



面向大规模无线传感器网络的带中断支持的流水线RV32IMC处理器设计与实现
摘要
随着物联网(IoT)及其众多应用的兴起,无线传感器网络中的传感器节点能力不断提升,因为大量感知数据导致网络核心承担显著的工作负载。因此,将计算任务从网络核心转移到网络边缘的边缘计算应用变得越来越广泛。本文提出了一种支持中断的流水线式 RISC‐V RV32IMC 处理器,以应对这一挑战。该处理器支持 I2C、SPI 和 UART 协议,用于与外设通信。通过设计优化、延迟平衡和时钟门控等优化措施,核心处理器的最大工作频率提升了 13.3%,动态功耗降低了 23.3%。在基于 Xilinx Artix‐7 FPGA 的 Digilent Arty A7 开发板上,该已实现的处理器在 50兆赫 的工作频率下运行,平均核心功耗为 30.752 毫瓦。
索引术语
RISC‐V,无线传感器网络,物联网,现场可编程门阵列,流水线
一、引言
无线传感器网络(WSN)是一组空间分布的自主传感器节点,应用于环境监测、工业过程控制和医疗监控等领域[1],[2]。大多数无线传感器网络采用商用现成的微控制器单元(MCU),因其成本低且功耗低,这些微控制器单元内置处理器用于传感器节点[3]。除了 MCU之外,片上系统(SoC)也因高性能和低功耗而在无线传感器网络中得到广泛应用。然而,这两种实现方式均存在一些局限性,例如微控制器单元(MCU)处理能力有限[3]以及片上系统(SoC)配置固定[4]。
由于这些设计存在限制,目前正考虑采用具有软硬件灵活性的基于FPGA的设计。文献[5]中的一种基于 FPGA的无线传感器节点在数据包传输、接收和中继方面的系统效率均高于传统的Mica2和SNAP无线传感器节点。
需要注意的是,与片上系统(SoC)和微控制器单元 (MCU)实现相比,基于FPGA的设计功耗更高。然而,由于其具备快速原型开发、动态重构和处理加速等优势,基于FPGA的设计在广泛的物联网应用中具有优势。
此外,随着物联网的发展,由于连接设备数量的增加,无线传感器网络收集的数据量也将随之增长。大量感知到的数据会给网络核心[6]带来显著的工作负载,并可能导致网络网关[7]出现瓶颈。因此,近年来网络边缘的处理能力不断提升,一些应用包括大规模环境感知、智慧城市和分布式机器学习[1],[8]。网络边缘能力的提升带来了诸多优势,例如更短的数据包长度和更少的发送数据包[9],、降低的网络使用量和总能耗[10],,以及相较于传统云计算更短的传输时间和更快的处理速度[11]。
日益增强的边缘计算能力的出现,带来了提升无线传感器节点处理能力的挑战,同时还需要最大化节点本身有限的资源。然而,许多无线传感器节点仍在使用一些实现方式,可能无法满足各类物联网应用的需求,也不足以灵活支持增强的计算能力。因此,本文提出了一种基于FPGA的处理器,具备可用于无线传感器节点多种物联网应用的计算能力。
本文的结构如下:第二节讨论了RV32IMC处理器的设计与实现细节以及集成的通信协议。第三节给出了结果与分析。最后,第四节对全文进行总结,并提出了对未来工作的建议。
II. 支持中断和通信协议的RV32IMC处理器
A. 具有中断支持的RV32IMC处理器
取指阶段包含指令存储器和程序计数器(PC)模块。该阶段负责生成正确的程序计数器,以确定将从指令存储器中读取的指令,并将其发送到取指/译码流水线寄存器。指令存储器已实现为半字寻址,因此程序计数器根据指令类型递增2或4。
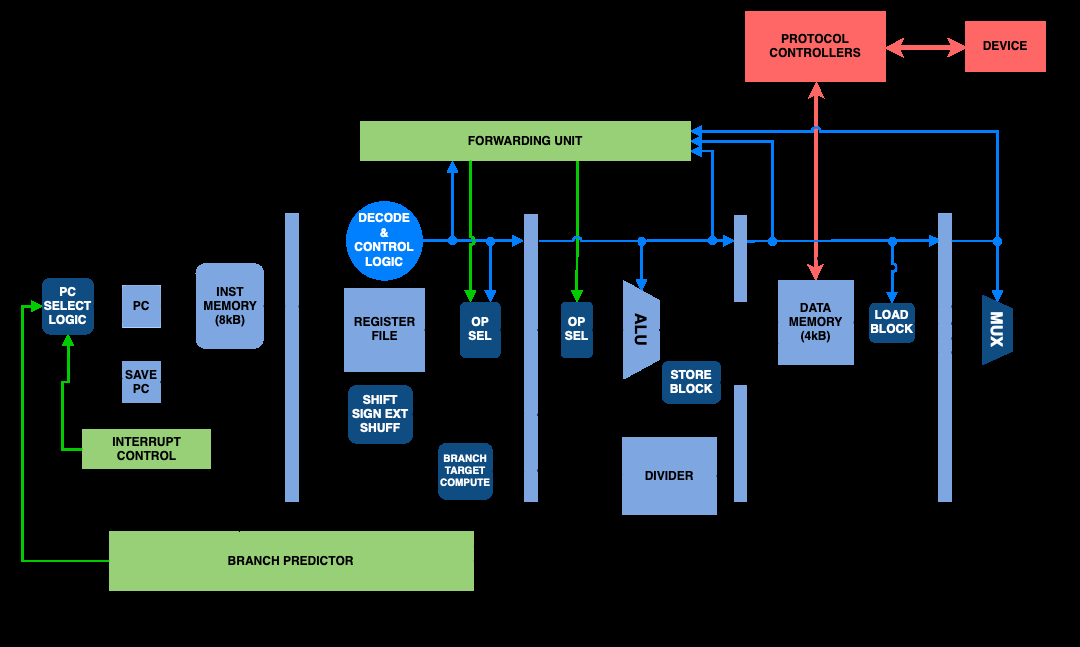
是否被压缩。当中断被检测到时,通过在此阶段将第一条未完成指令的程序计数器地址保存到保存PC寄存器中来处理中断。当中前流水线中所有正在执行的指令完成后,将执行中断服务程序(ISR)。ISR的指令已预加载到ISR指令存储器中。
译码阶段(ID stage)生成来自取指/译码流水线寄存器的指定指令的控制信号、立即数和寄存器文件地址。在此阶段,包含寄存器文件(RF)、移位、符号扩展和混洗模块以及控制单元。寄存器文件包含31个通用寄存器和一个根据[12]规定固定为0的寄存器。尚未保存在分支历史表(BHT)中的分支指令及其分支目标地址也在此阶段被保存,已保存的分支指令将被忽略。
在执行阶段,算术逻辑单元(ALU)负责处理除除法以外的所有算术运算。除法指令由除法模块处理,并以38‐46个周期延迟执行。当除法操作在执行阶段执行时,流水线停顿,直到除法操作完成。该阶段还包含一个存储模块,用于格式化将在下一阶段存入数据存储器的数据。ALU在此阶段还执行分支比较,并将结果传递给分支历史表(BHT),以判断预测是否正确,并相应地更新分支历史表。
访存阶段包含数据存储器和加载模块,后者根据所使用的加载指令对获取的数据进行格式化。所有内存访问(无论是读取还是写入)都在此阶段发生。
写回阶段是使用新数据更新寄存器文件的阶段。该阶段包含一个多路复用器,用于选择要存储到寄存器文件中的数据。
多条指令在内部同时执行
在流水线中,已实现冒险处理措施。设计中实现了前递单元,以解决后续指令之间可能存在的数据依赖。前递单元可以立即将所需数据共享给相应指令,而无需等待先前指令完成后再访问所需数据。为了处理控制冒险,已实现双模分支预测,这是一种动态分支预测,使用带有2位饱和计数器的分支历史表(BHT),通过跟踪之前的结果来改进未来的分支预测。
B. 设计优化
在RV32IMC处理器中采用了两种设计优化:用于功耗降低的时钟门控和用于进一步减少关键路径延迟的延迟平衡。这些优化降低了处理器对时钟抖动的敏感性,并提高了处理器的最高频率,以满足可能需要更高性能的应用需求。
1) 时钟门控:
当某个特定阶段未处于活跃指令处理状态时,采用时钟门控以降低功耗。流水线停顿、冲刷和空操作均会导致此类非活跃情况。所采用的时钟门控方案如图2所示。主时钟及其对应的使能信号作为带时钟使能的全局时钟缓冲器(BUFGCE)的输入,以生成门控时钟。这些门控时钟随后传递给相应的流水线寄存器,作为其时钟信号。
2) 延迟平衡:
延迟平衡包括在各个阶段之间移动逻辑结构,以最小化最差阶段的关键路径。在各阶段之间移动逻辑结构可最小化各阶段的空闲时间,从而提高最大工作频率。
已启用Vivado的重定时选项来实现此目的。然而,该重定时选项并不能保证达到最佳改进效果,因为Vivado仍然被迫遵守Verilog代码,并使最终产品表现类似。因此,还会检查所有可能的关键路径,以确定是否可以进行调整来缩短这些路径。
C. 通信协议实现
由于节点中的资源有限,传感器节点还需要采用快速且节能的数据传输方式。尽管通过并行总线进行通信比串行传输更快,但它需要多得多的连接线。因此,由于节点的实际尺寸限制了系统总线的使用[15],节点设计中从不支持并行总线。这导致选择了集成电路间通信 (I2C)和串行外设接口(SPI)等串行接口作为已实现的通信协议。尽管通用异步收发器(UART)不是一种串行接口,但由于其使用串行数据通信,也已被实现。
1) 内部集成电路(I2C):
采用Forencich的代码[16],,其中包含三个先进先出(FIFO)寄存器、一个三态缓冲器以及各种内部寄存器,用于实现I2C主模块。设计了一个控制器以实现该I2C主模块与主处理器之间的通信。图 3展示了已实现的I2C主模块的框图,其中显示了重要的寄存器和控制器。
控制器负责确定操作并生成相应的信号。控制器从处理器的数据存储块接收要发送的数据(如果有)以及操作类型,无论是读取、写入还是设置预分频。根据这些信息,控制器随后进行设置

模块中存在的相应内部寄存器以启动操作。
内部寄存器随后会将相应的命令或数据推送到写 FIFO、读FIFO和命令FIFO中。写FIFO从数据寄存器接收数据,并将接收到的数据传递给从设备。同时,读 FIFO存储从从设备接收到的数据,并将这些数据传递给数据寄存器,供主模块读取。而命令FIFO则用于存放来自命令寄存器的命令,等待执行。
2) 串行外设接口(SPI):
已实现的SPI模块改编自 [17],最多可支持四个从设备。每个从设备都有其对应的从设备选择线,该线以低电平触发有效。SPI模块还支持四种操作模式,通过时钟极性(Clock Polarity)和时钟相位(Clock Phase)控制信号来决定数据在何时被采样和移位。该SPI模块限制每次事务中仅能从主设备向从设备传输2字节,从从设备向主设备传输1字节。
3) 通用异步收发器(UART):
用于UART的模块是[17]中所用实现的修改版本。这些模块操作的数据流由一个起始位、八个数据位、一个可选的奇偶校验位以及最多两个停止位组成。
解码模块从外围设备接收数据,检查所接收数据的奇偶校验位,对所有接收到的数据进行解码,并将并行数据转发给处理器。同时,编码模块使用可存储最多16 字节数据的FIFO发送缓冲区,以支持传输多个字节的数据。需要每次传输多个字节数据的UART设备可用于与处理器通信。
D. 系统集成
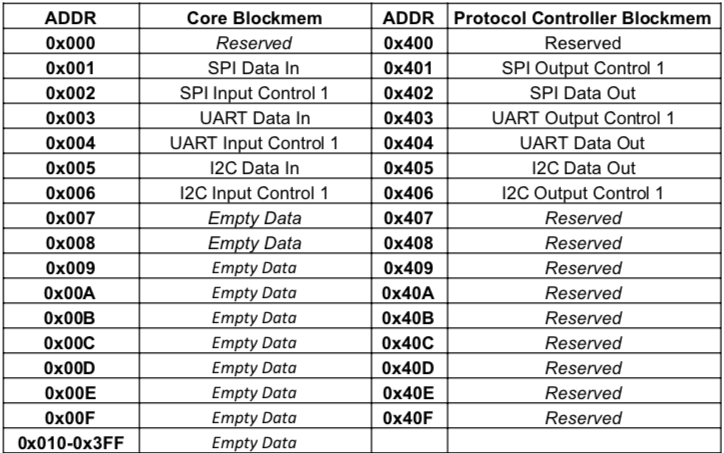
[17]中的存储器接口经过调整,以将协议控制器与处理器集成,如图4所示。该接口通过循环映射的内存地址,使核心处理器和协议控制器能够相互读写。
采用内存映射来访问每个协议控制器的状态寄存器和数据。图5显示了数据存储器结构。字对齐地址 0x007到0x3FF分配给核心处理器使用,而其余地址则分配给协议控制器使用。选定的地址用于各种通信协议的数据输入、数据
输出、输入控制和输出控制,以促进各种通信协议与核心处理器之间的通信。
三、结果与分析
A. 分析设置
为了验证功能,运行了一段包含所有支持指令的汇编代码,并将内存内容与预定义答案键进行核对。在验证中断支持功能时,编写了一段汇编代码,使得按下 FPGA开发板上的按钮时,开发板上的LED灯会亮起,并在处理器中运行该代码。
该处理器已在Xilinx Artix‐7 FPGA上实现,以评估其功耗、时序和FPGA资源利用率。为了进行公平比较,在所有综合和实现运行中,时钟管理器、IP模块和报告策略等因素均设置相同。
为了确定所引入的设计优化带来的改进,考虑了两个测试用例进行功耗及时序评估。第一种情况是支持中断、压缩指令以及乘法和除法指令的设计。这被称为基础设计,将作为比较的基础。第二种情况是优化设计,即在基础设计上应用了时钟门控和延迟平衡。
最终设计迭代中的协议控制器以及中断使用图6所示的设置进行了测试。通过编写名为demo.s的RISC‐V汇编代码来评估与ESP8266模块、Arduino UNO和I2C LCD的通信情况。
通过Vivado生成的仿真活动文件用于对最终设计进行更精确的功耗分析。使用了一段包含所有支持的算术指令混合的RISC‐V汇编代码,命名为mixed test.s,以确定不同输入序列是否会导致功耗变化。实现了设计的多个实例,以观察不同的负载和布线寄生参数是否影响处理器的功耗。
B. 设计优化改进
为了确定设计在功耗方面的可能改进,需对设计的功耗进行
表I 基础与优化处理器的功耗比较
| Base | 优化 | 降低百分比 | |
|---|---|---|---|
| 核心动态功耗 | 44.86 毫瓦 | 34.42 毫瓦 | 23.3% |
| 静态功耗 | 62.08 毫瓦 | 58.7 毫瓦 | 5.4% |
| MMCM功耗 | 94.395 毫瓦 | 94.395 毫瓦 | 0% |
| 总功耗 | 106.94 毫瓦 | 93.12 毫瓦 | 12.9% |
基础设计与优化设计的结果如表I所示。采用时钟门控技术使得优化设计的核心动态功耗降低了23.3%,而混合模式时钟管理器(MMCM)的功耗以及整个现场可编程门阵列(FPGA)的静态功耗几乎保持不变。由于仅需考虑设计本身的功耗,总功耗数值未包含MMCM或时钟功耗。
从Vivado的时序汇总中考虑两个参数,以从时序角度分析设计的性能。第一个是最差负时隙(WNS),它表示在目标频率下数据能够被安全采样的剩余时间;第二个是最差保持时隙(WHS),它表示设计所能容忍的保持时间变化量。
表II 基础处理器与优化处理器的时序摘要
| Base | 优化 | |
|---|---|---|
| WNS | 1.477 纳秒 | 3.655 纳秒 |
| WHS | 0.022 纳秒 | 0.051 纳秒 |
| fmax | 53.987 兆赫兹 | 61.181 兆赫兹 |
表II中的时序汇总显示了设计两次迭代的时序裕量。时序裕量的正值表明已实现设计的所有时序路径均满足设定的所有约束条件。与基础设计相比,延迟平衡使处理器的最差负时序裕量(WNS)提高了147.5%,最差保持时序裕量(WHS)提高了131.8%,最高频率(fmax)提升了13.3%。
C. 最终设计结果
表III 最终处理器核心动态功耗汇总
| 最小值 | 平均值 | 最大值 | |
|---|---|---|---|
| demo.s | 28.067 毫瓦 | 28.875 毫瓦 | — |
| mixed test.s | 32.171 毫瓦 | 32.631 毫瓦 | 33.349 毫瓦 |
| 总体平均 | — | 30.752 毫瓦 | — |
该处理器的最终实现具有3.119纳秒的最差负时序裕量、0.05 纳秒的最差保持时序裕量,以及最大可达59.238兆赫兹的频率。
将本设计与[17]的设计进行比较以评估该设计的 FPGA资源利用率,因为[17]的设计也已在Xilinx Artix‐7 FPGA上实现,并作为本项目开发的基础。从表 IV可以看出,
表IV RV32IC处理器与最终处理器核心的FPGA资源利用率
| RV32IC(单周期)[17] | RV32IMC | |
|---|---|---|
| LUT | 6241 | 5548 |
| LUTRAM | 88 | 28 |
| FF | 1953 | 5670 |
由于已实现的协议控制器占用面积更小,以及处理器中移除了压缩指令缓冲区,因此所使用的查找表(LUT)数量有所减少。由于使用了块存储器,用作RAM的 LUT数量也减少了。另一个值得注意的是,由于实现了流水线设计中的四个中间流水线寄存器,所使用的触发器(FF)数量显著增加。
D. 与现有工作的比较
表V 规格列表
| RESE2NSE 节点 2[18] | 单周期RV32IC [17] | 已实现处理器 | |
|---|---|---|---|
| 架构 | 32位ARM | RV32IC | RV32IMC |
| 技术 | ATSAMR21 SoC | 赛灵思 Artix‐7 FPGA | 赛灵思 Artix‐7 FPGA |
| 频率 | 50兆赫 | 12.5兆赫 | 50兆赫 |
| 内存 | 256千字节 | 4.5千字节 | 12千字节 |
| 电源 | 3.3伏特 | 5 V | 5 V |
| 核心功率 | 758 µW | 31毫瓦 | 30.752毫瓦a |
| 分支预测 | - | - | 双模分支预测 64个条目 4路组相联 |
| 中断 | Yes | No | Yes |
更大的内存容量使得需要更多内存的大型程序能够在设备上运行。因此,尽管内存的目标大小为4.5千字节,但已实现的内存大小为12千字节。这12千字节由4 kB数据存储器、4 kB指令存储器和4 kB中断服务例程内存组成。正如预期的那样,由于该项目在现场可编程门阵列上实现以及处理器的流水线设计,其功耗高于现有节点。
分支预测是一项有益的改进,有助于流水线中的冒险处理。
处理器。表V中提到的现有工作未实现流水线,因此无需添加分支预测。现有工作还依赖轮询进行外部通信,因为其目标函数具有固定的通信间隔,而本已实现的处理器的目标实现涉及不同且更重的工作负载。最后,该处理器达到的工作频率等于甚至高于表中所示节点的频率。
由于需要考虑设计之间在架构、工艺技术和供电电压等方面的差异,对已实现的处理器与现有设计进行更直接和全面的比较将十分困难。
第四节 结论与建议
开发了一种支持最多1024条指令的五级流水线 RV32IMC处理器的功能模型,中断处理程序中还可容纳额外1024条指令,工作频率为50兆赫。该模型还具有功能性的中断处理机制,并支持通过I2C、SPI和UART协议进行通信。设计中实施的设计优化也被证明是有效的,因为核心动态功耗降低,最高频率提高。
未来项目可以考虑运行CoreMark等基准测试,以更有效地评估所提出设计在实际应用中的性能,并查看其是否能够与当前的传感器节点实现相竞争。其他功耗降低方案,如动态电压频率调节和自适应电压调节,也可以应用于该设计,以进一步降低处理器的功耗。然而,在这些方案得以实施之前,可能需要额外的控制逻辑和外部硬件单元,因为所使用的FPGA开发板不支持运行时的电压和频率调节。
使用FPGA实现所提出的处理器主要是出于资源限制的考虑。如前所述,选择在SoC上实现将不利于进行适当的功能演示。因此,未来的项目应考虑在SoC或微控制器单元(MCU)上实现该处理器。但是,该项目依赖于多个专有的Xilinx IP核模块,若采用SoC或MCU则需要替换这些模块。

















 5372
5372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









