂乱的书本整理成电子版,方便以后用。
2、知识整理
知识整理是关键步骤:把内容切成小块,就像切蛋糕一样。可以按章节切,也可以按主题切,或者按固定字数切。切完后,给每块加点"小标签",更方便查找。比如"报告日期"、“关键词”,这样以后找起来特别快。比如一份关于“专利纠纷”的报告,有如下小标签:
标题:海外知识产权纠纷应对策略
3、知识存储
存储方式有讲究:现在主流是存成"向量",就是把文字变成数字向量。这样系统能理解意思,不是死记硬背关键词。比如你问"眼镜行业趋势",系统能知道你问的是"趋势",而不仅仅是匹配"趋势"这个词。下面三种存储方式,对应三种知识检索方式:
-
语义找(语义搜索):存储文本片段的向量表示,理解问题意思,找最相关的。
-
关键词找(全文搜索):找关键词匹配的
-
关联找(图搜索):存储实体及其关系,找相关联的知识
比如问"怎么处理客户投诉",语义找能定位到"客户投诉处理指南",关键词找能精准定位到"投诉处理流程"章节,关联找还能发现"客户服务最佳实践"。
我倾向于采用混合存储架构,即语义搜索+图搜索,对应就要使用向量数据库(Milvus)和图数据库(Neo4j)。分为下面三个步骤:
① 数据模型设计:建一个“人物关系网”+“特征档案库”
想象一下,你要整理一个超级详细的社交网络:Neo4j(图数据库)就像一张巨大的“关系网”,里面记录着每个人(节点)是谁、有什么特点(属性),以及他们之间是什么关系(边)。比如,小明是学生,喜欢编程,认识小红。
Milvus(向量数据库) 则像一个“特征档案库”,不为每个人保存文字描述,而是存储他们的“数字指纹”(向量)。比如,小明的特征可能是 [0.25, 0.8, -0.1, …](计算机能看懂的数字串),代表他的兴趣、能力等。
这样做的好处:以后既能查关系(谁认识谁),也能通过“数字指纹”快速找相似的人(比如都喜欢编程的人)。
② 向量化处理流程:给新信息制作“数字指纹”
当有新资料(如一篇文章)进来时,系统会:
a.预处理:先“拆解”文章,比如分成词或句子,去掉没意义的词(如“的、了”),就像先把食材洗切好。
b.转成向量:用算法(如 BERT)把这些内容变成计算机懂的“数字指纹”(向量)。这就像把一篇文章浓缩成一串特殊的密码数字,其中相似的内容会有相似的密码。
c.同步存储:把这个“数字指纹”存进 Milvus,同时把文章的关键信息(如标题、作者)作为属性存到 Neo4j。这样两边数据能对应上。
③ 索引优化:给数据库加“快速查找目录”
就像书越厚越需要目录,数据多了也要加“索引”来提速:
a.Milvus 里:用类似 HNSW 的算法给“数字指纹”建索引。想象成给所有指纹画一张“地图”,找相似指纹时不用一个个比对,直接按图索骥,快很多。
b.Neo4j 里:给常用查询条件加索引。比如常按“姓名”找人,就给姓名建索引,这样找“小明”就不用翻遍整个数据库。
4、知识检索
举个例子你问“怎么治疗高血压”,首先要快速找到医学指南里的关键词(比如“降压药”),还要理解“高血压”和“心血管疾病”之间的关联(比如并发症),甚至推荐“低盐饮食”这种生活建议。
单纯语义检索可能漏掉“隐性关联”(比如高血压和心脏病的关系),单纯图检索可能找不到“新问题”(比如“新型降压药”在图里没存)。这就需要语义检索(理解意思)和图检索(关联关系)的组合拳,比如先用语义检索找“高血压治疗方法”,再用图检索找“这些方法的副作用”。具体做法:
① 语义检索:像“找相似人”一样找答案
**把文字转成“数字指纹”(向量),通过向量相似度找答案。比如“高血压治疗方法”和“心血管疾病治疗”这两个词组,它们的向量会很接近,系统就能自动关联。**你问“怎么处理客户投诉”,语义检索会匹配“客户投诉处理指南”这类文档,而不仅仅是死磕“投诉”这个词。
② 图检索:像“查人际关系网”一样找答案
**把知识存成“关系网”(节点+边)。比如“高血压”是节点,它和“降压药”“心脏病”“饮食建议”之间有边(关系)。**你问“高血压有哪些并发症?”,图检索能直接跳到“心脏病”“肾病”这些关联节点,还能推荐“低盐饮食”这类关联建议。
③ 辅助检索手段:动态权重和预计算
a.根据问题类型调权重
不是所有问题都适合用同一种检索方式。比如关键词强相关的问题(“诺贝尔奖得主名单”),可以提升关键词权重到0.85,直接匹配“名字”;又比如开放性问题(如“AI的未来趋势”),这时候就提升语义权重,找相似主题的分析报告。在****技术实现上用意图分析模型(比如判断问题类型)即可,实时调整语义和关键词的权重比例。
b.图嵌入向量:让图检索“加速跑”
图检索需要遍历节点和边,速度慢,我们可以通过预计算每个节点的“向量指纹”,存在向量库解决,这在上文中也提到过。举个例子,在社交网络中,先预计算每个人的兴趣向量(比如[0.9, 0.2, 0.7]代表喜欢编程、电影、旅游);接着找“和小明兴趣相似的人”,直接比对向量,不用遍历整个社交关系网。
5、知识排序
排序策略主要包括:
a.多阶段重排序
先用简单算法(如BM25)粗排,再用复杂模型(如交叉编码器)精排
b.上下文排序
结合用户历史行为和实时对话内容,动态调整排序权重
c.规则干预排序
根据业务规则(如安全拦截、时效性要求)进行最终筛选
5、知识更新
知识库就像一个有生命的“知识仓库”,需要持续“保鲜”和“打理”,才能保证里面的信息不过时、不出错。一个好的更新机制能让这个仓库自动或半自动地“补货”和“清货”,减少人工折腾。
① 自动检测变化,触发更新
系统会像“哨兵”一样盯着知识来源(比如文件、数据库),一旦发现变动(如上传了新文档、更新了日志),就自动启动处理流程。这就类似设置了自动提醒,文件一改,后续的解析、存储流程就跟着运转起来。
② 增量更新,只处理“新货”
为了省时省力,不需要每次都把整个知识库重做一遍。而是只处理新加的、或者有变动的部分,原来没动的就直接保留。这就像超市补货,只上新商品,货架上原有的商品不动。
③ 处理版本冲突和矛盾
知识来源多了,不同版本或不同来源的信息可能会有冲突。这时可以:
a.保留历史版本
同一个文件可以有多个版本,系统会标注出来,你可以选择以哪个为主。
b.用元数据标识
在第二部分“知识整理”中,文本切块以后,我们已经加上标签了,我们只需要给文件打上更多标签即可,比如生效时间、失效时间、状态(如“已废弃”)。查询时,系统能通过标签(如状态、时间)自动过滤掉失效或过时的内容,确保你查到的都是“有效货”。
其实,现在更时髦的知识库搭建是微软开发的GraphRag技术栈,但是这个几乎全程都是用大模型实现的,所以我感觉不一定可靠,或者说不像是真正的有价值的算法。有兴趣的话留言,我后面会更新一下哈。
二、工作流
下面是三巨头之二:工作流。
工作流就是Agent的“行动路线图”,规定任务怎么一步步完成。举个例子,你问“明天北京天气”,工作流会自动:
1、先查知识库缓存(如果昨天刚更新过);
工作流为啥关键?没工作流,Agent可能乱成一锅粥(比如先调工具再查知识库,浪费时间)。有了它,复杂任务变流水线——你问啥,它就按顺序搞定,不用你操心。实际上,理想状态下的工作流非常复杂,包括了循环-反思-再行动:用户提问 → 模型判断需要先搜索资料 → 搜索后发现不够 → 再写一段代码解析 → 代码报错 → 模型决定修改代码并重试 → 最终生成答案。这个过程可能会循环很多次,直到任务成功完成。具体循环多少回合,确实无法事先预知。举个HR根据LinkedIn资料招聘的例子:
1. HR输入
- 输入:包含姓名、邮箱的名单 + 需要抓取的字段(如工作经历、技能)。
- 比如:HR上传一个Excel表,里面一行行写着“张三,zhangsan@example.com,需要工作经历和技能”。
2. 生成查询词
- 使用预设的模板(也可以称为Prompt)指导LLM生成LinkedIn搜索词。
- 例子:LLM根据“张三”和“工作经历”生成搜索词“张三 软件工程师”,避免模糊搜索。
3. 爬取数据
- 调用爬虫工具(如Playwright)在LinkedIn搜索该词,抓取目标个人资料页,自动过滤非目标用户(比如同名的人),提取指定字段(如“任职公司A,2020-2023”)。
4. 数据处理与总结
- 再调用另一个LLM,把抓到的碎片信息整理成简洁总结。
- 例子:原始数据是“在公司A做Java开发,公司B做产品经理”,LLM总结为“资深Java开发转型产品管理,擅长技术落地”。
5. 生成个性化消息,再发送
- 根据总结内容生成消息模板,插入用户特定信息,接着通过LinkedIn API或模拟点击工具自动发送消息。
- 例子:
- 原始模板:“Hi [名字],我注意到你曾在[公司]做[职位],对[技能]有深入经验……”
- 替换后:“Hi 张三,我注意到你曾在公司A做Java开发,后转型产品管理,擅长技术落地。我司正在招Java架构师,或许有合作机会?”
由于精力有限,下一篇文章咱们再重点介绍一下Coze工作流的原理,在工作流上,Coze确实是比较成熟可靠的商业化产品了。
三、Prompt工程
最后介绍一下Prompt工程。
Prompt工程就是设计AI的思维操作系统。就像你教一个新员工做事,不能只说"做这个",得告诉他"你是谁、为什么做、怎么做、做成什么样"。
1、系统提示词
① 角色设定
很多人写"你是资深产品经理",结果AI开始讲行业大道理。真正好用的提示词是"你是电商产品文案生成器"。为什么呢?如果是人类专家会思考"为什么",但是机器只会执行"怎么做"。
错的角色设定:"你是资深电商运营专家,擅长写产品文案"
② 上下文
AI是没有常识的,比如:
"你是智能客服,用户问:'为什么我的订单还没发货?'
这样AI才知道"订单已支付但物流状态是’已揽收’,不是没发货",不会答"请等待发货"。
2、Examples:让AI"照着做",不是"猜着做"
写Examples如果只放随便几个例子,AI可能还是胡来。关键不是放例子,而是让AI"学会思考"。通过3个例子,它就记住"这样写是对的"。我在写例子的时候大概有下面几个经验:
① 质量优先:只放正确例子,别放"可能对可能错"的
② 乱序排列:别把对的放一起,错的放一起
③ 覆盖全面:不同场景都要有例子,比如:
正常查询:"手机没电了怎么办?" → "充电5分钟,通话2小时"
④ 不要放过程描述,直接给结果
假设你要AI查库存和物流,如果你这样写example:
你的example :
如果你给AI的example中有"步骤",它就会模仿"步骤",而不是真的去查库存。但是工程系统需要的是结构化数据(比如JSON),而不是步骤说明。下面是正确的example:
你的example:
3、Output Format:让AI老实交作业
光说"输出JSON",AI可能只是给你写段话。必须用"约束+示例+反复强调"。
1. 为什么AI不按JSON输出?
因为AI的"思维惯性":它觉得"说人话"更自然。你让实习生写报告,他可能先写"我今天做了啥",而不是直接给结论。
2. 有效方法:
**角色定位:开头就写"你是JSON生成器,只输出JSON,不解释";**反复强调:开头和结尾都写"必须输出纯JSON,不要任何其他文字
3. 实际例子:
你是JSON生成器,只输出JSON,不要任何其他文字。
1. 为什么AI不按JSON输出?
因为AI的"思维惯性":它觉得"说人话"更自然。你让实习生写报告,他可能先写"我今天做了啥",而不是直接给结论。
2. 有效方法:
**角色定位:开头就写"你是JSON生成器,只输出JSON,不解释";**反复强调:开头和结尾都写"必须输出纯JSON,不要任何其他文字
3. 实际例子:
你是JSON生成器,只输出JSON,不要任何其他文字。
这样,AI几乎不会跑偏。我们Prompt工程往往做不好的原因,一方面我们以为AI是人觉得AI能"理解",其实它只是"匹配模式"。或者只给任务,不给框架,说"写产品介绍",不说"用什么风格、什么长度"。还存在例子太简单情况,只给1个例子,AI没学会"规则"。不重视Output Format,觉得"输出随便",也会出现工程系统没法处理的问题。
零基础如何高效学习大模型?
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和MoPaaS魔泊云联合梳理打造了系统大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!

【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与MoPaaS魔泊云的鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!

















 490
490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









