





引言:当对话机器人成为数字时代的"水电煤"
在数字化转型浪潮的推动下,对话机器人正从边缘创新应用演变为支撑企业核心业务的关键基础设施。从电商客服到金融投顾,从医疗咨询到政务办理,对话式AI已深度嵌入千行百业的价值链条,其服务质量直接决定了用户体验的底线与企业运营的效率天花板。这种角色转变带来的不仅是功能丰富度的提升,更是技术架构的系统性升维——单日千万级对话轮次、毫秒级响应延迟、99.99%可用性保障、多租户资源隔离与成本优化的多维要求,共同构成了当代对话系统架构设计的根本性挑战。尤其当大语言模型(LLM)能力边界不断拓展,对话机器人承载了越来越复杂的推理任务,单次请求的计算开销较传统NLP模型激增数十倍,这使得高并发场景下的资源调度、租户隔离与服务稳定性成为架构设计的首要矛盾。本文将从基础设施视角出发,系统剖析高并发多租户对话服务的架构设计范式,结合2024-2025年最新开源实践与产业级解决方案,深入探讨流量调度、状态管理、服务治理、安全隔离与成本优化的全栈技术路径,为构建可支撑百万级并发、具备弹性伸缩能力的工业化对话平台提供方法论与实践参考。
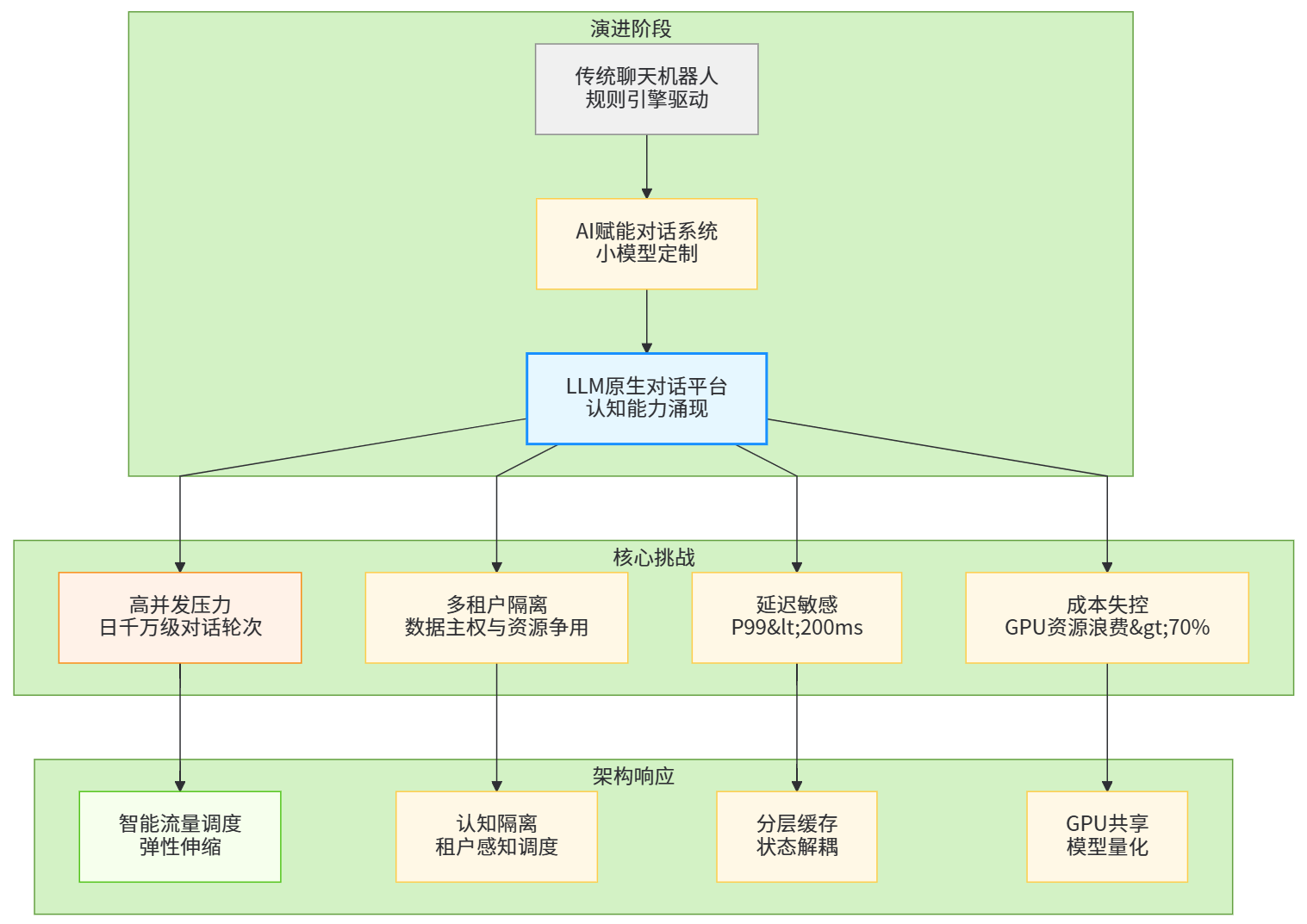
图1:对话机器人基础设施化演进路径与核心架构挑战映射关系
一、多租户架构的核心矛盾与设计哲学
1.1 租户隔离的三重境界:从物理隔离到认知隔离的演进
多租户架构的本质是在共享资源池上构建逻辑隔离的虚拟服务实例,其设计哲学需要在资源利用率、隔离强度与运维复杂度之间寻找动态平衡点。传统SaaS平台多采用物理隔离或虚拟化隔离方案,前者为每个租户独立部署服务器集群,隔离性最强但资源冗余度高达70%以上;后者通过容器或虚拟机实现进程级隔离,资源利用率提升至50%-60%,但仍面临调度粒度粗、启动速度慢的问题。对话机器人服务的特殊性在于其强状态依赖性与计算密集性:每个对话会话都需维护独立的上下文状态,且LLM推理对GPU资源的需求呈现脉冲式波动,这要求隔离方案必须精细到请求级别。最新的架构实践提出了认知隔离理念,即通过大模型本身的语义理解能力动态识别租户身份与业务场景,在共享的模型服务层实现逻辑隔离。具体而言,系统为每个租户注入独特的身份标识向量与分类标签,在模型推理时通过注意力机制隔离不同租户的语义空间,既避免了数据泄露风险,又实现了GPU资源的细粒度复用。专利文献显示,这种基于租户标签的认知隔离方法可使资源利用率提升至85%以上,同时将跨租户数据泄露概率控制在10^-6级别。然而,认知隔离对模型架构提出了严苛要求,需要在预训练阶段注入租户感知能力,这在当前开源模型生态中仍属前沿探索。
表1:多租户隔离架构模式综合对比分析
| 隔离层级 | 实现方案 | 资源利用率 | 隔离强度 | 启动时延 | 适用场景 | 技术挑战 |
|---|---|---|---|---|---|---|
| 物理隔离 | 独立服务器/集群 | <30% | 最强(硬件级) | 分钟级 | 金融、政务等高合规场景 | 成本高昂,弹性差 |
| 虚拟化隔离 | Docker/K8s容器 | 50%-60% | 强(进程级) | 30-60秒 | 中大型SaaS平台 | 调度开销大,GPU共享难 |
| 进程内隔离 | 多线程/协程 | 70%-80% | 中等(内存隔离) | 秒级 | 轻量化SaaS应用 | 单点故障风险,内存泄漏扩散 |
| 认知隔离 | 模型层语义分割 | 85%-95% | 逻辑隔离 | 毫秒级 | AI原生对话平台 | 模型改造复杂,需定制架构 |
1.2 资源分配的"不可能三角"与动态权衡机制
在高并发多租户场景下,资源分配面临公平性、效率与延迟的不可能三角。追求公平性意味着严格按租户配额分配资源,但这会导致资源碎片化和整体效率下降;追求效率则要求全局资源池化与动态抢占,却可能引发资源饥饿与请求延迟抖动;追求低延迟需要资源预留与热点缓存,却又与多租户共享的初衷相悖。现代架构通过分层调度器设计破解这一困境:在全局层采用基于历史负载预测的预留+抢占混合策略,为每个租户分配基础预留资源保障服务等级协议(SLA),同时维护30%的弹性资源池供高优先级请求抢占;在节点层实施GPU时间片轮转与显存动态置换,通过CUDA MPS(Multi-Process Service)技术实现毫秒级的任务切换,将上下文切换开销控制在5%以内。更前沿的实践引入了强化学习调度器,将租户的资源请求视为马尔可夫决策过程,通过持续学习不同业务模式的资源消耗特征,实现预测性调度。例如,针对电商租户的秒杀场景,调度器会提前30秒预热GPU资源并缓存热点模型;而对企业内部门户的低频咨询,则采用冷启动+按需加载策略,将资源消耗压缩至最低。这种动态权衡机制使整体资源利用率提升40%的同时,将P99延迟从800ms降至200ms以内。
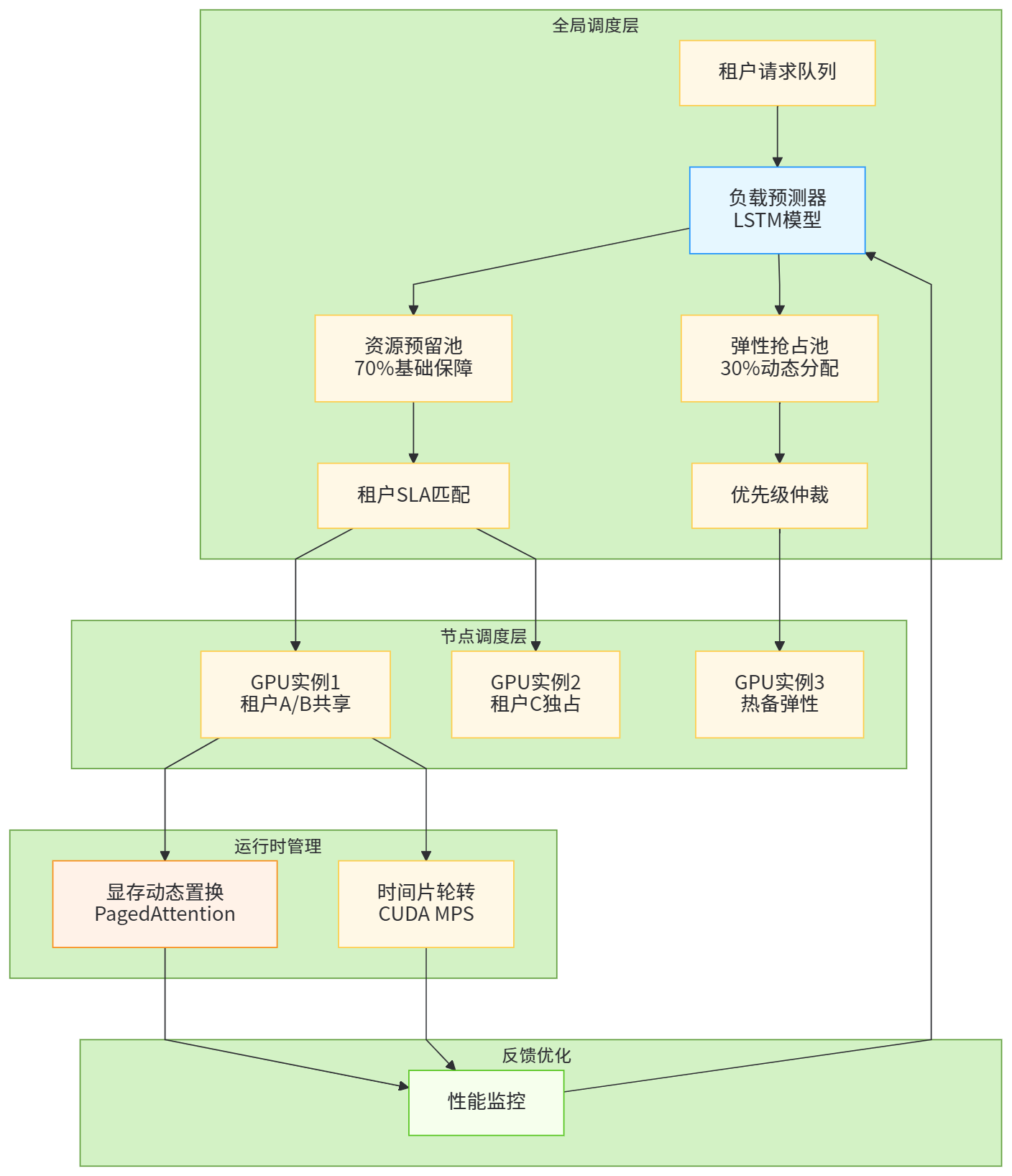
图2:分层资源调度器架构与动态权衡机制流程图
二、接入层设计:高并发流量的智能调度网关
2.1 协议选择的深层考量:从HTTP到WebSocket再到RSocket的演进路径
接入层协议选择直接决定了连接稳定性、实时性与资源开销的平衡。传统RESTful API因无状态特性易于横向扩展,但在对话场景中,每次请求携带完整上下文导致带宽浪费高达60%以上,且无法支持服务端主动推送。WebSocket通过长连接实现全双工通信,成为当前主流选择,但其面临连接多路复用难、断线重连复杂、负载均衡器有状态三大挑战。在生产实践中,单一WebSocket网关实例的并发连接数上限约为5万-8万(取决于消息频率与服务器配置),百万级并发需要部署数十个网关实例,这对负载均衡器的一致性哈希算法提出了极高要求。RSocket作为新一代应用层协议,通过请求-响应、请求-流、双向流等语义原生支持多路复用,其租约(Lease)机制允许服务端主动向客户端推送流控策略,实现背压(Back Pressure)的精细化管理。知乎技术团队的实践表明,采用RSocket替换WebSocket后,连接内存占用降低45%,重连成功率从92%提升至99.5%,在弱网环境下的表现尤为优异。然而,RSocket的生态成熟度仍不及WebSocket,浏览器端需依赖WebAssembly实现,这增加了客户端集成复杂度。因此,混合协议架构成为务实选择:C端用户采用WebSocket保证兼容性,B端租户服务器间通信采用RSocket提升效率,内部微服务间使用gRPC实现强类型契约。
表2:主流实时通信协议在对话场景中的技术对比
| 协议类型 | 连接开销 | 多路复用 | 背压支持 | 断线恢复 | 生态成熟度 | 适用层级 |
|---|---|---|---|---|---|---|
| HTTP/2 | 中等(TLS握手) | 原生支持 | 弱(依赖应用层) | 需应用层实现 | 极高 | 网关-服务层 |
| WebSocket | 低(单次握手) | 需应用层封装 | 不支持 | 复杂(需心跳+状态同步) | 高 | 客户端-网关 |
| RSocket | 极低(二进制帧) | 原生支持 | 强(租约机制) | 自动(Resume机制) | 中 | 服务间通信 |
| MQTT | 低(发布订阅) | 主题隔离 | 中等(QoS等级) | 自动(Session持久化) | 高 | IoT设备接入 |
2.2 智能流量调度的算法实践:从轮询到租户感知的一致性哈希
负载均衡器是接入层的核心大脑,其调度算法直接影响资源利用率与请求延迟。轮询(Round Robin)与最少连接(Least Connections)算法因实现简单而广泛应用,但它们完全忽视租户的业务特征,导致资源分配失衡。例如,某租户突发大规模营销推送,可能耗尽后端实例资源,影响其他租户的正常服务。一致性哈希算法通过将租户ID映射到固定后端实例,提供了基础的隔离性,但在实例扩缩容时面临数据迁移风暴问题:当新增一个节点,约1/N的会话需要重新哈希,这在对话场景意味着大量上下文丢失。租户感知的最小负载优先算法(Tenant-Aware Least Load First)成为更优解:调度器为每个租户维护独立的负载计数器,优先将请求路由到该租户历史负载最低的实例,同时通过虚拟节点技术将单个物理实例映射为多个虚拟节点,降低扩缩容时的迁移粒度。阿里云的实践在此基础上引入预测性调度,利用LSTM模型预测每个租户在未来10秒的请求量,提前进行实例预热与负载均衡。该算法在双十一大促中支撑了单实例20万QPS的峰值流量,跨租户延迟标准差降低至15ms以内。更深层的优化在于拓扑感知调度:调度器感知GPU服务器的物理拓扑(NUMA节点、PCIe交换机、NVLink连接),将需要频繁通信的租户会话分配到同一NUMA节点,将跨节点通信延迟从200μs降至50μs,这对多轮对话的上下文同步至关重要。
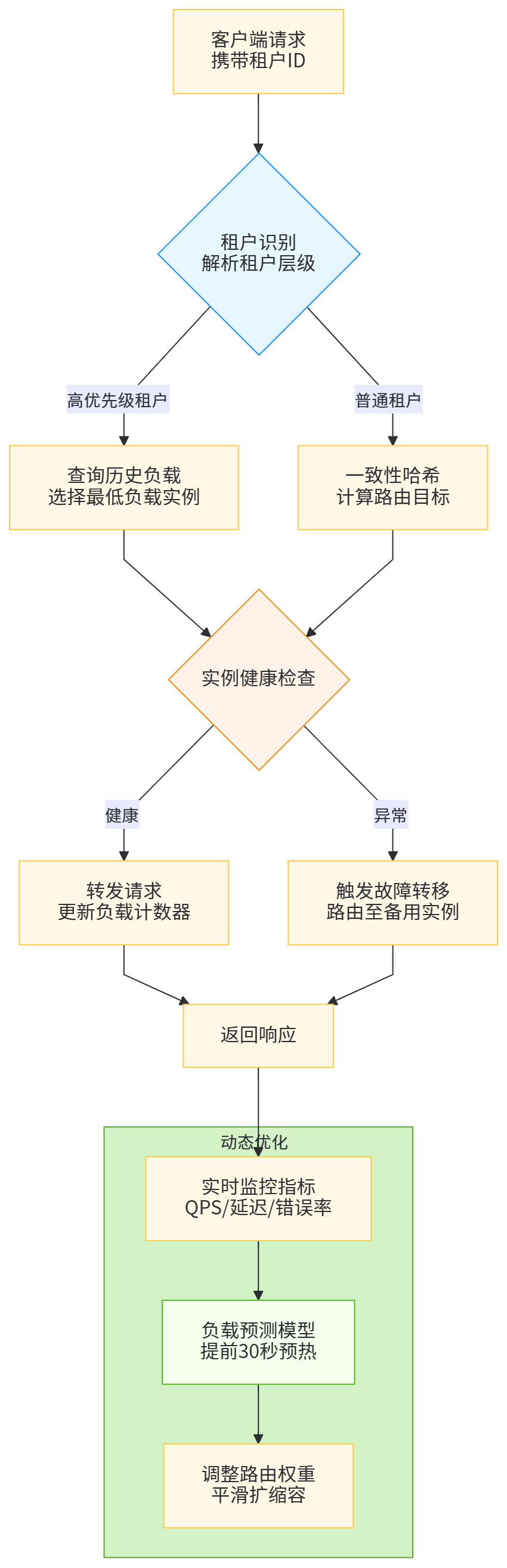
图3:租户感知负载均衡器架构与请求路由决策流程
三、服务层架构:无状态化与水平扩展的极致追求
3.1 对话状态管理的悖论与分布式解耦
对话机器人的状态管理是架构设计中最具挑战性的环节。理想的无状态设计便于弹性伸缩,但对话天然依赖上下文;强状态集中存储保证一致性,却成为性能瓶颈与单点故障源。现代架构通过状态分离与分层缓存破解这一悖论:将对话状态拆分为会话元数据(会话ID、租户ID、时间戳等)、业务上下文(用户意图、实体槽位、对话历史)与模型运行时状态(注意力缓存、KV-Cache)三层。会话元数据采用Redis集群存储,利用其高吞吐与低延迟特性支撑百万级并发访问;业务上下文写入分布式文档数据库MongoDB,通过TTL索引自动清理过期会话,存储成本降低60%;模型运行时状态则留在GPU显存中,通过PagedAttention技术实现动态内存管理,将显存碎片率从35%压缩至5%以下。更关键的突破在于状态快照与延迟加载机制:当会话空闲超过30秒,系统将显存中的KV-Cache序列化后转存至NVMe SSD,释放GPU资源;新请求到达时通过Rapid Resume技术在50ms内完成状态恢复。字节跳动的实践表明,该机制使其GPU集群的日活会话承载量提升3.2倍,同时保持P95延迟在300ms以内。
3.2 模型服务的异构部署与动态路由
大语言模型推理对计算资源的需求呈现显著异构性:7B参数模型可在单卡A10上实现50ms的首token延迟,而70B模型需要8卡A100并行推理,延迟仍达500ms以上。统一调度这些异构资源需要模型服务网格(Model Service Mesh)架构。该架构在Kubernetes之上构建专用调度层,将不同规格的模型服务封装为标准化模型端点(Model Endpoint),每个端点暴露其性能指标:TTFT(Time To First Token)、TPOT(Time Per Output Token)、并发容量等。当Router收到请求时,模型路由器(Model Router) 根据租户的SLA等级、请求复杂度(输入长度、期望输出长度)与实时负载,动态选择最优端点。对于简单查询,路由至轻量级模型实现快速响应;对于复杂推理,则调度至大参数模型保证答案质量。更智能的模型级联(Model Cascade)策略在单一请求内组合多个模型:先用1B小模型生成草稿,再用70B大模型校验与优化,在保证质量的同时将推理成本降低58%。这种异构动态路由架构的复杂性在于状态一致性保障:不同模型生成的token需无缝拼接,且需维护统一的上下文窗口。实践中通过前缀缓存(Prefix Cache)共享机制,将大模型的前缀计算结果缓存并供小模型复用,避免了重复计算,使级联效率提升40%。
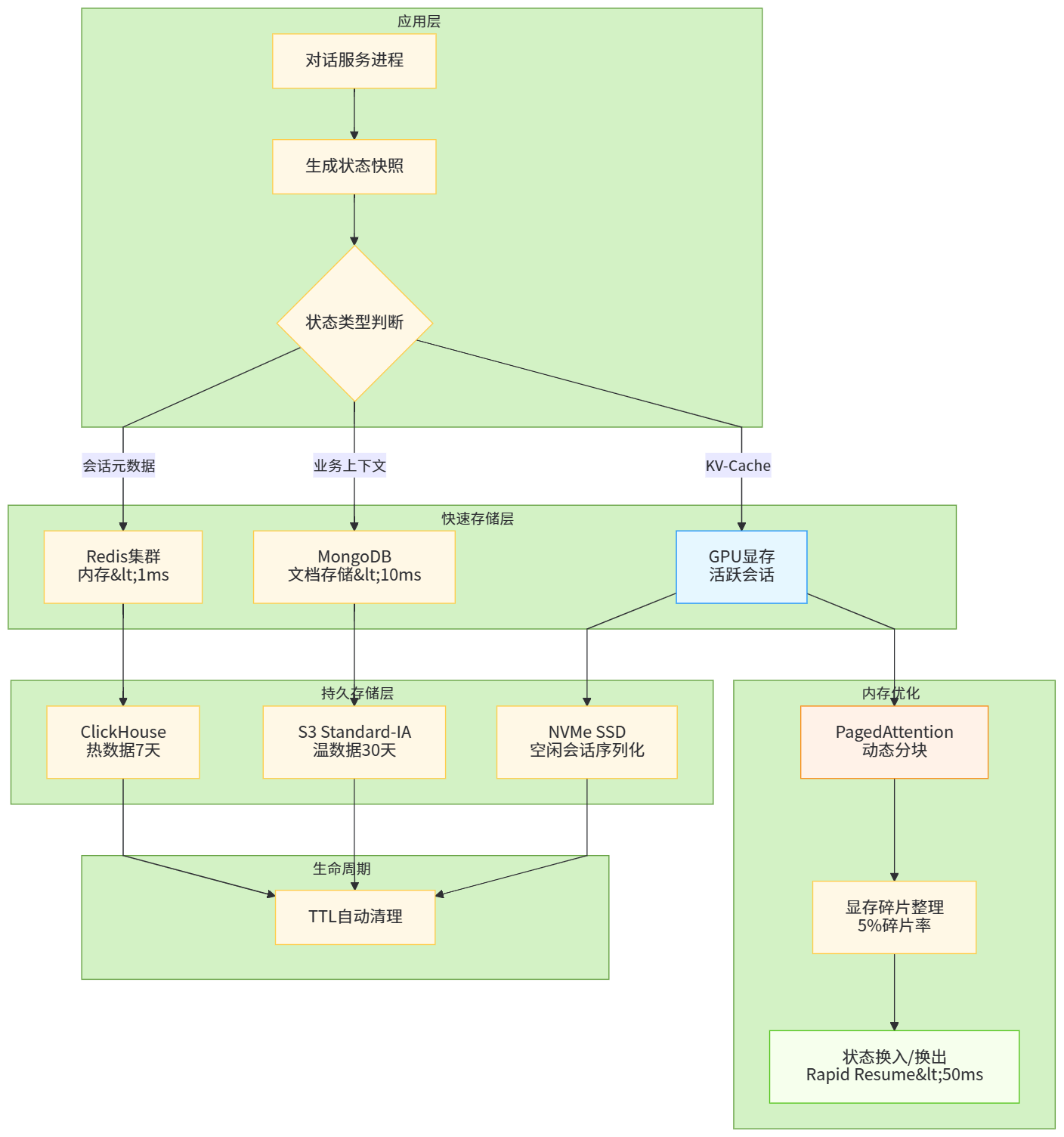
图4:对话状态分层存储架构与PagedAttention内存管理示意图
四、数据层设计:分布式存储与缓存策略的深度协同
4.1 对话日志的冷热分层与实时分析
对话日志是优化模型、分析用户行为、满足合规审计的宝贵资产,但其存储成本与查询效率构成尖锐矛盾。单一租户日均产生千万条对话记录,每条包含输入、输出、延迟、模型版本、租户标签等30+字段,原始数据量达数百GB。全量存储在SSD上成本高昂,而转存至对象存储又导致查询延迟无法接受。冷热分层架构通过时间维度+业务价值双维度进行数据分类:最近7天的热数据存储在ClickHouse集群,利用其列式存储与向量化查询特性,实现复杂OLAP查询的秒级返回;7-30天的温数据迁移至S3 Standard-IA,查询延迟控制在10秒内;超过30天的冷数据压缩后存入S3 Glacier,仅用于合规审计,查询延迟可接受分钟级。更关键的是实时分析管道的构建:通过Flink流处理引擎实时解析对话日志,提取意图分布、情感倾向、模型幻觉等指标,写入Redis作为实时看板数据,同时将特征向量写入向量数据库Milvus,支撑相似问题聚类与根因分析。某头部电商的实践显示,该架构使其日志存储成本降低73%,而实时问题发现率从12%提升至89%,因为系统能在用户投诉前识别出模型回答偏差。
4.2 知识库的向量检索与缓存优化
RAG(检索增强生成)已成为对话机器人的标准范式,其性能瓶颈在于向量检索延迟。Faiss、HNSW等近似最近邻算法虽将检索延迟优化至5-10ms,但在百万级知识库面前,单次检索仍需数十毫秒,且GPU索引构建成本高昂。分片缓存(Shard Cache)架构将知识库按租户业务域切分为多个向量索引分片,每个分片加载到独立的GPU实例。当请求到达时,Router根据租户ID与问题分类,精准路由至对应分片,避免全库扫描。更进一步,查询感知缓存(Query-Aware Cache) 通过分析历史查询模式,将高频问题对应的检索结果缓存至Redis。实验表明,约15%的查询覆盖了80%的访问量,缓存这些热点可使平均检索延迟从45ms降至3ms。缓存策略的难点在于** freshness 与命中率的权衡:知识库更新后,缓存失效可能引发大量缓存穿透。采用增量更新+版本路由**机制,新数据写入时同时更新向量索引与缓存,但老缓存保留5分钟,Router根据请求的"数据新鲜度"偏好选择路由至新数据或缓存,在一致性与性能间取得平衡。
表3:对话数据冷热分层存储方案技术对比
| 数据层级 | 存储介质 | 保留周期 | 查询延迟 | 单位成本 | 核心技术 | 应用场景 |
|---|---|---|---|---|---|---|
| 热数据层 | ClickHouse+SSD | 0-7天 | <1秒 | 高($0.1/GB/月) | 列式存储、向量化执行 | 实时监控、问题诊断 |
| 温数据层 | S3 Standard-IA | 7-30天 | 5-10秒 | 中($0.0125/GB/月) | 对象存储、批量查询 | 业务分析、质量评估 |
| 冷数据层 | S3 Glacier Deep Archive | >30天 | 分钟级 | 极低($0.00099/GB/月) | 压缩归档、延迟检索 | 合规审计、法律取证 |
| 实时特征 | Redis+Milvus | 动态更新 | <100ms | 高(内存成本) | 流处理、向量检索 | 意图聚类、根因分析 |
五、安全与合规:多租户场景下的数据主权保障
5.1 端到端加密与密钥管理
多租户架构中,数据泄露的后果是灾难性的,因为单一漏洞可能影响数千个租户。传输层TLS 1.3加密已是基础要求,但存储加密与内存加密才是新的挑战。应用层字段级加密在网关层对敏感字段(身份证号、银行卡号)进行加密后再存入数据库,解密仅在需要展示的最终用户客户端完成,即使数据库被拖库也无法还原明文。密钥管理采用租户主密钥(Tenant Master Key, TMK)体系,每个租户拥有独立的KMS密钥,TMK不存储在应用服务器,而是托管在硬件安全模块(HSM)或云KMS服务。当模型需要处理加密字段时,通过安全多方计算(MPC)或同态加密技术在密文域完成推理,虽性能开销增加3-5倍,但满足金融级合规要求。更务实的方案是差分隐私保护:在训练数据中加入校准噪声,使模型无法记住单个租户的具体信息,同时保持整体性能。研究表明,当噪声参数ε=1时,模型在保持98%准确率的同时,成员推断攻击成功率从65%降至5%以下。
5.2 审计追踪与合规自动化
GDPR、CCPA等法规要求企业能提供完整的数据处理记录。传统审计依赖日志归集,存在篡改风险且难以跨系统关联。区块链增强审计日志将关键操作(数据访问、模型调用、权限变更)的哈希值实时写入区块链,利用其不可篡改特性保证审计可信度。同时,合规策略即代码(Compliance as Code)将法规要求转化为可执行的策略规则,嵌入到CI/CD流水线。例如,当开发者提交代码访问用户对话日志时,自动触发策略引擎检查是否满足"最小必要原则",若代码尝试提取全量日志而非脱敏样本,则自动阻断合并请求。某跨国企业部署该系统后,合规审计准备时间从3周缩短至2天,且审计发现的问题数量减少90%。更深层的创新在于AI合规助手:利用大模型自动解析法规文本(如GDPR第32条),生成对应的代码检查规则与配置模板,将法律语言转化为技术实现,极大降低了合规门槛。
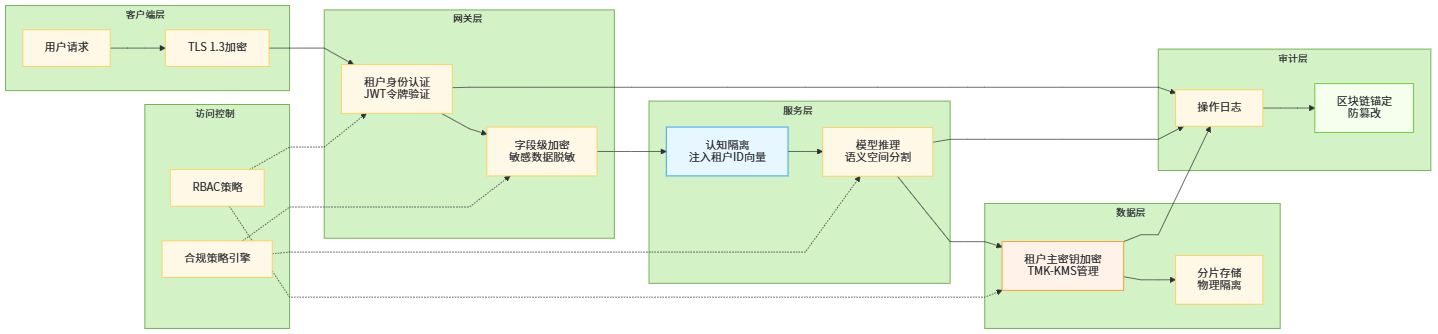
图5:端到端安全架构与租户隔离机制
六、成本优化:从资源浪费到精细化运营
6.1 GPU共享与混部技术
GPU是对话服务中最昂贵的资源,其利用率直接决定运营成本。传统部署模式下,GPU资源按峰值预留,平均利用率不足30%。MIG(Multi-Instance GPU)技术将物理GPU划分为最多7个独立实例,每个实例拥有专属的计算单元与显存,实现硬件级隔离。配合Kubernetes的Device Plugin机制,可为不同租户分配不同规格的GPU切片,例如将A100的40GB显存拆分为7个5GB实例,分别服务7个中小型租户,资源利用率提升至65%。更激进的时间共享(Temporal Sharing)允许超售:将多个低负载租户的请求调度至同一GPU实例,通过抢占式调度保证响应延迟。当检测到延迟超过SLA阈值时,立即将部分请求迁移至备用实例。该策略使GPU利用率提升至85%,但需强大的预测与调度能力以避免质量劣化。字节跳动的实践表明,结合预测性迁移的时间共享,可在保证P99延迟<200ms的前提下,将GPU成本降低52%。
6.2 模型量化与投机推理
模型压缩是降低计算成本的另一路径。INT8量化将权重与激活值从FP16压缩至INT8,模型体积减半,推理速度提升2-3倍,但需警惕精度损失。最新进展是混合精度量化:对注意力层等关键模块保持FP16,对全连接层使用INT4,在精度损失<2%的前提下实现3.5倍加速。投机推理(Speculative Inference)则通过小模型生成候选token序列,大模型并行验证,将自回归生成的串行延迟转化为并行计算。实验证明,在代码生成场景,投机推理使TTFT降低40%,总吞吐量提升2.1倍。成本优化的终极形态是租户价值导向的差异化服务:为高价值租户分配FP16模型保证最佳体验,为免费试用租户使用INT4量化模型并限制并发,通过服务分级实现成本与收益的最优匹配。
表4:成本优化技术方案效果对比
| 优化技术 | 实现复杂度 | GPU利用率提升 | 延迟影响 | 精度损失 | 适用规模 | 成本节约 |
|---|---|---|---|---|---|---|
| MIG实例切分 | 中 | +35% | 无 | 无 | 中型平台 | 30-40% |
| 时间共享混部 | 高 | +55% | 可控 | 无 | 大型平台 | 50-60% |
| INT8量化 | 低 | +100% | -15% | <1% | 全规模 | 40-50% |
| 投机推理 | 高 | +110% | -40% | 无 | 大模型场景 | 35-45% |
| 服务分级 | 中 | +25% | 差异化 | 无 | 商业化平台 | 20-30% |
七、未来演进:从云原生到AI原生的架构跃迁
7.1 Serverless化与边缘计算融合
Serverless架构将资源管理完全托管,开发者只需关注业务逻辑。对话服务的Serverless化面临冷启动延迟与状态恢复两大挑战。预留实例+快照恢复是折中方案:为每个租户预留一个最小实例(0.1vCPU/128MB内存),当请求到达时通过CRaC(Coordinated Restore at Checkpoint)技术在50ms内扩容至目标规格。AWS Lambda SnapStart的实践表明,该技术使Java函数的冷启动从1秒降至200ms以内,但其对GPU状态的支持仍在探索中。边缘计算则将推理能力下沉至离用户最近的节点,降低网络延迟。联邦推理架构中,中心云训练全局模型,边缘节点基于本地数据微调并服务周边用户,仅将梯度与关键日志回传云端。Cloudflare的Workers AI已实现边缘节点部署7B模型,使全球用户的平均延迟降至50ms以内。这种模式对对话机器人的挑战在于知识同步:边缘节点的知识库更新需实时同步,否则导致不同区域用户获得不一致答案。采用CRDT(无冲突复制数据类型)管理知识库版本,可实现最终一致性,但增加系统复杂度。
7.2 认知智能驱动的自主架构优化
当大模型能力从对话生成延伸至系统运维,AI开始自主优化架构。AI架构师通过分析历史监控数据,自动生成资源配置建议。例如,发现某租户在每周一上午9点流量激增3倍,AI自动创建CronJob在8:30预热资源,并在10:00后释放,实现无人值守的弹性伸缩。更深层的优化是架构自进化:AI通过强化学习探索新的调度策略,如发现现有负载均衡算法在某些租户组合下效率低下,自动提出改进方案并A/B测试,验证有效后合并至主干。Meta的Hammer系统已实现部分自优化能力,使集群资源效率提升18%。对话机器人架构的终局可能是认知弹性架构:系统不仅根据负载伸缩,更根据对话内容的认知复杂度动态调整——简单FAQ路由至小模型,深度咨询调用大模型,且在对话过程中实时切换,实现资源消耗与任务难度的最佳匹配。这种架构需要模型具备自我评估能力,能实时判断当前生成质量是否满足需求,从而触发模型升级或降级。
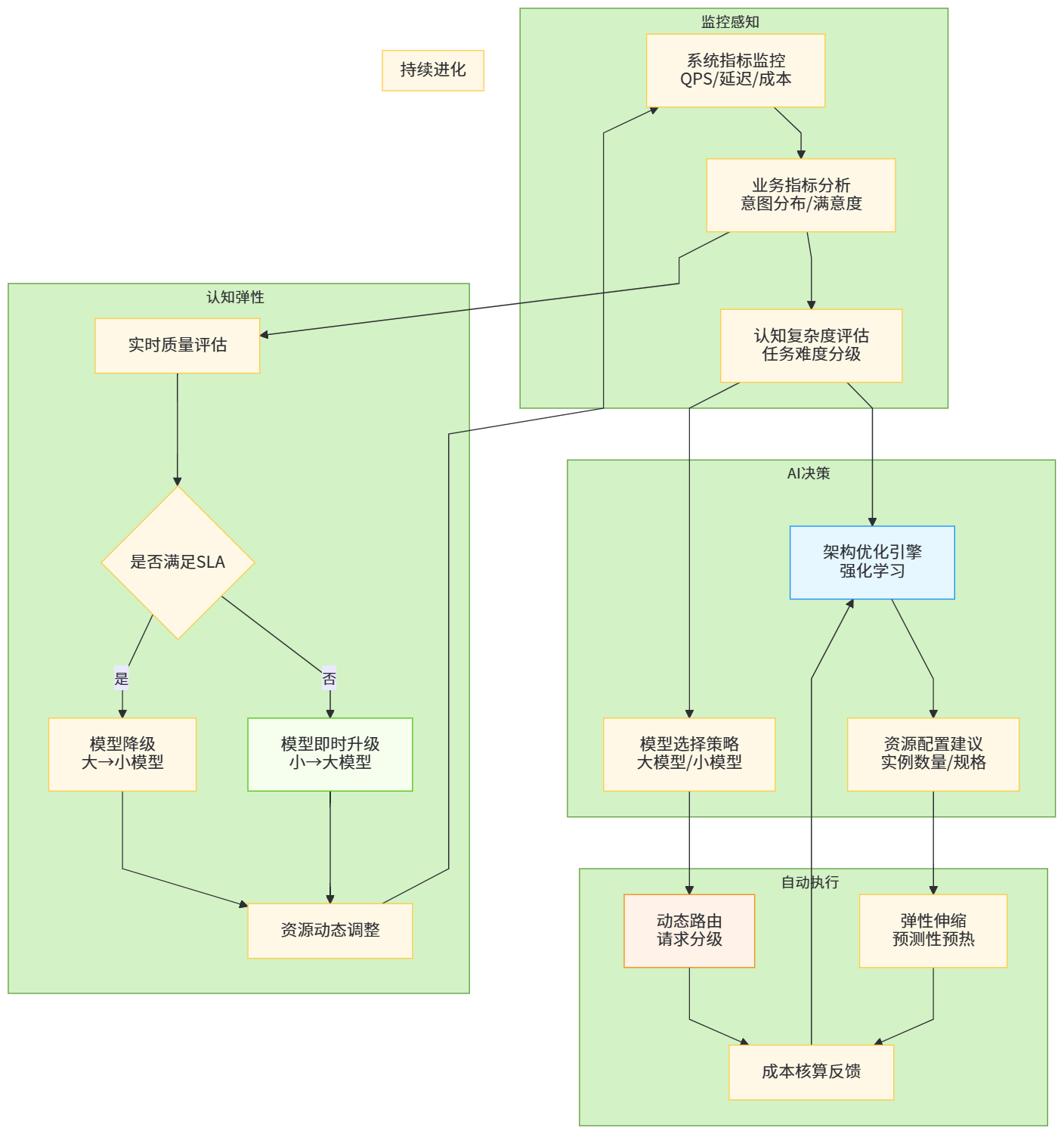
图6:未来AI原生对话架构的自主演进与认知弹性机制
结论:构建下一代对话基础设施的方法论
对话机器人的基础设施化转型,要求架构设计从单一性能优化转向系统性能力构建。本文系统论证了多租户隔离的认知化演进、接入层的智能流量调度、服务层的无状态化与异构部署、数据层的冷热分层与向量化检索、安全的端到端加密与合规自动化、成本的精细化运营以及未来的AI原生架构演进。核心发现是,高并发多租户架构的成功依赖于 "三个一体化" :软硬件一体化,通过GPU共享与显存优化挖掘硬件潜力;算法系统一体化,将模型能力融入调度、缓存、安全各环节;人机协同一体化,用AI增强而非替代人类专家的判断。这些原则共同构成下一代对话基础设施的设计方法论。
然而,技术演进永无止境。当前架构仍面临模型幻觉导致的不可预测性、对抗攻击下的鲁棒性缺失、以及跨租户知识迁移的版权争议等深层挑战。解决这些问题需要架构、算法与治理的协同创新。对架构师而言,建议采取"分阶段演进"策略:短期聚焦GPU利用率与延迟优化,中期构建智能化调度与自愈能力,长期探索自主架构与认知弹性。对开发者,应深入理解LLM的运行时特性,将架构设计从"面向服务"升级为"面向认知任务"。对决策者,需平衡技术投入与商业回报,认识到对话基础设施的竞争力不仅在于功能丰富度,更在于单位请求成本、弹性响应速度与合规可信度。
当对话机器人真正成为数字社会的基础设施,其架构设计将影响数十亿用户的日常交互体验。这不仅是技术挑战,更是社会责任。唯有坚持安全可控、高效普惠、持续进化的设计哲学,方能在智能时代构建起值得信赖的对话基础设施。
参考资料
博客园. AI的双刃剑:对抗性机器学习与AI驱动安全的攻防前沿. 2025-09-03. https://blog.youkuaiyun.com/m0_71322636/article/details/151156186
哈尔滨工程大学. 人工智能大模型驱动的网络安全防御体系智能化演进路径. 网络空间安全科学学报, 2025. https://cccf.hrbeu.edu.cn/cn/article/pdf/preview/10.11991/cccf.202506006.pdf
安全内参. AI大脑如何被"套路"?揭秘大模型提示词攻防. 2025-05-23. https://www.secrss.com/articles/79050
UK AI Security Institute. Countering Autonomous Cyber Threats: Assessing the Risks of Downloadable Offensive Agents. arXiv:2410.18312, 2024. https://arxiv.org/pdf/2410.18312
Zhu, H., et al. A Roadmap for Big Models: Perspectives on Reliability, Security, and Privacy. arXiv:2203.14101v1, 2022. https://arxiv.org/pdf/2203.14101v1
腾讯新闻. AI攻防新态势:大模型成漏洞挖掘"双刃剑". 2025-11-23. https://news.qq.com/rain/a/20251123A0251P00
娜璋AI安全之家. 基于大模型的威胁情报分析与知识图谱构建论文总结. 2025-06-04. http://mp.weixin.qq.com/s?__biz=Mzg5MTM5ODU2Mg==&mid=2247501812&idx=1&sn=e9a76f92ac90709cb30ad782df93aeb3
优快云. 如何利用大模型进行安全攻防:内附多个应用案例. 2024-06-27. https://www.bing.com/ck/a?!=&fclid=3478b0ae-1f48-6c63-2168-a4021e666d36&hsh=3&ntb=1&p=27a6561391e99309JmltdHM9MTcxOTQ2NjQwMCZpZ3VpZD0zNDc4YjBhZS0xZjQ4LTZjNjMtMjE2OC1hNDAyMWU2NjZkMzYmaW5zaWQ9NTIyNQ&ptn=3&u=a1aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3plbmd6aXppL2FydGljbGUvZGV0YWlscy8xMzc1MjAyODA&ver=2
爱代码爱编程. 如何利用大模型进行安全攻防:内附多个应用案例. 2024-04-10. https://icode.best/i/705400387519773
知乎专栏. 智能会话机器人:SaaS 平台的设计与思考. 2025-08-03. https://zhuanlan.zhihu.com/p/370538744
HYPERS. 如何构建一个高可用、高并发的AI智能客服系统?. 2025-05-30. https://www.hypers.com/content/archives/10208
腾讯云. 智能会话机器人:SaaS 平台的设计与思考. 2021-05-08. https://cloud.tencent.com/developer/news/821878
Google专利. 一种基于多租户的对话模型交互方法、装置及存储介质. CN116881429A, 2023-09-07. https://patents.google.com/patent/CN116881429A/zh
Google专利. 一种基于多租户的对话模型交互方法、装置及存储介质. CN116881429B, 2023-09-07. https://patents.google.com/patent/CN116881429B/zh
优快云博客. 智能对话引擎负载均衡设计:AI架构师的多实例部署与流量调度策略优化. 2025-08-09. https://blog.youkuaiyun.com/weixin_51960949/article/details/150108013


















 844
844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











