



文章详细介绍了大模型微调的核心知识,包括Transformer架构、参数量计算、显存占用分析,以及微调关键技术如Prompt工程、数据构造和LoRA方法。提供了从数据准备到模型训练部署的完整流程,介绍了idealab、Whale等实用工具,并通过DPO训练等技术提升模型表现。强调数据质量对微调效果的关键影响,为读者提供了一套完整的大模型微调解决方案。

阿里妹导读
本文详细介绍了大型语言模型(LLM)的结构、参数量、显存占用、存储需求以及微调过程中的关键技术点,包括Prompt工程、数据构造、LoRA微调方法等。
一、微调相关知识介绍
1.1. 认识大模型
在介绍LLM的微调知识前,我们先具象的认识下大模型长什么样子,包括模型结构、参数量、精度、显存占用。
1.1.1. 模型结构
《Attention Is All You Need》是一篇Google提出的将Attention思想发挥到极致的论文。这篇论文中提出一个全新的模型,叫 Transformer,抛弃了以往深度学习任务里面使用到的 CNN 和 RNN。
可以看到Encoder包含一个Muti-Head Attention模块,是由多个Self-Attention组成,而Decoder包含两个Muti-Head Attention。Muti-Head Attention上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
LLM大模型基本选择以Decoder模块堆叠N层组成的网络结构。
Transformer结构如下:
| LLM大模型基本选择以Decoder模块堆叠N层组成的网络结构。 |
1.1.2. 模型参数
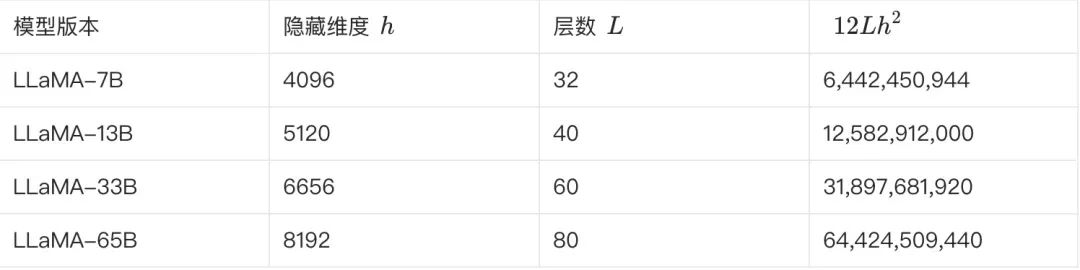
例如羊驼系列 LLaMA 大模型,按照参数量的大小有四个型号:LLaMA-7B、LLaMA-13B、LLaMA-33B 与 LLaMA-65B。这里的 B 是 billion 的缩写,指代模型的参数规模。故最小的模型 7B 包含 70 亿个参数,而最大的一款 65B 则包含 650 亿个参数。
我们以大模型的最基本结构 Transformer 为例,首先来看一下参数量是怎么算出来的。
transformer 由 L 个相同的层组成,每个层分为两个部分:self-attention 和 MLP 层。
综上所述,L 层的 transformer 模型的总参数量为 L(12h²+13h)+Vh,当隐藏维度 h 较大时,可以忽略一次项,模型参数量可以近似为 12Lh²。
1.1.3. 模型显存
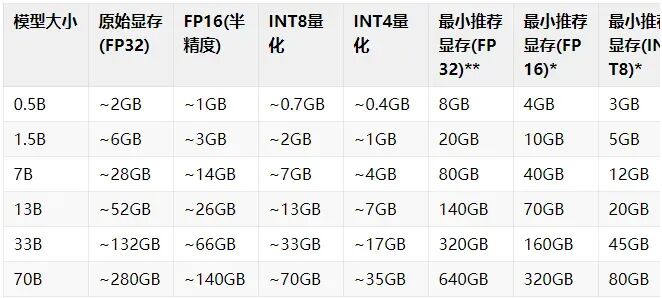
如何计算大语言模型所需的显存?

4B是因为32位的浮点精度会占4个字节内存;
下面以运行16位精度的 Llama 70B 模型所需的 GPU 内存为例套用公式:
该模型有 700 亿参数。
M = (700 ∗ 4) / (32 / 16) ∗ 1.2 ≈ 140 * 1.2 = 168GB
1.1.4. 模型存储
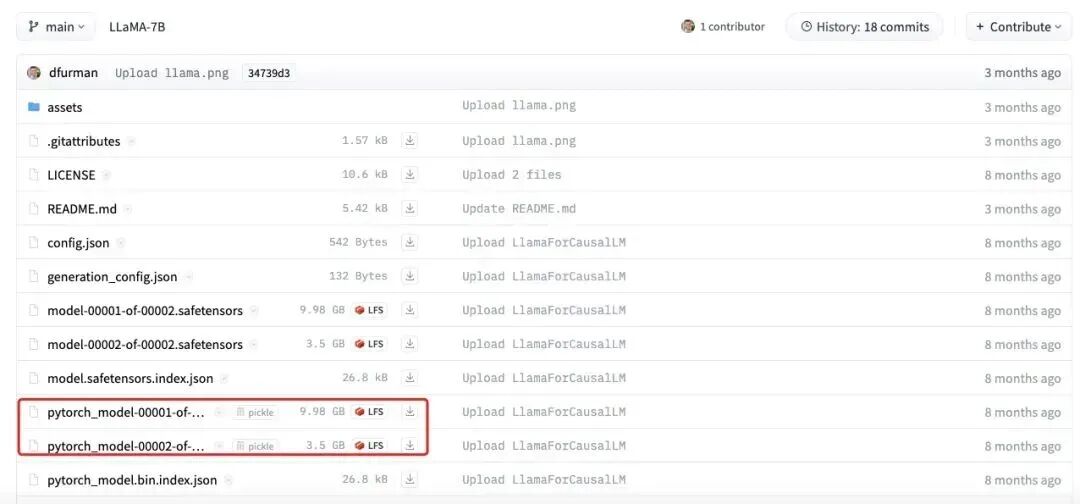
我们以 LLaMA-7B 为例,这个大模型参数量约为 70 亿,假设每个参数都是一个 fp32,即 4 个字节,总字节就是 280 亿字节,则 280 亿字节/1024(KB)/1024(MB)/1024(GB) = 26.7GB,当然这是原始的理论值,我们再往下看。因为实际存储 weight 权重参数会存 fp16,所以模型大小继续减半为 13.35GB。但是部分 layer norm 等数据会保留源格式 fp32,因此实际会稍微有所增加到 13.5GB 左右,我们从开源的 LLaMA-7B 的实际的存储结果来看,是符合上面的计算的:
相信在介绍这部分后,大家应该对LLM大模型的模型结构、参数量、精度、存储空间更具象的认识。
1.2. 模型微调
1.2.1. prompt工程

模型微调通常来说,虽然可以提高任务的效果,但通常来说,微调的成本远大于提示词调优,模型微调相对来说复杂性高、资源需求大而且成本高。
使用 OpenAI API 进行快速工程的最佳实践:
https://help.openai.com/en/articles/6654000-best-practices-for-prompt-engineering-with-the-openai-api
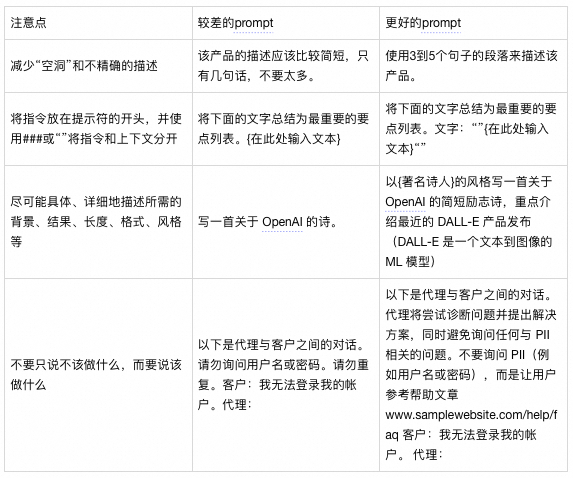
prompt:结构化、具体化、清晰化
在微调之前先尝试优化prompt和fewshot来探索模型能力边界,是否能解决现有问题,合适的base-model(类型和size)的选取,有了明确的效果保证后,再微调得到更加稳定的效果输出和更小的size部署等需求。
1.2.2. 数据构造
有这么一句话在业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。所以数据的构造至关重要,需要建立对生成数据质量的把控。
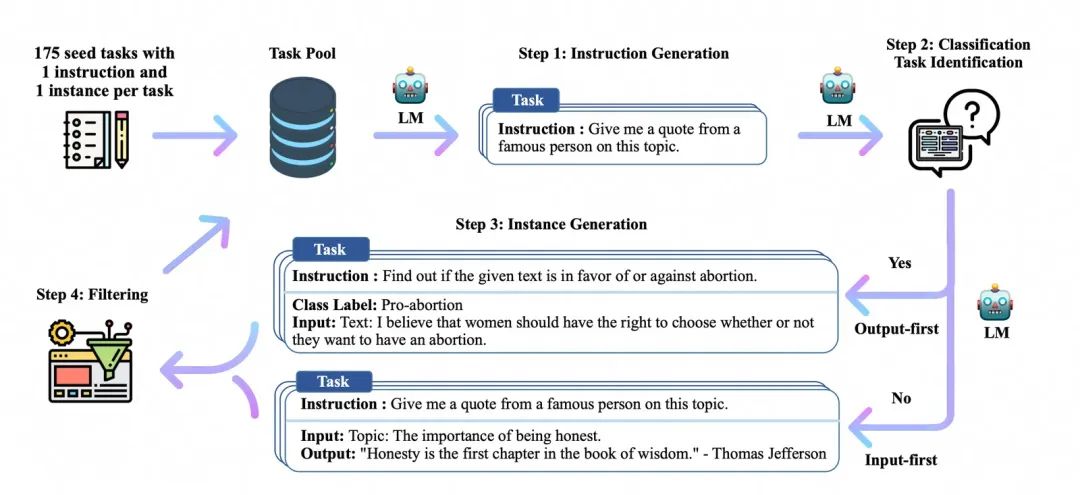
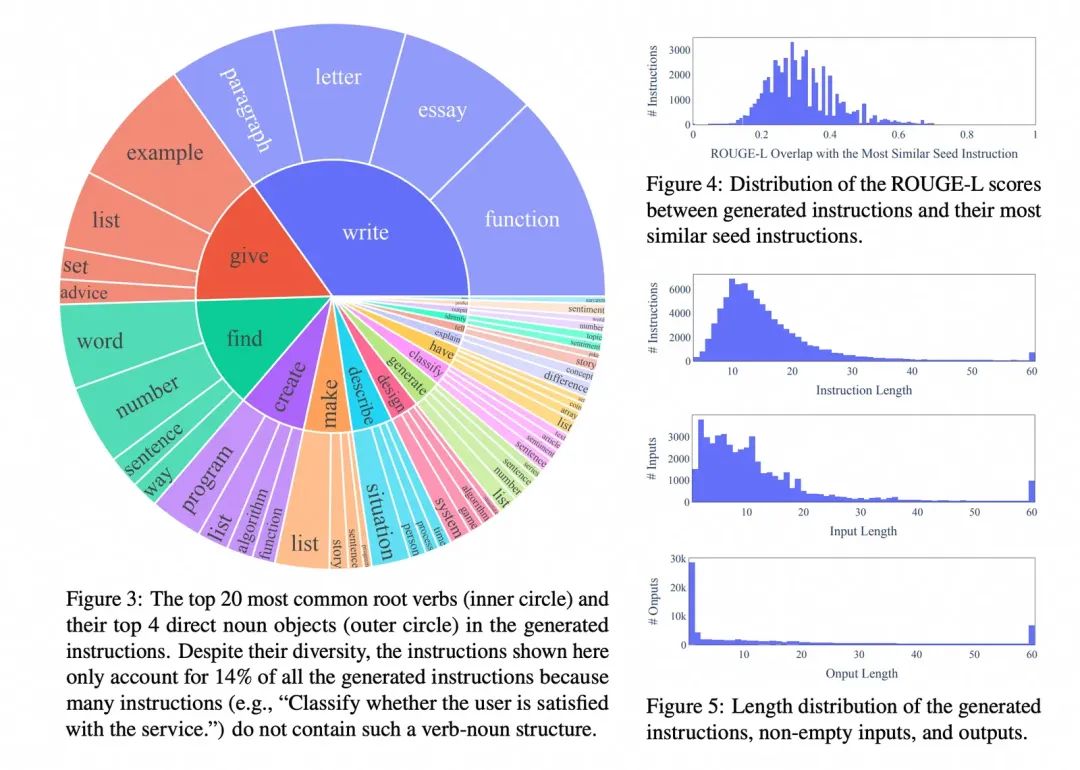
在chatgpt出来后,业界最开始基于pretrain模型上做sft最受关注的工作之一,是self-instruct,蒸馏chatgpt得到高质量的sft数据,很多后来的生成sft数据的工作是以这个工作为基础。核心思想是通过建立种子集,然后prompt模型输出目标格式的数据,通过后置ROUGE-L等筛选方法去重,不断的加入种子集合,来提升产出数据的多样性和质量。
比如qwen2.5-7b是pretrain后的模型,qwen2.5-7b-instrcut是基于qwen2.5-7b做了通用的SFT微调后得到。
生成指令数据的流程由四个步骤组成。1)指令生成,2)识别指令是否代表分类任务,3)用输入优先或输出优先的方法生成实例,4)过滤低质量数据。
关注数据集的质量和丰富度:
我们提及微调更多是在通用SFT训练好的模型基础上再做领域的微调。
可以更省事的选择俄把生成好的数据,直接丢给模型去训练验证最后的效果;但是如果朝着长期做效果迭代的方向,我们需要对生成的数据是否符合预期,有更现验的判断,这也能够为后续如果微调后模型不符合预期的情况下,来有debug的依据和方法。
一方面是人来check数据质量,另外一方面是可以通过规则或者LLM大模型来做后置的数据验证,让模型来打分并给出推理过程等方式。数据量的问题上,跟数据类型的分布关系很大,需要产生不同任务下的高质量数据,更需要关注数据分布。
1.2.3. LoRA微调
基于已有开源大模型进行微调训练,如果采用预训练的方式对模型的所有参数都进行训练微调,由于现有的开源模型参数量都十分巨大。PEFT (Parameter-Efficient Fine-Tuning),即对开源预训练模型的所有参数中的一小部分参数进行训练微调,最后输出的结果和全参数微调训练的效果接近。
LoRA(论文:LoRA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS),该方法的核心思想就是通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练。(秩是矩阵中最长的独立行数或列数)
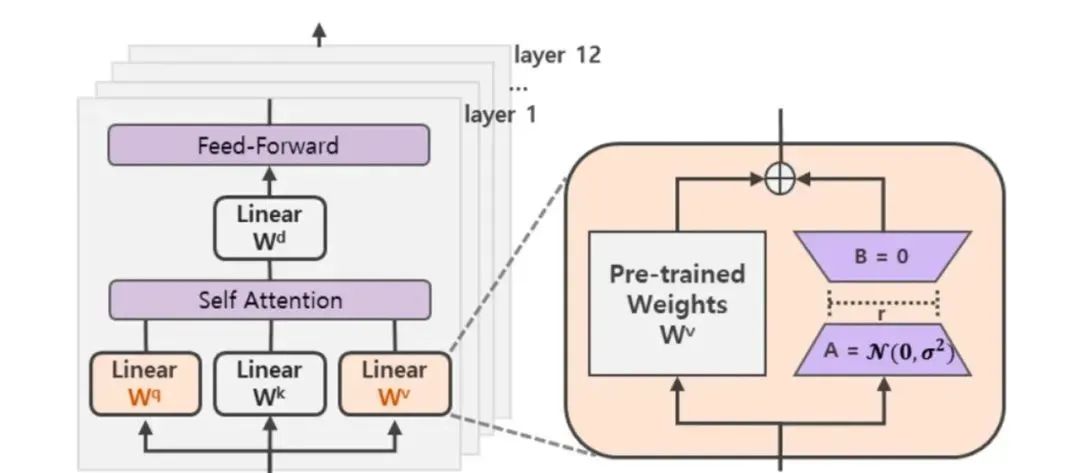
神经网络包含很多全连接层,其借助于矩阵乘法得以实现,然而,很多全连接层的权重矩阵都是满秩的。因此,论文的作者认为权重更新的那部分参数矩阵尽管随机投影到较小的子空间,仍然可以有效的学习,可以理解为针对特定的下游任务这些权重矩阵就不要求满秩。
在涉及到矩阵相乘的模块,在旁边增加一个新的通路,通过前后两个矩阵A,B相乘,第一个矩阵A负责降维,第二个矩阵B负责升维,中间层维度为r。其中,r<<d,r是矩阵的秩,这样矩阵计算就从d x d变为d x r + r x d,参数量减少很多。将原部分跟新增的通路两部分的结果加起来作为最终的结果(两边通路的输入跟输出维度是一致的)。
此外,Transformer的权重矩阵包括Attention模块里用于计算query, key, value的Wq,Wk,Wv以及多头attention的Wo,以及MLP层的权重矩阵,LoRA只应用于Attention模块中的4种权重矩阵,而且通过消融实验发现同时调整 Wq 和 Wv 会产生最佳结果。
1.3. 强化学习
instructGPT提出的SFT和RLHF的流程图,在SFT模型的基础做强化学习的训练往往会提升模型的表现。
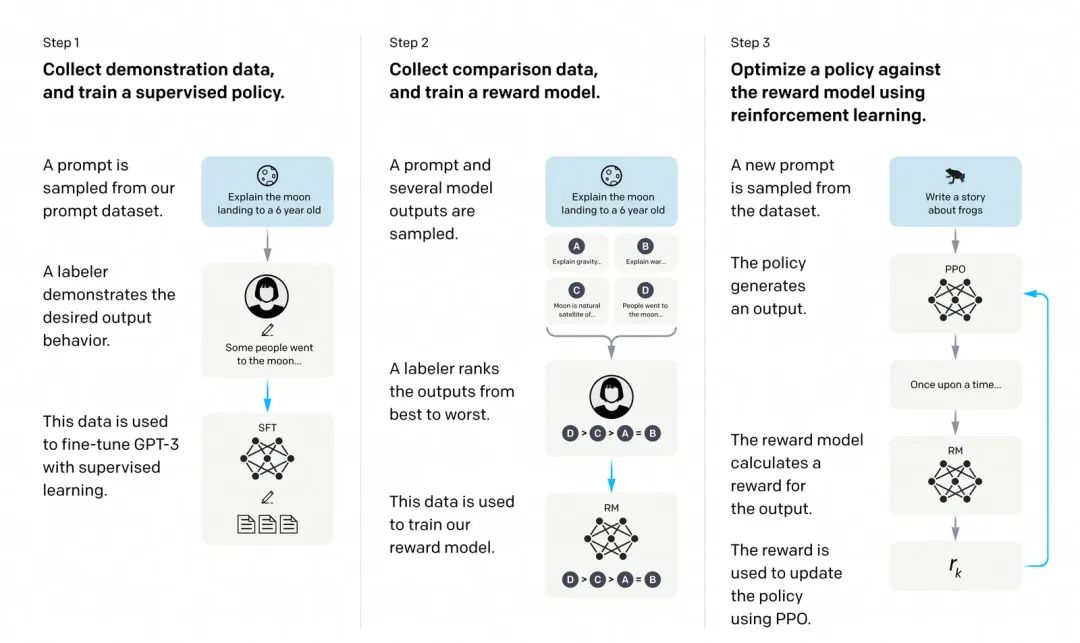
我们需要一个模型来定量评判模型输出的回答在人类看来是否质量不错,即输入 [提示(prompt),模型生成的回答] ,奖励模型输出一个能表示回答质量的标量数字。
1.把大量的prompt(Open AI使用调用GPT-3用户的真实数据)输入给第一步得到的语言模型,对同一个问题,可以让一个模型生成多个回答,也可以让不同的微调(fine-tune)版本回答。
2.让标注人员对同一个问题的不同回答排序,实验发现发现不同的标注员,打分的偏好会有很大的差异,而这种差异就会导致出现大量的噪声样本。排序的话能获得大大提升一致性。
3.这些不同的排序结果会通过某种归一化的方式变成定量的数据丢给模型训练,从而获得一个奖励模型。也就是一个裁判员。
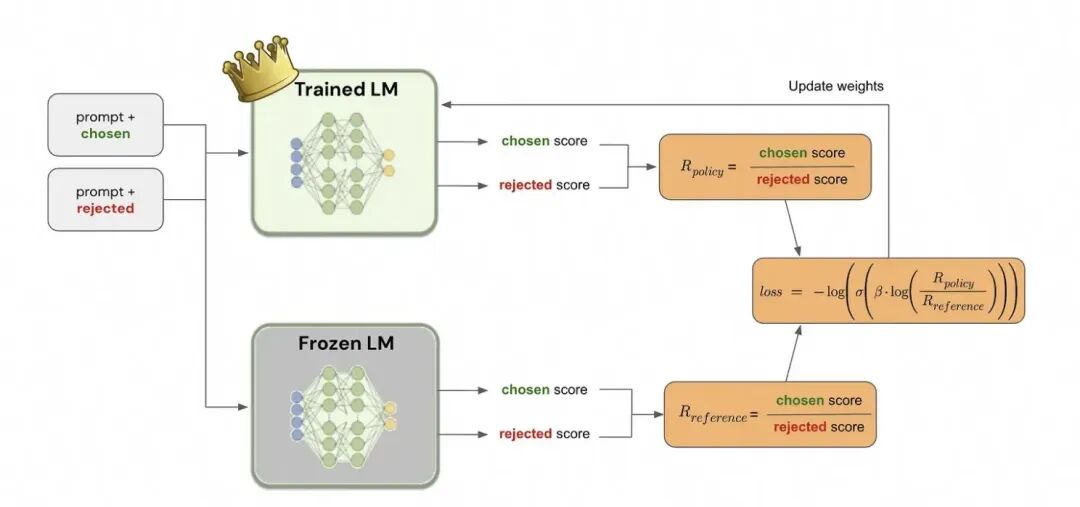
1.3.1. DPO训练
由于PPO需要4个模型加载,2个推理,2个训练,成本较高;而DPO只需要两个模型,一个推理一个训练。
开始训练时,reference model和policy model都是同一个模型,只不过在训练过程中reference model不会更新权重。
目标函数:
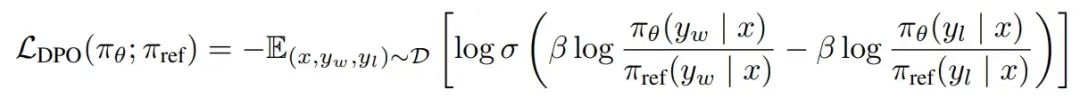
梯度:
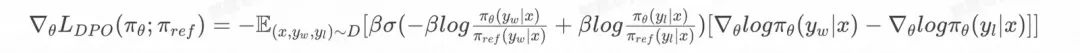
动态因子:
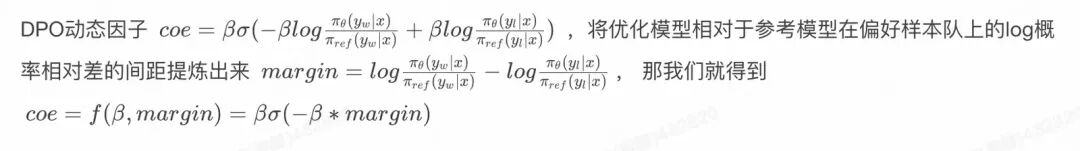
因此DPO的优化目的可以理解为通过训练, 最大化正样本上的奖励 和负样本上的奖励两者的间距(margin)。 因为参考模型是不动的,因此进一步可以理解为提升模型在正样本上的概率(优化模型在正样本上的概率 大于 参考模型在正样本上的概率), 降低模型在负样本上的概率(优化模型在负样本上的概率 小于 参考模型在负样本上的概率)。
当我们的任务能够产出正负样例对的时候,我们可以通过这种方式来微调模型提升表现。来让模型从正负样例中学到好的为什么好,差的为什么差,往往能够得到比SFT更优的效果。它和SFT的区别在于,SFT只能告诉模型正例而没有负例。
{
二、微调实践&工具使用
介绍完一些初步的理论基础后,这部分主要来讲大模型的具体微调流程和具体的操作细节。
因为集团内外关于模型微调的工具也很丰富,这里只给出我们团队常使用的平台和框架,以及微调的实操流程。
本文涉及几个内部平台说明:
- 星云平台:模型训练平台
- TuningFactory:基于LLaMA-Factory在星云平台上开发的框架
- Whale:模型部署平台
- idealab:请求开/闭源模型方式
外部平台:
- LLaMA-Factory-外部通用微调框架-本地微调模型
https://github.com/hiyouga/LLaMA-Factory
这里给出一个微调的实践简化流程如下:
-
数据构造
-
idealab 请求
-
请求部署在whale上的开源模型(节约成本)
-
数据分析&思考
-
训练集和测试集的对齐
-
数据质量、分布、量级
-
训练平台的选择&任务提交
-
本地
-
星云平台
-
训练模型超参调整
-
对验证集loss关注&checkpoint的选择
-
模型推理部署
-
whale的推理加速、参数设置等
-
测试集数据分析
-
迭代 or Done
2.1. 数据构造
2.1.1. idealab工具
idealab 帮助文档一共接入了包含文生文、多模态、向量化、bing搜索、代码生成等类别的大模型共计近50个,涵盖了包含azure openai gpt系列、dalle,阿里通义千问、淘天星辰,谷歌vertexAI系列等主流模型。

调用的方式:
-H "Content-Type:application/json"
-
收费:依赖key,需要预算申请,主要用于闭源模型的调用;
-
部分免费:目前通义系列(百炼在线模型)、deepseek r1、v3等是免费。
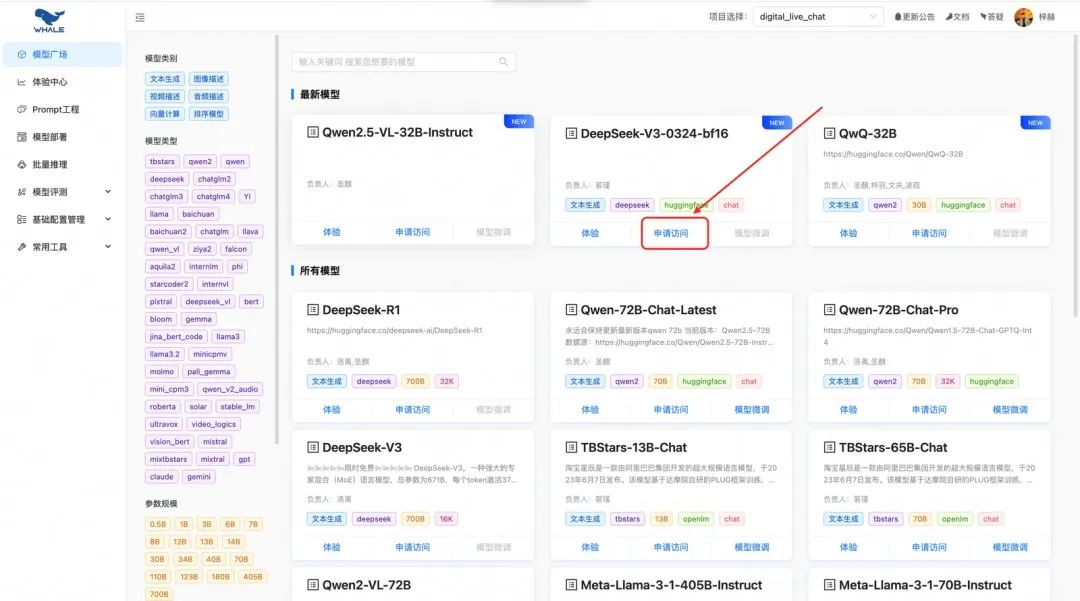
2.1.2. 部署在whale上的开源模型
whale平台上提供了丰富的开源模型部署,根据调试或批量调用的需求,可以分成访问免费部署模型和独立部署模型两部分。整体体验还是比较便捷,对大模型部署支持的比较好,比较推荐。
- 访问whale部署的免费模型,通过申请访问平台部署的公共模型,可以快速调用。无需卡资源。
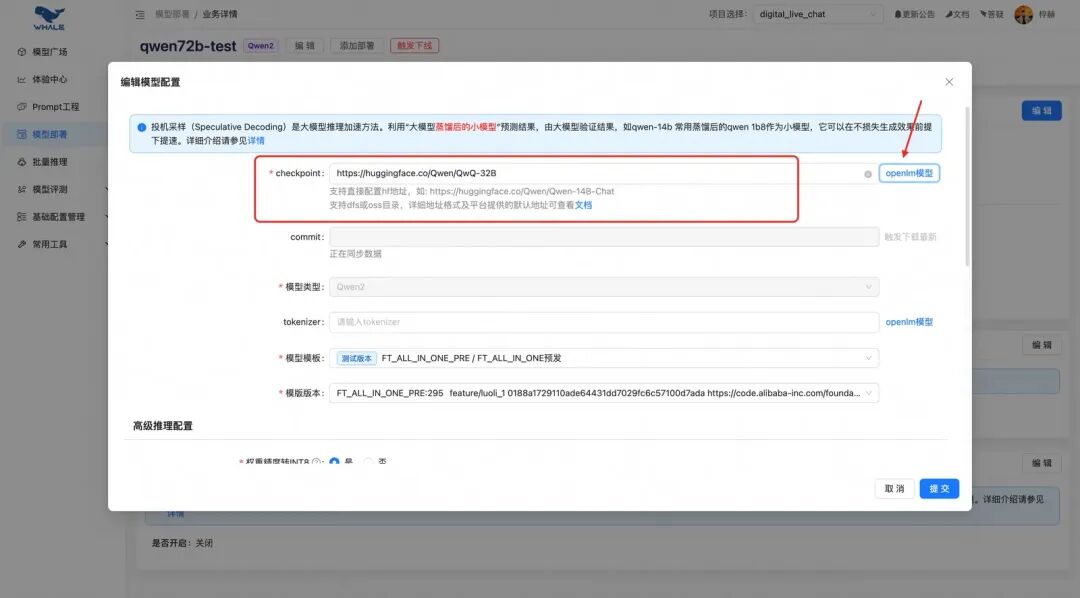
- 独立部署在whale上模型,如果本身的任务请求量大,对耗时有要求等,可以部署自己的开源模型。需要卡资源。
在部署模型之后,除了whale的UI界面去调用,也支持sdk调用whale服务代码:LLMChatStreamDemo.py,核心代码如下:
from whale import TextGeneration, VipServerLocator
2.2. 训练平台的选择&任务提交
当我们通过上述方式生成好自己的训练集后,就需要开始微调模型了。
针对小任务/小模型,可以在自己开发机上微调即可,推荐使用LLaMA-Factory微调框架;对于依赖较大资源或者数据量较大的情况,可以使用TuningFactory框架,结合星云平台做模型的训练。
LLaMA-Factory代码库:https://github.com/hiyouga/LLaMA-Factory
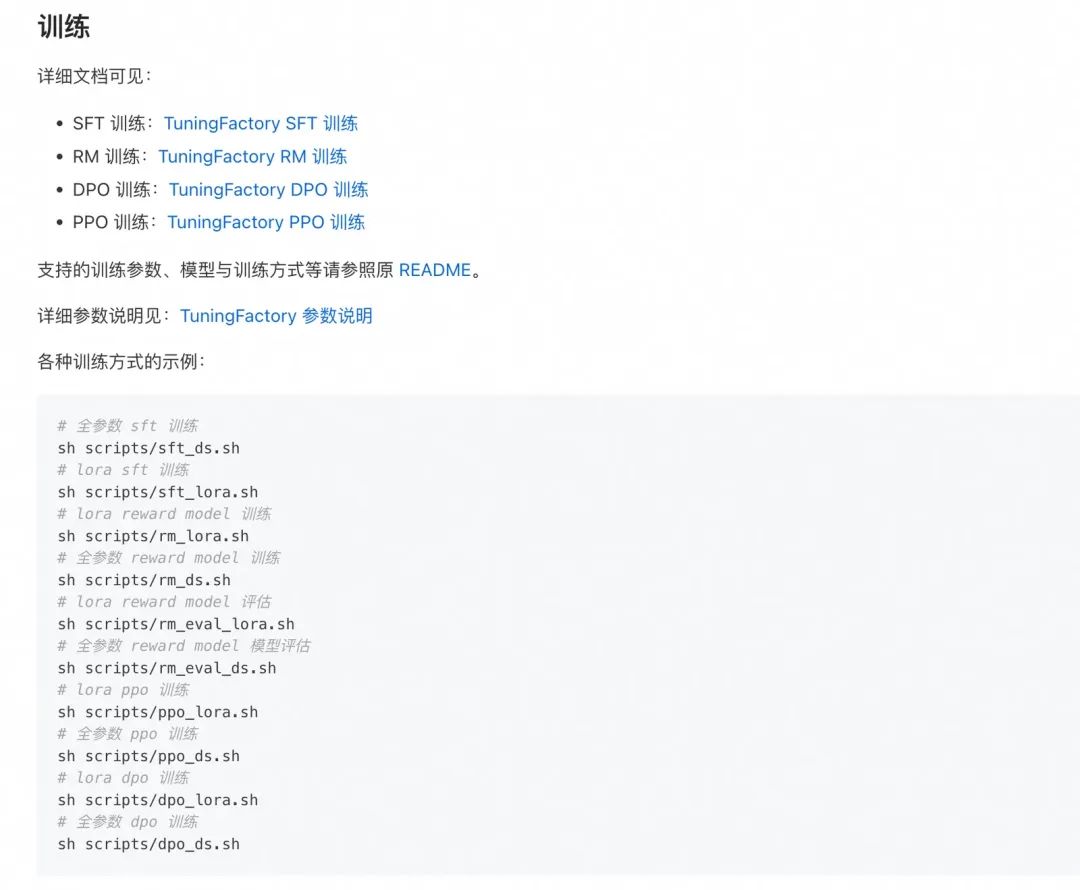
lora微调,scripts/sft_lora.sh
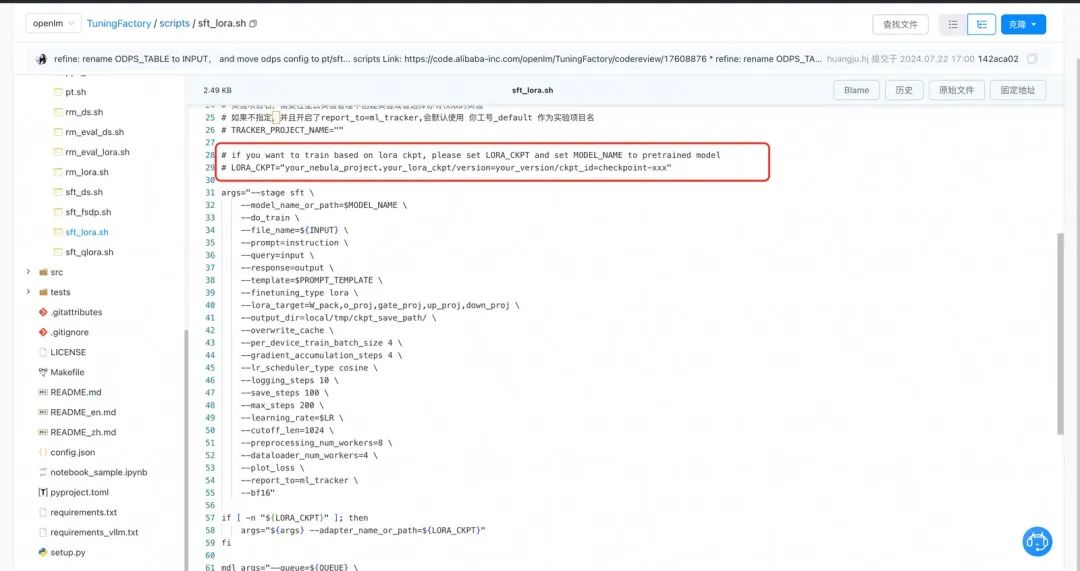
WORLD_SIZE=8
在这里可以指定训练的lora checkpoint到指定的项目存储路径,后续可以在whale平台直接调用,非常方便。
训练完成结果和统计图表如下:
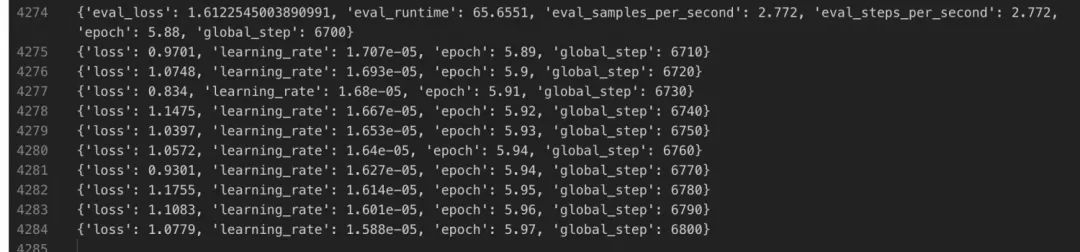
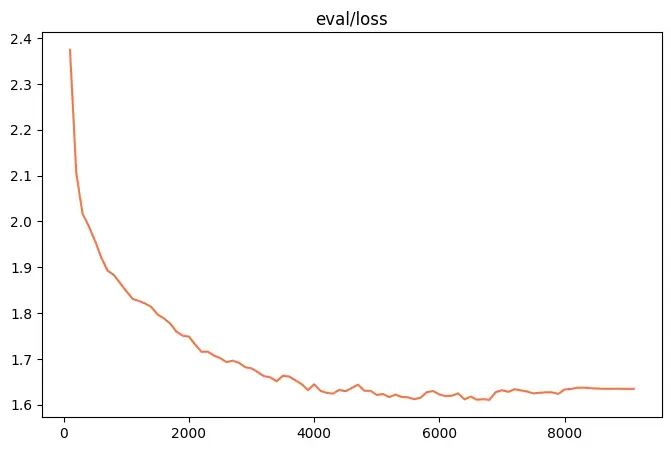
挑选eval集合上loss最低的checkpoint作为最优的模型。
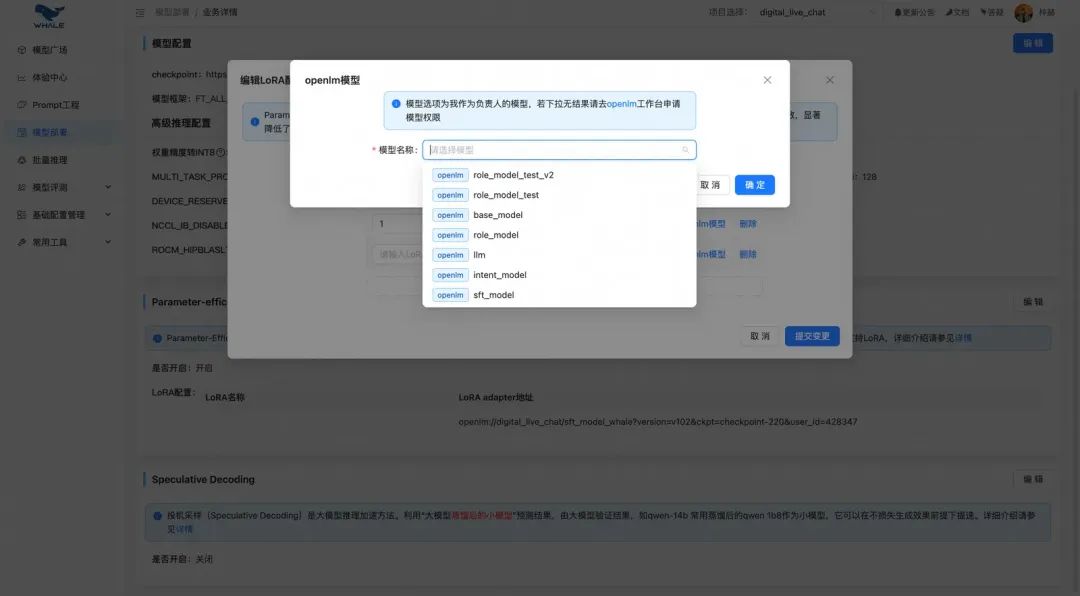
2.3. 微调模型部署
在模型配置处可以搜索上一步中生成好的训练模型,选择部署。
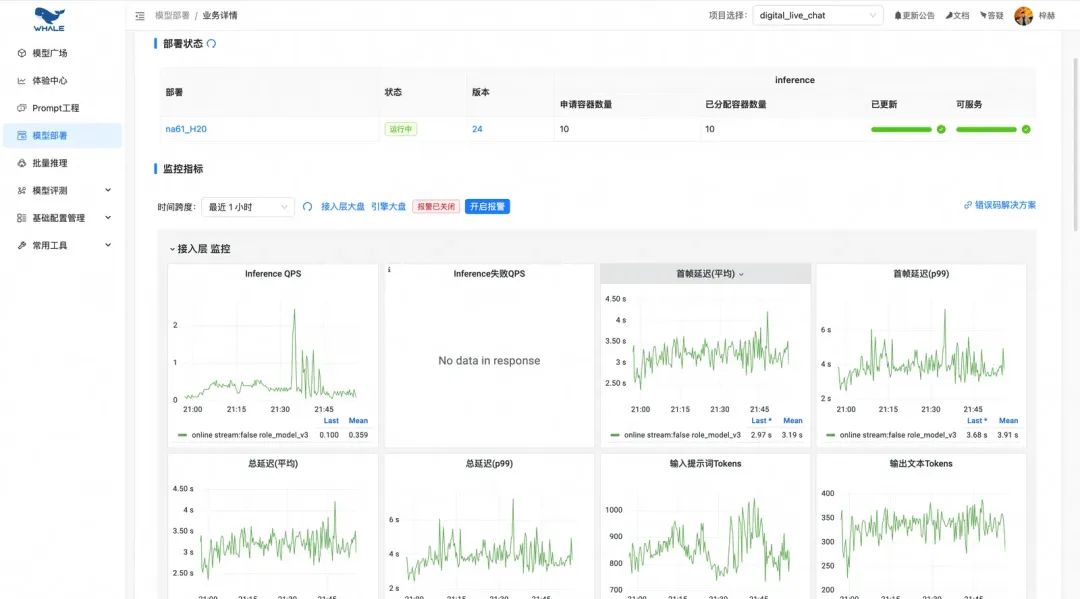
自动化的流量和模型性能监控报表:
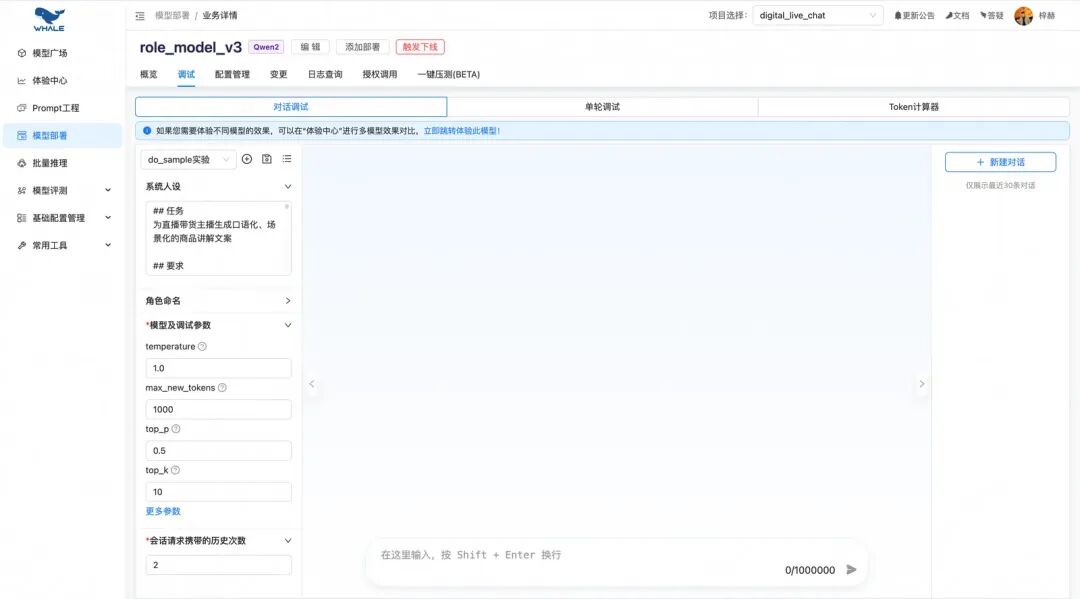
可视化的对话调试界面:
2.3.1. 推理加速
在模型的推理加速上,探索过以下三种whale平台上配置加速的手段:
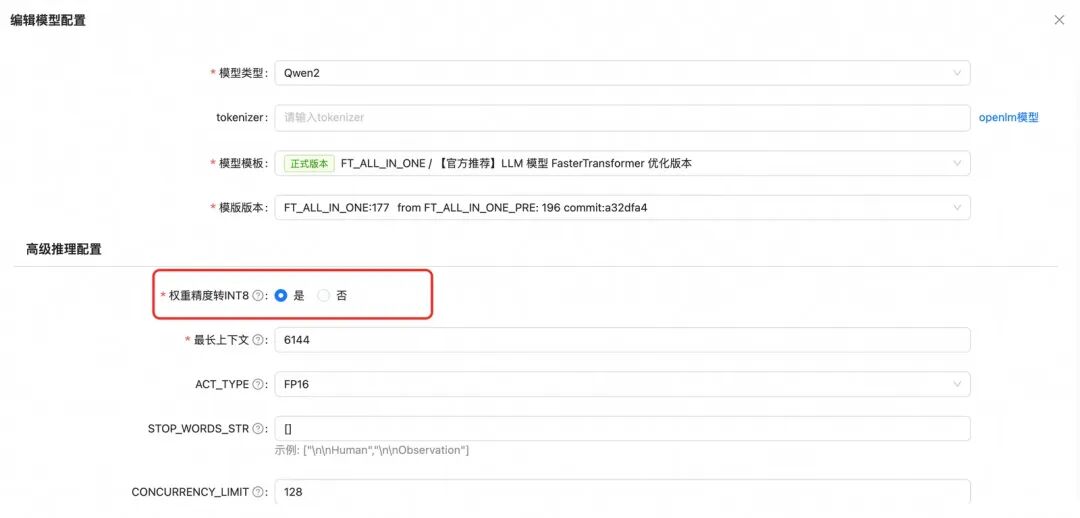
- 降低加载精度(效果会存在损失);
-
可以选fp16或者int8精度加载模型;
-
需要关注精度降低后的效果变化;
-
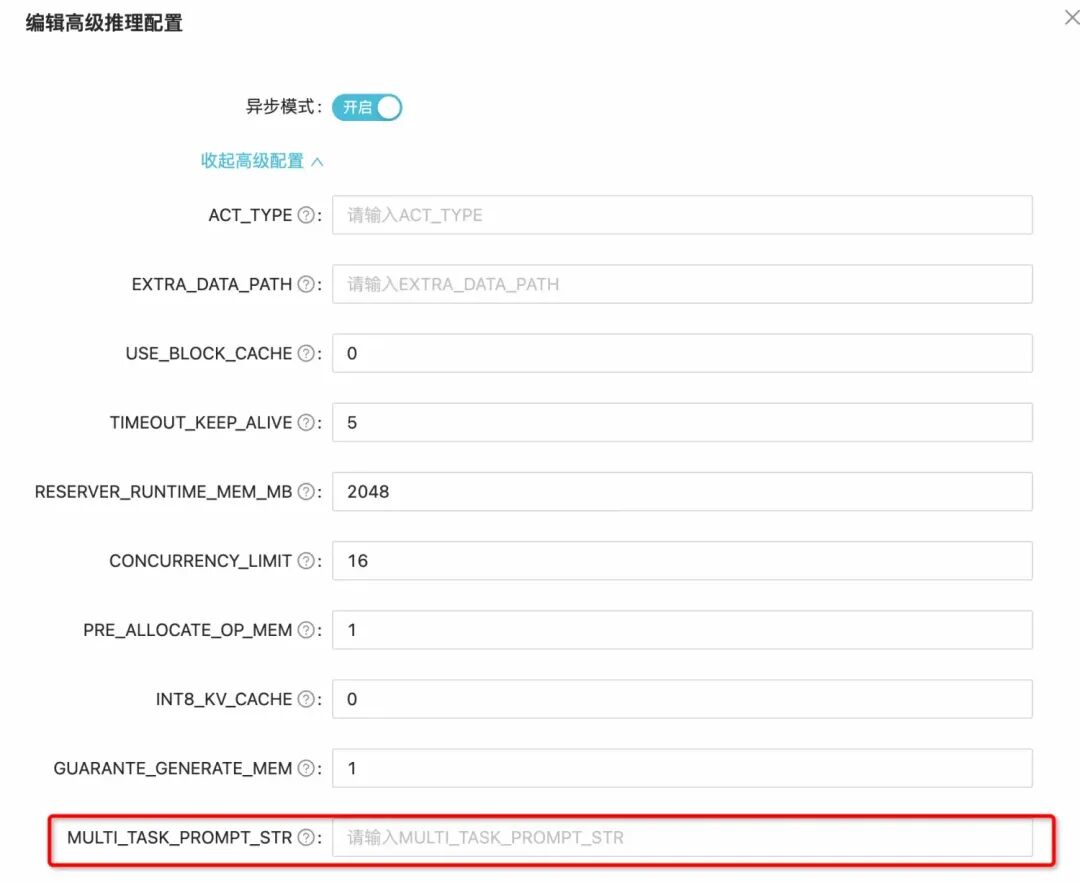
System-prompt缓存,如果prompt长且固定可以用这种方法;
-
[{“task_id”: 1, “prompt”: " <|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>"},{“task_id”: 2, “prompt”: “你是一个严谨的程序员,你接下来需要非常谨慎的思考并回答以下问题:”}];
-
投机采样-vanilla speculative decoding;
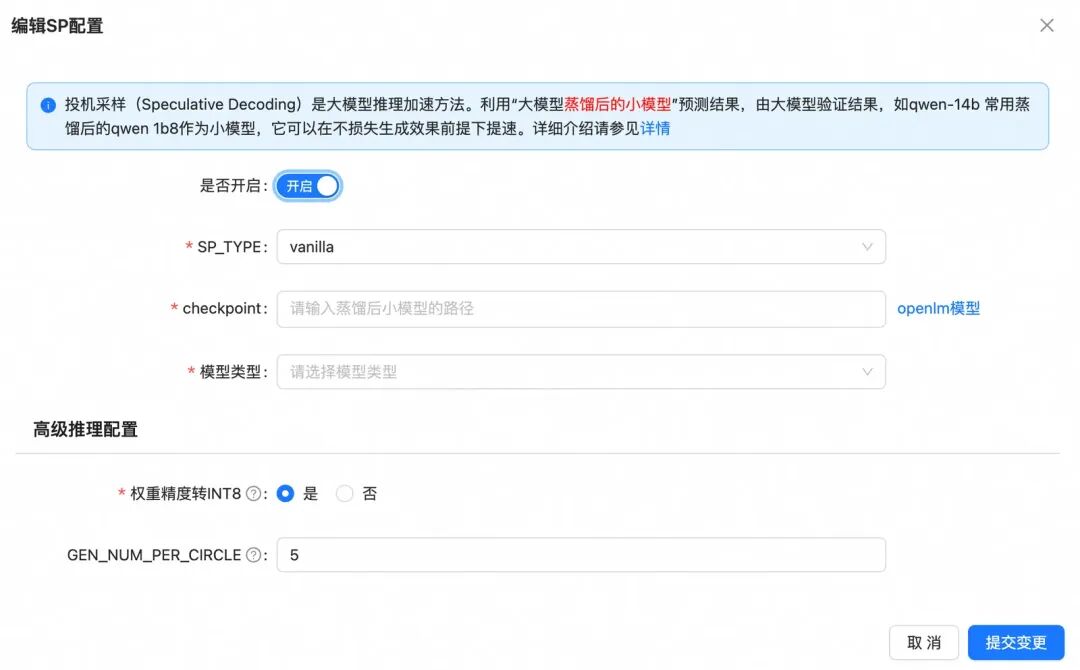
- 投机采样:利用“大模型蒸馏后的小模型”预测结果,由大模型验证结果,如qwen-14b 常用蒸馏后的qwen 1b8作为小模型,它可以在不损失生成效果前提下提速。
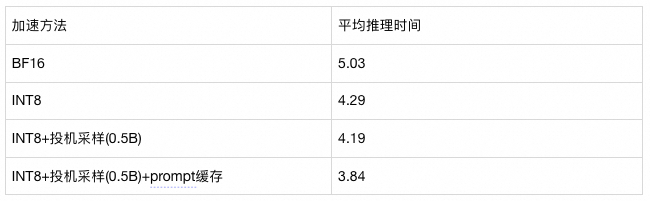
以Qwen2.5-7B为例,测试不同加速方法带来的提升:
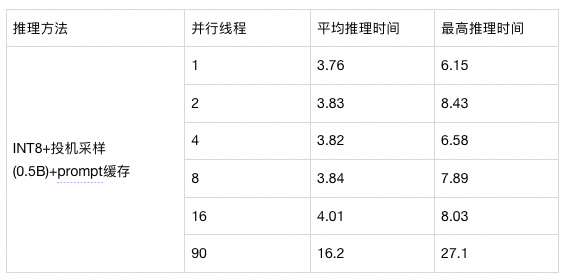
平台自动支持:推理引擎会根据请求自动凑batch推理;支持多并发请求:
2.4. 测试集数据分析
模型微调和部署完成后,往往需要在我们的测试集上查看模型效果,这依赖你需要有:
-
反映你线上真实情况的测试集;
-
细化的测评指标;
我们需要预先定义一个指标来判断模型的效果好坏,对于指标定义不明确的任务,尽量细化它的标准。可以让人工去评估,也可以让大模型自动评估。
2.5. 评估迭代:优化 or 上线
经过上述步骤有了新的模型效果后,除了考虑算法工程(耗时、部署资源、模型并发)外,效果上需要考虑是否能推送上线的关注点:
-
宏观整体指标上的对比(机器/人工);
-
模型效果是否符合优化预期,目标goodcase;
-
其他case上,模型效果是否变差,是否需要优化;
从指标和case分析中,发现并定位问题;从数据构造中不断去完善更高质量的数据,探索更强模型和更优的微调方法。
全是goodcase是个理想的情况,实验结果往往会存在不符合预期或者跷跷板的问题,这个时候需要思考是模型能力的问题、还是数据构造上有考虑不周的情况等。不同的任务/base模型/数据质量/训练参数和数据集都有关,还是得结合具体场景来做分析和优化。一般经验来讲提升数据质量是最直接有效的方法,在这个基础上再探索强化学习、推理模型等进一步解决目标问题的手段。
Reference
工具:
llamaFactory代码库:https://github.com/hiyouga/LLaMA-Factory
一些教程:
https://github.com/liguodongiot/llm-action?tab=readme-ov-file
https://zhuanlan.zhihu.com/p/695287607
https://help.openai.com/en/articles/6654000-best-practices-for-prompt-engineering-with-the-openai-api
论文:
attention is all you need:https://arxiv.org/pdf/1706.03762
isnstructGPT:https://arxiv.org/pdf/2203.02155
self-instruct:https://arxiv.org/pdf/2212.10560
lora:https://arxiv.org/abs/2106.09685
其他参考:
https://blog.youkuaiyun.com/weixin_49895216/article/details/145651100
https://blog.51cto.com/u_16163510/12979020
https://zhuanlan.zhihu.com/p/695287607
https://zhuanlan.zhihu.com/p/636215898
服务优化新策略:AI大模型助力客户对话分析
在数字化时代,企业面临着海量客户对话数据的处理挑战,迫切需要从这些数据中提取有价值的洞察以提升服务质量和客户体验。本方案旨在介绍如何部署AI大模型实现对客户对话的自动化分析,精准识别客户意图、评估服务互动质量,实现数据驱动决策。
a:https://arxiv.org/abs/2106.09685
其他参考:
https://blog.youkuaiyun.com/weixin_49895216/article/details/145651100
https://blog.51cto.com/u_16163510/12979020
https://zhuanlan.zhihu.com/p/695287607
https://zhuanlan.zhihu.com/p/636215898
服务优化新策略:AI大模型助力客户对话分析
在数字化时代,企业面临着海量客户对话数据的处理挑战,迫切需要从这些数据中提取有价值的洞察以提升服务质量和客户体验。本方案旨在介绍如何部署AI大模型实现对客户对话的自动化分析,精准识别客户意图、评估服务互动质量,实现数据驱动决策。
那么,如何系统的去学习大模型LLM?
如果你也想系统学习AI大模型技术,想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习*_,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和MoPaaS魔泊云联合梳理打造了系统大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!

【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与MoPaaS魔泊云的鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!

















 28万+
28万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









