



 文章讨论了在测试覆盖率低的情况下,如何通过TMAXATPG工具的remove_faults命令剔除不需要的逻辑单元,重点提到不能直接使用*号匹配,需用cellhierarchy精确匹配或使用-filter的正则表达式进行批量操作,同时强调了get_attribute在get_cells过程中的关键作用。
文章讨论了在测试覆盖率低的情况下,如何通过TMAXATPG工具的remove_faults命令剔除不需要的逻辑单元,重点提到不能直接使用*号匹配,需用cellhierarchy精确匹配或使用-filter的正则表达式进行批量操作,同时强调了get_attribute在get_cells过程中的关键作用。
跑TMAX ATPG,testcoverage很低,想把不需要ATPG测试的逻辑剔除不计算在ATPG testcoverage,通过remove_faults命令来剔除这些逻辑cell,但cell太多如何通过*号匹配批量完成?
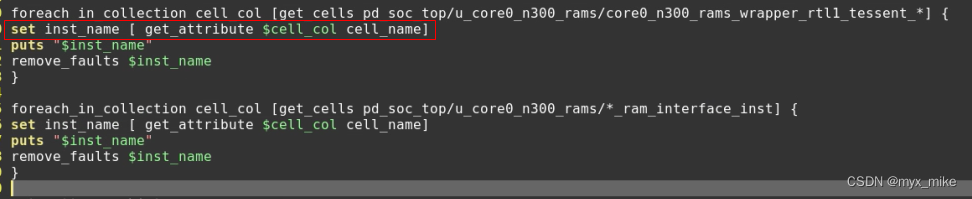
remove_faults不能直接get_cells 使用*匹配,只能通过foreach_in_collection的方式:
1. 直接带cell hierarchy 匹配,比较精准一些,不至于溢出到其他逻辑。
2. 使用-filter的正则表达式匹配,可以匹配更宽的范围
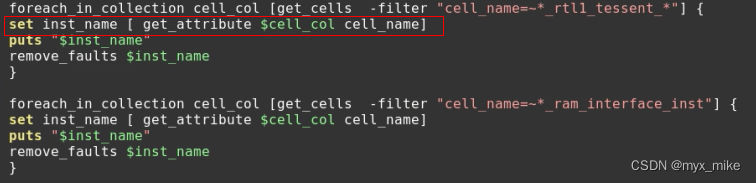
注:注意其中的get_attribute的那行,是整个get_cells的关键

















 472
472




 到【灌水乐园】发言
到【灌水乐园】发言







